目录
- Java基础
- Java集合
参考资料
- 《Java编程思想》
- 《Java Web 技术内幕》
- 《Java 并发编程实战》
- https://mp.weixin.qq.com/s/Gr8kLpM9bgocCuC-Ve_dZg
Java基础
对象
创建对象
引用
用引用(reference)操纵对象。犹如遥控器和电视机的关系。
new关键字
创建对象,并存储在堆heap中。
特例:基本类型
(1)基本类型与包装类
· 装箱过程是通过调用valueOf方法(Integer Integer.valueOf(int))实现的,拆箱为xxxValue()(int Integer.intValue())。
· Integer装箱时,在[-128, 127]之间不创建新对象,否则创建新对象。
· Integer、Short、Byte、Character、Long类似。Double、Float装箱类似,每次创建新对象。
· 当 “==”运算符的两个操作数都是 包装器类型的引用,则是比较指向的是否是同一个对象,而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。另外,对于包装器类型,equals方法并不会进行类型转换。
demo:
public class Main {
public static void main(String[] args) {
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 321;
Integer f = 321;
Long g = 3L;
Long h = 2L;
System.out.println(c==d);
System.out.println(e==f);
System.out.println(c==(a+b));
System.out.println(c.equals(a+b));
System.out.println(g==(a+b));
System.out.println(g.equals(a+b));
System.out.println(g.equals(a+h));
}
}
true false true true true false true第一个和第二个输出结果没有什么疑问。第三句由于 a+b包含了算术运算,因此会触发自动拆箱过程(会调用intValue方法),因此它们比较的是数值是否相等。而对于c.equals(a+b)会先触发自动拆箱过程,再触发自动装箱过程,也就是说a+b,会先各自调用intValue方法,得到了加法运算后的数值之后,便调用Integer.valueOf方法,再进行equals比较。同理对于后面的也是这样,不过要注意倒数第二个和最后一个输出的结果(如果数值是int类型的,装箱过程调用的是Integer.valueOf;如果是long类型的,装箱调用的Long.valueOf方法)。
(2)存储位置:堆栈
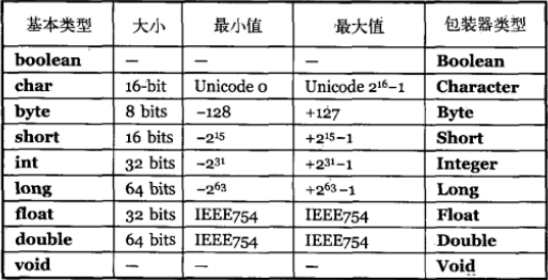
(3)8中基本类型的字节大小。
不需要手动销毁对象
· 作用域:花括号决定
· GC机制决定不需要手动销毁对象。
类
(1)成员变量(字段)、成员函数(方法)。其中对于基本类型的成员变量有默认值。
(2)Java程序:
· 无“向前引用”问题
· 通配符 *,import java.lang.*
· static 修饰时,属于类属性,与实例无关。
· java.lang 在程序中被自动导入。
· 编码风格:命名规则采用“驼峰命名法”。类名的首字母要大写;如果类名由几个单词构成,则并在一起,每个内部单词的首字母采用大写;方法、字段以及对象引用名称等与类相似,只是这些标识符的第一个字母采用小写。
对象的构成
Java的对象头和对象组成详解_Clarence-CSDN博客
对象头
Mark Word
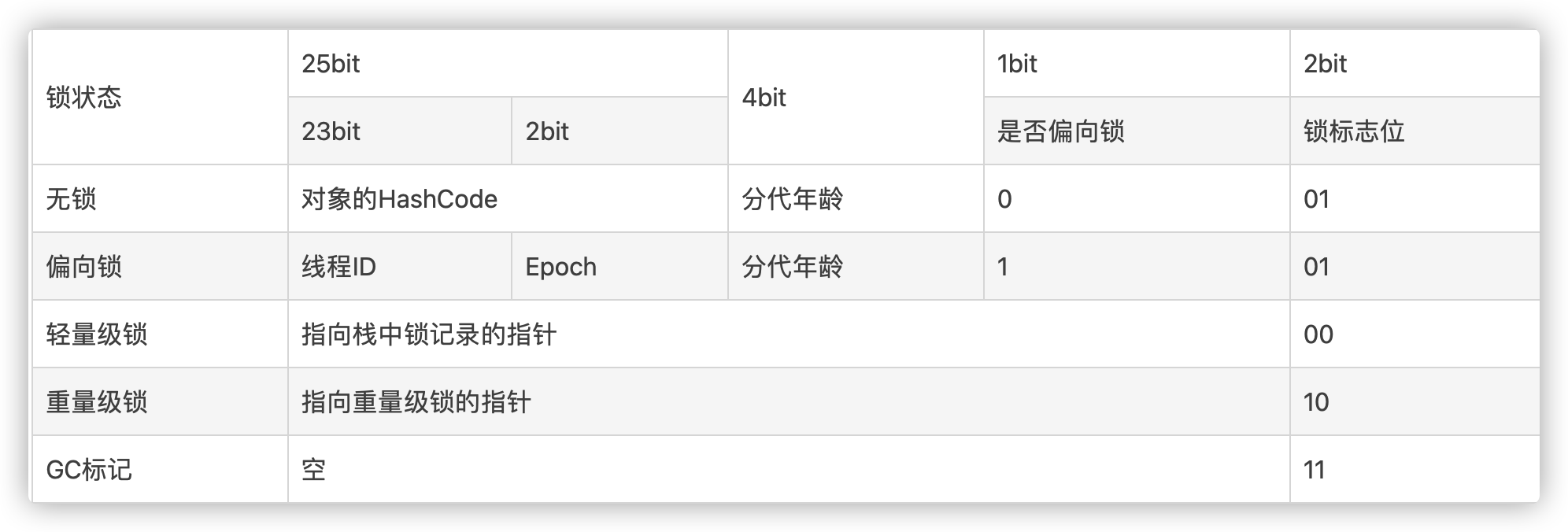
指向类的指针
数组长度(只有数组对象才有)
实例数据
对齐填充字节
操作符
关系操作符
“==”与equals()区别:
· ==对基本类型来说比较数值,对引用类型来说比较的是内存地址。
· equals()在没有被覆盖时,等价于“==”。当被覆盖时,一般比较的是对象的内容。
· String对象中的equals()方法被覆盖过了,比较的是内容。
按位操作符
非(~)不能用于布尔类型,可用!(逻辑操作符)。
移位符
· >>> “无符号”右移
· char、byte、short 移位前需要转int类型
字符串操作
String中的“+”操作符底层原理:
new StringBuffer(str).append(c).toString();
类型转换(cast)
· 基本数据类型
· 窄化转换(危险)
· 扩展转换(安全)
控制执行
foreach 用于数组和容器
· 任何一个返回数组的方法 for(String str : getString()){ }
· 任何Iterable对象
初始化与清理
构造器
如果已经定义了一个构造器(有/无参),编译器不会自动创建默认构造器,此时调用默认无参构造器报错。
方法重载
同一个类中,方法名相同,参数的类型、个数、顺序不同。
注意,方法的关键字和返回值不同,会报错,不属于重载。
this
· 获得当前对象的引用
· 只能在方法内部使用
· 构造器之间调用时,this 只能最多有一个,且只能放第一行
· 不能再staitc修饰的方法中调用
终结处理与垃圾回收
finalize()方法
(1)finalize()方法是Object类中提供的一个方法,在GC准备释放对象所占用的内存空间之前,它将首先调用finalize()方法。其在Object中定义如下:protected void finalize() throws Throwable { }
(2)finalize()调用的时机
与C++的析构函数(对象在清除之前析构函数会被调用)不同,在Java中,由于GC的自动回收机制,因而并不能保证finalize方法会被及时地执行(垃圾对象的回收时机具有不确定性),也不能保证它们会被执行(程序由始至终都未触发垃圾回收)。
public class Finalizer {
@Override
protected void finalize() throws Throwable {
System.out.println("Finalizer-->finalize()");
}
public static void main(String[] args) {
Finalizer f = new Finalizer();
f = null;
}
}
//无输出
public class Finalizer {
@Override
protected void finalize() throws Throwable {
System.out.println("Finalizer-->finalize()");
}
public static void main(String[] args) {
Finalizer f = new Finalizer();
f = null;
System.gc();//手动请求gc
}
}
//输出 Finalizer-->finalize()(3) 什么时候应该使用它
finalize()方法中一般用于释放非Java 资源(如打开的文件资源、数据库连接等),或是调用非Java方法(native方法)时分配的内存(比如C语言的malloc()系列函数)。
(4)为什么避免使用
首先,由于finalize()方法的调用时机具有不确定性,从一个对象变得不可到达开始,到finalize()方法被执行,所花费的时间这段时间是任意长的。我们并不能依赖finalize()方法能及时的回收占用的资源,可能出现的情况是在我们耗尽资源之前,gc却仍未触发,因而通常的做法是提供显示的close()方法供客户端手动调用。
另外,重写finalize()方法意味着延长了回收对象时需要进行更多的操作,从而延长了对象回收的时间。
显示GC( system.gc() )也不一定执行
GC算法
(1) 引用计数
描述工作方式,未实现。
(2)复制
(3)标记清除
(4)标记整理
(5)分代收集机制
· 新生代(使用复制算法)
· 老年代(使用标记清除和标记整理算法)
初始化顺序
(1)字段在任何方法(包括构造器)之前得到初始化。
(2)static
· 只有在必要时刻才会进行(访问该类,因为staic修饰属于类属性)
· 代码块加载顺序
静态代码块(类加载的时候加载一次)—> 普通代码块(在实例化时加载,可加载多次)—> 构造函数(先调用父类构造函数)
访问控制
(1)每个.java文件只能包含一个public类
(2)访问权限修饰词
· 包访问权限(默认)
· public 对每个人可见
· private 仅该类可见(子类可以通过set、get方法调用private属性),不可修饰类
· protected 继承的子类可见 不可修饰类
· 将构造函数用private修饰,可以做成单例模式。
// 利用private修饰构造器,完成单例模式
Class Demo {
private Demo(){};
private static Demo p = new Demo();
public static Demo access(){
return p;
}
}注解
概念
Annotation(注解)是JDK5开始引入的新特性,可以看作是一种特殊的注释,主要用于修饰类,方法或者变量,在框架中大量使用(如 Spring、Mybatis等)
注解是一种能被添加到java代码中的元数据,类、方法、变量、参数和包都可以用注解来修饰。注解对于它所修饰的代码并没有直接的影响。
自定义注解,异步博客Java自定义注解
Java常见的一些注解
@SuppressWarnings注解
SuppressWarnings注解是jse提供的注解。作用是屏蔽一些无关紧要的警告。使开发者能看到一些他们真正关心的警告。从而提高开发者的效率。详细参考文档:https://juejin.cn/post/6924650277744164878
可以标注在类、字段、方法、参数、构造方法,以及局部变量上。
@SuppressWarnings(“unchecked”) 告诉编译器忽略 unchecked 警告信息,如使用List,ArrayList等未进行参数化产生的警告信息。
@SuppressWarnings(“serial”) 如果编译器出现这样的警告信息:The serializable class WmailCalendar does not declare a static final serialVersionUID field of type long,使用这个注释将警告信息去掉。
@SuppressWarnings(“deprecation”) 如果使用了使用@Deprecated注释的方法,编译器将出现警告信息。使用这个注释将警告信息去掉。
@SuppressWarnings(“unchecked”, “deprecation”) 告诉编译器同时忽略unchecked和deprecation的警告信息。
@SuppressWarnings(value={“unchecked”, “deprecation”}) 等同于@SuppressWarnings(“unchecked”, “deprecation”)
复用类
组合类
在类的字段中包含对其他类的引用。
继承
所有类都隐式继承Object类。
Object类的方法:
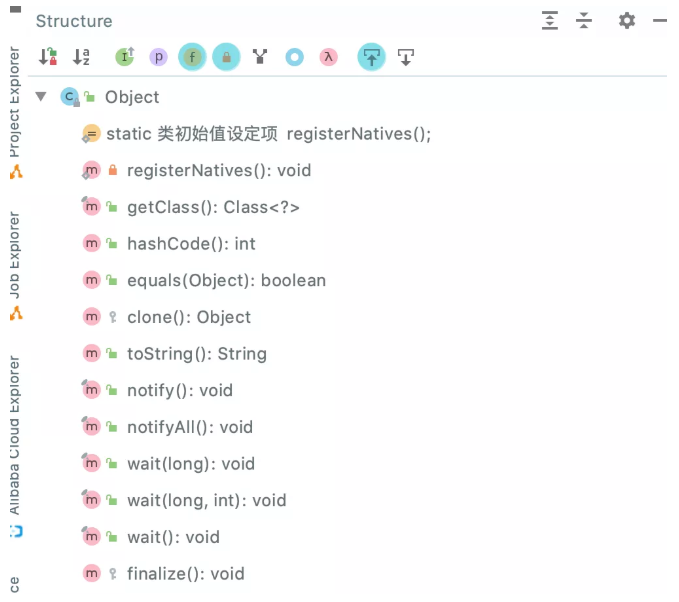
· 关于clone方法:Java 浅拷贝和深拷贝 - 简书、java中clone方法的理解(深拷贝、浅拷贝)_xinghuo0007的博客-CSDN博客
(1)语法
· 父类中,成员变量用private,成员方法用public
· 使用extends关键字
· 使用super.function()在覆盖的方法中访问父类方法。
(2)初始化
· 子类没有构造器,调用父类的
· 基类先加载。基类在导出类构造器可以访问它之前,就已经完成初始化。
(3)覆盖(复写)
· 重载基类的方法,基类本身的方法并不会被屏蔽。
· 只想覆盖 @override注解(不加注解,基类的方法依然存在)
(4)向上转型
final
(1)数据
· 编译时常量,无法创建setter方法
· 运行时初始化并不变
· 使用前总被初始化
(2)方法
防止继承类修改。(private 隐式在子类中指定为final)
(3)类
不可被继承,所有方法隐式为final
初始化及加载
(1)有基类,先加载
(2)加载static
(3)new 先加载基类构造器,再加载子类构造器。
多态
面向对象的三大特征:封装、继承、多态。
方法调用绑定
(1)前期绑定:在程序编译期间绑定
(2)后期绑定:在运行时绑定(动态绑定),static方法不具有多态。
多态设计
· 继承
· 组合:通过类似set方法,修改成员变量
· 接口
向上转型(安全)
接口
提供了一种将接口和实现分离的方法。
抽象类
public abstract class Employee{
public abstract void work();//抽象函数。需要abstract修饰,并分号;结束
}
//manager
public class Teacher extends Employee {
public void work() {
System.out.println("正在赋予权限");
}
}(1)包含抽象方法的类 abstract
可以含有构造方法,子类实例化时,先调用父类构造器。
(2)继承
· 子类必须实现抽象方法
· 可以继续使用abstact修饰,可以不用实现抽象方法
(3)不需要所有方法都是抽象
(4)不可以实例化
接口interface
(1)所以方法都抽象,且隐式为public的
(2)可以包含域,隐式为static和final的
(3)实现:子类实现所有接口方法 implements
(4)不可以实例化
多重继承
(1)extends 一个基类 implements 多个接口
(2)接口之间可以使用extends继承
(3)可以向上转型为任意接口
设计模式
(1)策略设计模式:根据所传参对象不同,具有不同方法(重载)
(2)适配器设计模式:接受拥有的接口,产生所需要的对象
(3)工厂方法设计模式:返回接口的某个实现的对象
异常处理
(1)基本异常Exception
new 异常对象
异常参数:
- 默认构造器
- 字符串
(2)捕获异常
try….catch语句
异常处理的结果有终止模型和恢复模型两种。Java支持终止模型,认为错误非常关键,以至于程序无法返回到异常发生的地方继续执行,一旦异常被抛出,就表明错误已无法挽回,也不能回来继续执行。
finally
- 作用:把内存之外的资源恢复到初始状态,如已经打开的文件或者网络等。
- 含有return时,覆盖其他return。
(3)自定义异常:extends Exception
(4)抛出异常
throw new XXXException("....");(5)异常说明 throws
(6)发现异常时的清理:在创建需要清理的对象之后,立即进入try-catch-fianlly(嵌套)
(7)java.lang.Throwable
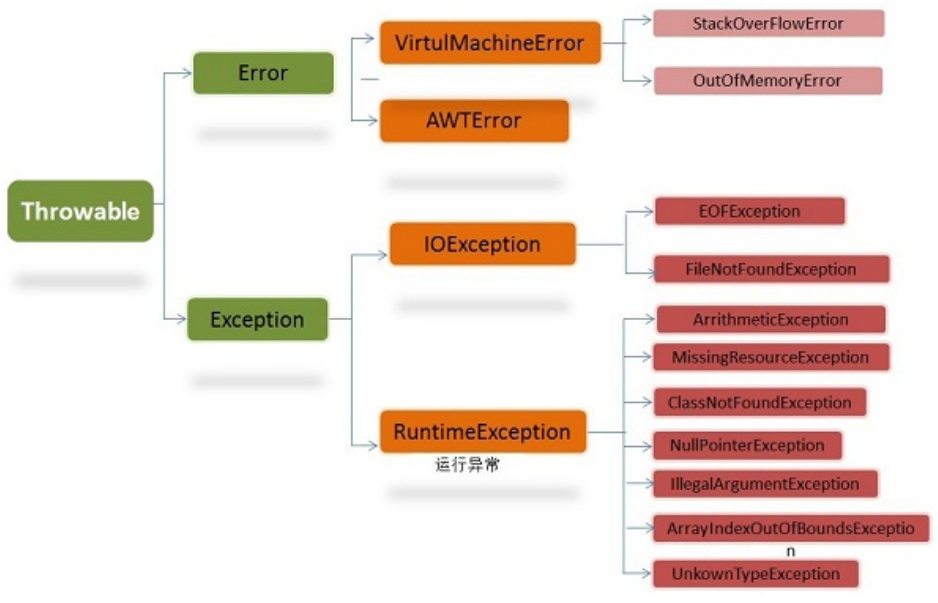
Error(错误):是程序无法处理的错误,表示运行应用程序中较严重问题。编译时和系统错误。
Exception(异常):是程序本身可以处理的异常。可以被抛出的异常。
字符串
String对象不可变
定义:private final byte/char value[] (byte定义是JDK1.9出现的)
-
常量
用final修饰的成员变量表示常量,值一旦给定就无法改变!final修饰的变量有三种:静态变量、实例变量和局部变量,分别表示三种类型的常量。
方法区的常量池

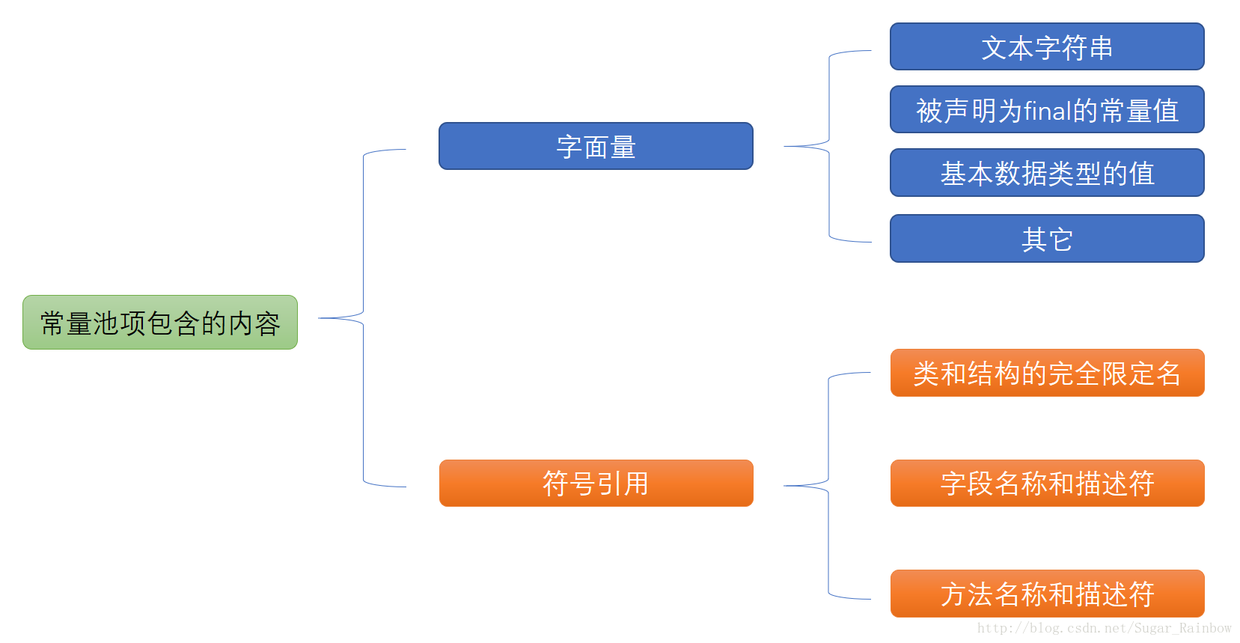
运行时常量池相对于CLass文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入CLass文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是String类的intern()方法。
常量池的好处
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
(1)节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
(2)节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。String类型的常量池
(1)只有使用引号包含文本的方式创建的String对象之间使用“+”连接产生的新对象才会被加入字符串池中。
(2)对于所有包含new方式新建对象(包括null)的“+”连接表达式,它所产生的新对象都不会被加入字符串池中。
可以粗略认为:字符串常量池存放的是对象引用,不是对象。在Java中,对象都创建在堆内存中(待验证)
String的intern()方法
查找在常量池中是否存在一份equal相等的字符串,如果有则返回该字符串的引用,如果没有则添加自己的字符串进入常量池。
public static void main(String[] args) { String str1 = "123"; String str2 = "123"; String a = new String("123"); String b = new String("123");; System.out.println(str1 == str2);//true System.out.println(a == b);//false System.out.println(str1 == b);//false String bb=b.intern(); System.out.println((str1== bb));//true }
“+”“+=”的重载
· java中仅有的两个重载过的操作符
· “+”底层用了StringBuffer()的append()和toString()方法。
String的最大长度
首先字符串的内容是由一个字符数组 char[] 来存储的,由于数组的长度及索引是整数,且String类中返回字符串长度的方法length() 的返回值也是int ,所以通过查看java源码中的类Integer我们可以看到Integer的最大范围是2^31 -1,由于数组是从0开始的,所以数组的最大长度可以使【0~2^31-1】通过计算是大概4GB。
但是通过翻阅java虚拟机手册对class文件格式的定义以及常量池中对String类型的结构体定义我们可以知道对于索引定义了u2,就是无符号占2个字节,2个字节可以表示的最大范围是2^16 -1 = 65535。
其实是65535,但是由于JVM需要1个字节表示结束指令,所以这个范围就为65534了。超出这个范围在编译时期是会报错的,但是运行时拼接或者赋值的话范围是在整形的最大范围。
详细解释可以看: https://mp.weixin.qq.com/s/s15e0GOOxChNtikWEhoH5g
正则表达式
(1)创建正则 java.util.regex.Pattern
(2)表达式
· split( regex )
· replaceAll(regx,String)
反斜杠 \ 在 Java 中表示转义字符,这意味着 \ 在 Java 拥有预定义的含义。
这里例举两个特别重要的用法:
- 在匹配
.或{或[或(或?或$或^或*这些特殊字符时,需要在前面加上\\,比如匹配.时,Java 中要写为\\.,但对于正则表达式来说就是\.。 - 在匹配
\时,Java 中要写为\\\\,但对于正则表达式来说就是\\。
注意:Java 中的正则表达式字符串有两层含义,首先 Java 字符串转义出符合正则表达式语法的字符串,然后再由转义后的正则表达式进行模式匹配。
正则表达式参考:Java正则表达式
常见匹配符号
| 正则表达式 | 描述 |
|---|---|
. |
匹配所有单个字符,除了换行符(Linux 中换行是 \n,Windows 中换行是 \r\n) |
^regex |
正则必须匹配字符串开头 |
regex$ |
正则必须匹配字符串结尾 |
[abc] |
复选集定义,匹配字母 a 或 b 或 c |
[abc][vz] |
复选集定义,匹配字母 a 或 b 或 c,后面跟着 v 或 z |
[^abc] |
当插入符 ^ 在中括号中以第一个字符开始显示,则表示否定模式。此模式匹配所有字符,除了 a 或 b 或 c |
[a-d1-7] |
范围匹配,匹配字母 a 到 d 和数字从 1 到 7 之间,但不匹配 d1 |
XZ |
匹配 X 后直接跟着 Z |
| X|Z | 匹配 X 或 Z |
元字符
元字符是一个预定义的字符。
| 正则表达式 | 描述 |
|---|---|
\d |
匹配一个数字,是 [0-9] 的简写 |
\D |
匹配一个非数字,是 [^0-9] 的简写 |
\s |
匹配一个空格,是 [ \t\n\x0b\r\f] 的简写 |
\S |
匹配一个非空格 |
\w |
匹配一个单词字符(大小写字母、数字、下划线),是 [a-zA-Z_0-9] 的简写 |
\W |
匹配一个非单词字符(除了大小写字母、数字、下划线之外的字符),等同于 [^\w] |
限定符
限定符定义了一个元素可以发生的频率。
| 正则表达式 | 描述 | 举例 |
|---|---|---|
* |
匹配 >=0 个,是 {0,} 的简写 |
X* 表示匹配零个或多个字母 X,.* 表示匹配任何字符串 |
+ |
匹配 >=1 个,是 {1,} 的简写 |
X+ 表示匹配一个或多个字母 X |
? |
匹配 1 个或 0 个,是 {0,1} 的简写 |
X? 表示匹配 0 个或 1 个字母 X |
{X} |
只匹配 X 个字符 | \d{3} 表示匹配 3 个数字,.{10} 表示匹配任何长度是 10 的字符串 |
{X,Y} |
匹配 >=X 且 <=Y 个 | \d{1,4} 表示匹配至少 1 个最多 4 个数字 |
*? |
如果 ? 是限定符 * 或 + 或 ? 或 {} 后面的第一个字符,那么表示非贪婪模式(尽可能少的匹配字符),而不是默认的贪婪模式 |
对比
(1)StringBuilder
· extends AbstractStringBuilder,不用final修饰
· 线程不安全
(2)StringBuffer
· extends AbstractStringBuilder
· 线程安全,对方法加同步锁
(3)常用方法:append、insert、indexOf、toString()
类型信息
RTTI
运行时类型识别。
(1)“传统”,假定在编译时知道了所有类型
(2)“反射”,在运行时发现和使用类的信息
Class对象
java.lang.Class类
(1)被编译后产生,保存在.class文件中
(2)用来创建类的所有对象。创建前,用类加载器加载Class对象
(3)获取Class对象的方式:
1. Class c1 = Class.forName(“类的全限定名”);
2. Class c2 = 类名.class;
3. Class c3 = this.getClass();RTTI应用场景
(1)类型转换
(2)class对象
(3)instance of
(4)反射
class类与java.lang.reflect类库
(5)JDK动态代理
Proxy.newProxyInstance(类加载器,接口列表(目标接口),InvocationHandler实例)
IO
分类
(1)基于字节操作:InputStream/OutputStream
数据持久化或者网络传输都是以字节进行的。
(2)基于字符操作:Reader/Writer
(3)基于磁盘操作:File
(4)基于网络操作:Socket
InputStreamReader从字节到字符转化,需要制定字符集
OutputStreamWriter从字符到字节转化
字符和字节的区别:字节与字符的区别 | 菜鸟教程
模式
(1)BIO
· 同步阻塞
· 面向流
· 数据读取阻塞在线程中
(2)NIO
· 同步非阻塞
· 面向缓冲、基于通道,有选择器
· channel、selector、Buffer
(3)AIO
· 异步非阻塞
· 基于事件和回调机制
磁盘IO工作模式
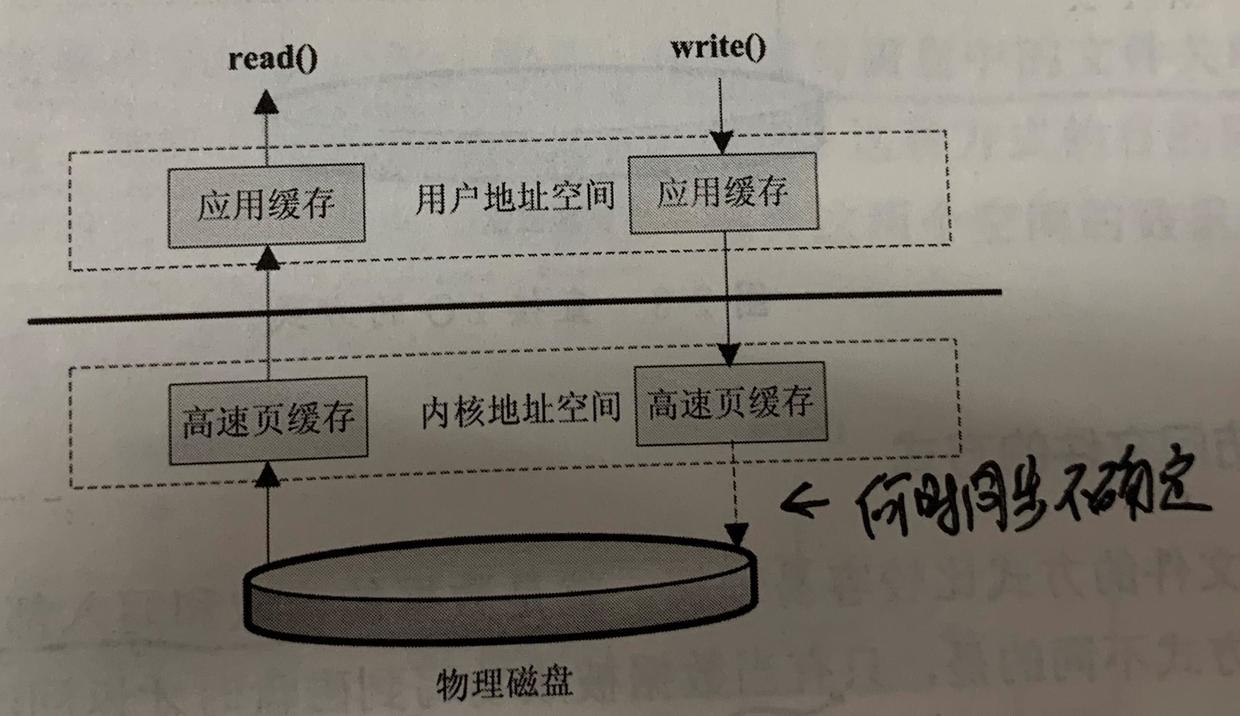
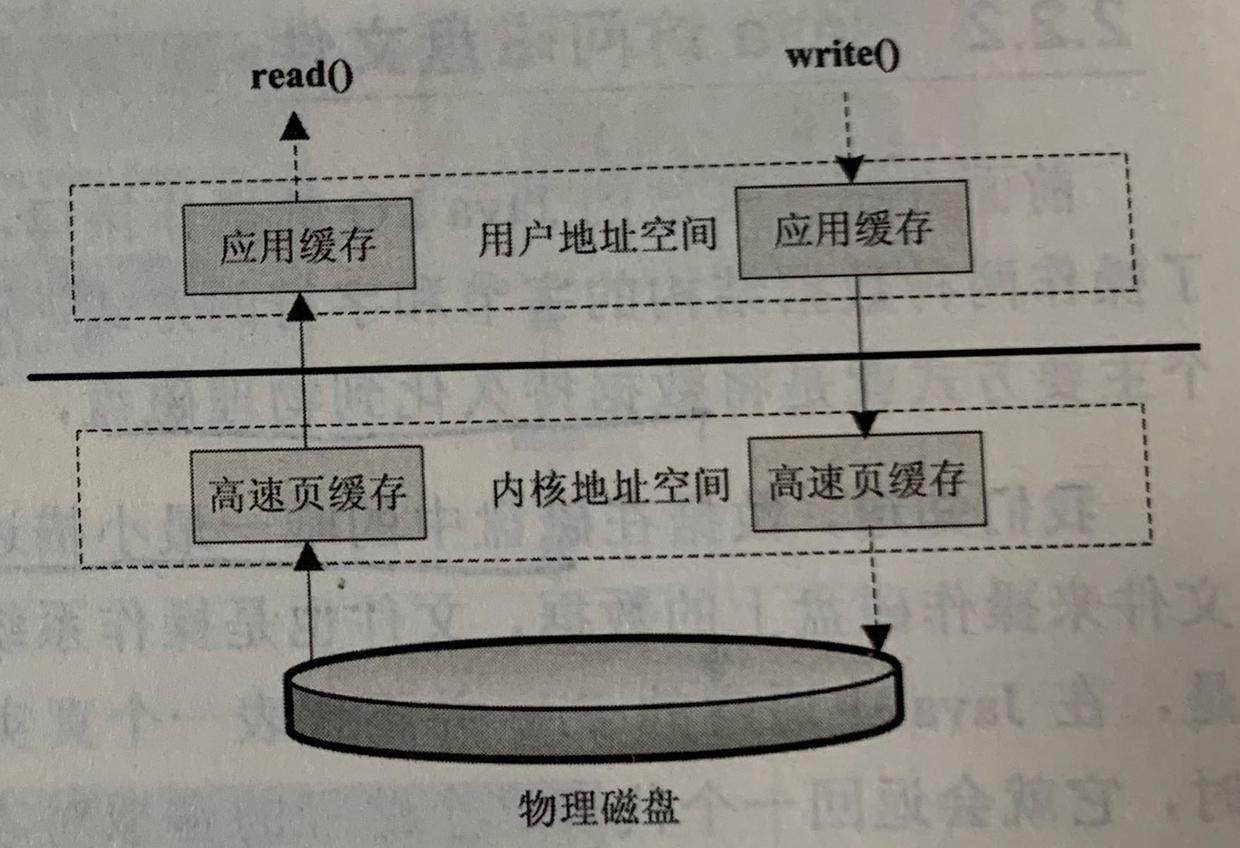
(1)调用方式
读取和写入文件IO操作都调用操作系统提供的接口,因为磁盘设备是由操作系统管理的。
系统调用read()/write() —-》内核空间(含缓存机制) —–》用户空间
(2)访问文件方式
- 标准访问文件方式:先查缓存,再查磁盘。write()时,内核缓存同步sync时间由操作系统决定。
- 直接IO: 不经过内核空间
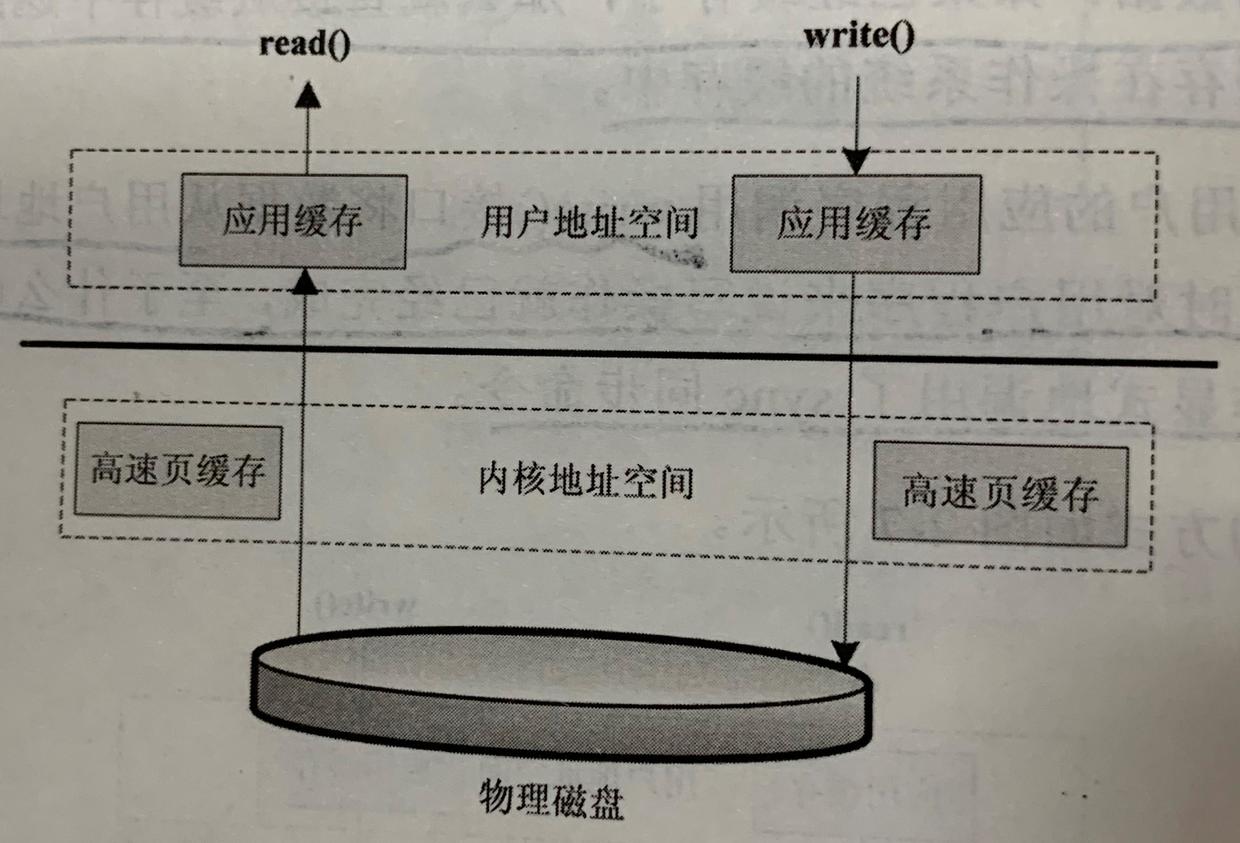
- 同步访问文件:数据写到磁盘才返回成功标志给应用程序。
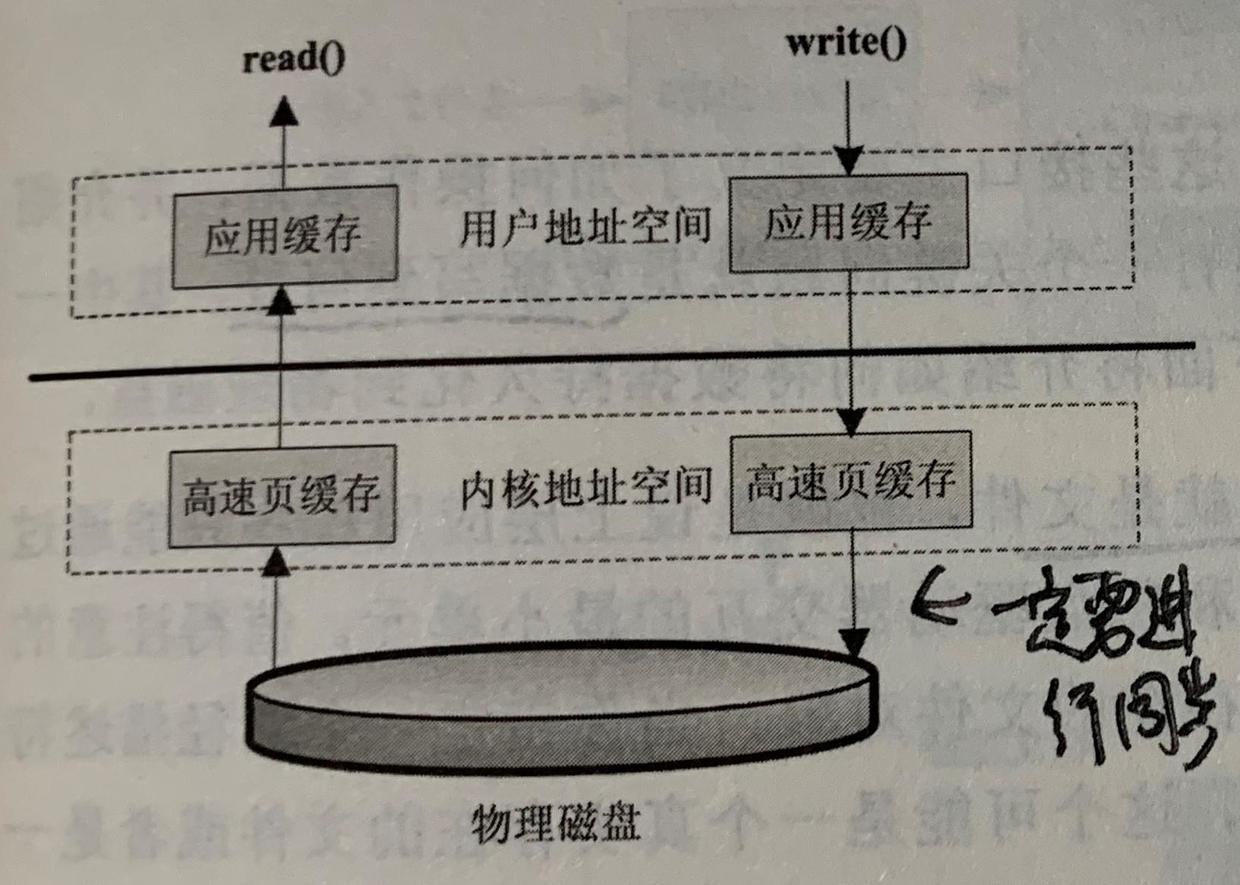
- 异步访问文件:不阻塞等待
Java序列化技术
(1)java序列化技术就是将一个对象转化成一串二进制表示的字节数组,通过保存或转移这些字节数据来达到持久化的目的。
(2)对象必须继承java.io.Serializable接口。
(3)反序列化时,必须有原始类作为模板,才能将这个对象还原。
NIO
简介
Java NIO(New IO)是一个可以替代标准Java IO API的IO API(从Java 1.4开始),Java NIO提供了与标准IO不同的IO工作方式。
Java NIO: Channels and Buffers(通道和缓冲区)
标准的IO基于字节流和字符流进行操作的,而NIO是基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
Java NIO: Non-blocking IO(非阻塞IO)
Java NIO可以让你非阻塞的使用IO,例如:当线程从通道读取数据到缓冲区时,线程还是可以进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。
Java NIO: Selectors(选择器)
Java NIO引入了选择器的概念,选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。

Buffers缓冲区
(1)java.nio包中定义对基本类型的容器。
Buffer就像一个数组,可以保存多个相同类型的数据。根据类型不同(boolean除外),有以下Buffer常用子类:
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
(2)属性
·容量(capacity):表示Buffer最大数据容量,缓冲区容量不能为负,并且建立后不能修改。
·限制(limit):第一个不应该读取或者写入的数据的索引,即位于limit后的数据不可以读写。缓冲区的限制不能为负,并且不能大于其容量(capacity)。
·位置(position):下一个要读取或写入的数据的索引。缓冲区的位置不能为负,并且不能大于其限制(limit)。
·标记(mark)与重置(reset):标记是一个索引,通过Buffer中的mark()方法指定Buffer中一个特定的position,之后可以通过调用reset()方法恢复到这个position。
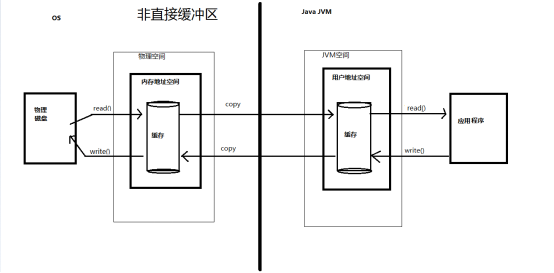
(3)分类
· 非直接缓冲区:通过allocate() 方法分配缓冲区,将缓冲区建立在 JVM 的内存中。数据存储传输需要先复制到内存地址空间,再到磁盘。
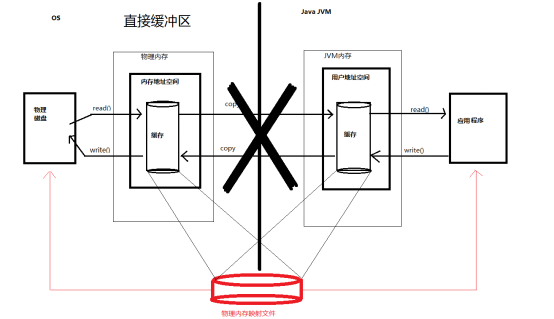
· 直接缓冲区:
· 通过allocateDirect() 方法分配直接缓冲区,将缓冲区建立在物理内存中。可以提高效率。
· 也可以通过FileChannel 的 map() 方法 将文件区域直接映射到内存中来创建。
Channels通道
(1)作用
表示打开到IO 设备(例如:文件、套接字)的连接。若需要使用NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理。Channel 负责传输, Buffer 负责存储。
(2)java.nio.channels.Channel 接口:
·FileChannel
·SocketChannel
·ServerSocketChannel
·DatagramChannel
(3)分散读取、聚集写入
scattering Reads:将通道中的数据分散到多个缓冲区中。
gathering Writes:将多个缓冲区的数据聚集到通道中
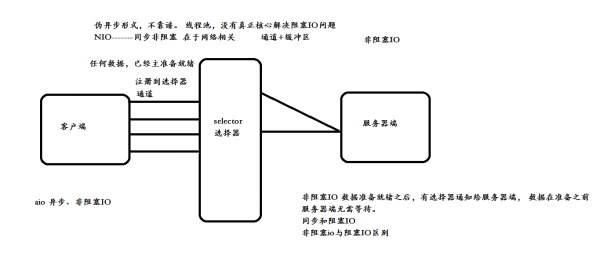
阻塞与非阻塞
(1)阻塞:客户端连接请求时,服务器只能等待连接请求,不能处理其他事情。
(2)非阻塞:客户端连接注册到多路复用器上,当轮询到连接有I/O请求时,才启动线程处理。
(3)几种IO模式的线程之间对比
BIO:同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
NIO:同步非阻塞式IO,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
AIO(NIO.2):异步非阻塞式IO,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
伪异步:使用线程池管理

Selector选择器
(1)SelectionKey类
在SelectionKey类的源码中我们可以看到如下的4中属性,四个变量用来表示四种不同类型的事件:可读、可写、可连接、可接受连接
·SelectionKey.OP_CONNECT
·SelectionKey.OP_ACCEPT
·SelectionKey.OP_READ
·SelectionKey.OP_WRITE
如果你对不止一种事件感兴趣,那么可以用“位或”操作符将常量连接起来,如下:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
NIO的Socket请求
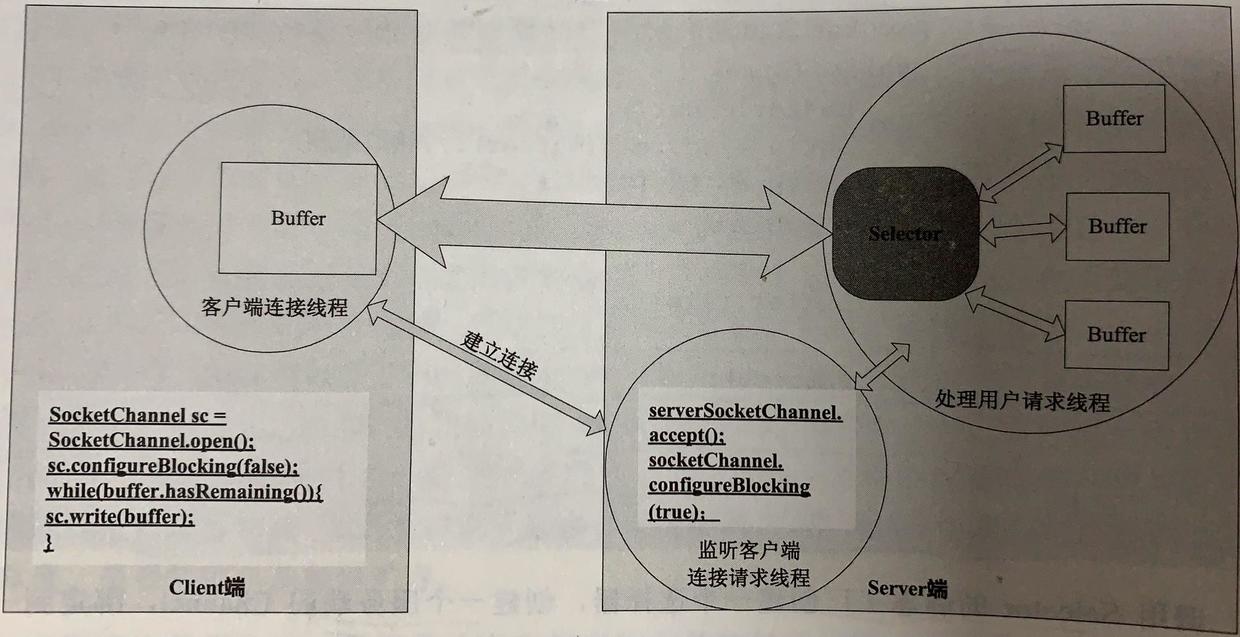
分为两个线程共工作,一个监听客户端连接,一个用于处理数据交互。
JPA
(1)Java Persistence API 持久层API
JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。所以底层需要某种实现
(2)基于O/R映射的标准规范
(3)主要实现:Hibernate、EclipseLink、openJPA
(4)提供
· XML或注解,将实体对象持久化到数据库中。@Entity、@Table、@Column、@Transient
· API,用来操作实体对象,执行CRUD
· JPQL查询语句
(5)避免字段持久化到数据库方法
static
transient 也可以在Java中修饰,防止序列化。
@Transient
// 初始化
Wanger wanger = new Wanger();
wanger.setName("王二");
wanger.setAge(18);
System.out.println(wanger);
// 把对象写到文件中
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("chenmo"));){
oos.writeObject(wanger);
} catch (IOException e) {
e.printStackTrace();
}
// 改变 static 字段的值
Wanger.pre ="不沉默";
// 从文件中读出对象
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("chenmo")));){
Wanger wanger1 = (Wanger) ois.readObject();
System.out.println(wanger1);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
// Wanger{name=王二,age=18,pre=沉默,meizi=王三}
// Wanger{name=王二,age=18,pre=不沉默,meizi=null}另外, final关键字在序列化和反序列化时有一些微妙,详见:java序列化与final关键字
Java集合
泛型
指定容器可以保存的类型,在编译器检查错误。
我们在定义泛型类,泛型方法,泛型接口的时候经常会碰见很多不同的通配符,比如 T,E,K,V 等等。本质上这些个都是通配符,没啥区别,只不过是编码时的一种约定俗成的东西。比如上述代码中的 T ,我们可以换成 A-Z 之间的任何一个 字母都可以,并不会影响程序的正常运行,但是如果换成其他的字母代替 T ,在可读性上可能会弱一些。通常情况下,T,E,K,V,?是这样约定的:
- ?表示不确定的 java 类型
- T (type) 表示具体的一个java类型
- K V (key value) 分别代表java键值中的Key Value
- E (element) 代表Element
?无界通配符
对于不确定或者不关心实际要操作的类型,可以使用无限制通配符(尖括号里一个问号,即 <?> ),表示可以持有任何类型。
不过一般和用在上下届通配符里面。
上界通配符 < ? extends E>
用 extends 关键字声明,表示参数化的类型可能是所指定的类型,或者是此类型的子类。
- 如果传入的类型不是 E 或者 E 的子类,编译不成功
- 泛型中可以使用 E 的方法,要不然还得强转成 E 才能使用
类型参数列表中如果有多个类型参数上限,用逗号分开
private <K extends A, E extends B> E test(K arg1, E arg2){
E result = arg2;
arg2.compareTo(arg1);
//.....
return result;
}下界通配符 < ? super E>
用 super 进行声明,表示参数化的类型可能是所指定的类型,或者是此类型的父类型,直至 Object
?和 T 的区别
T 是一个确定的类型,通常用于泛型类和泛型方法的定义,?是一个不确定的类型,通常用于泛型方法的调用代码和形参,不能用于定义类和泛型方法。
// 可以
T t = operate();
// 不可以
?car = operate();Class<T>在实例化的时候,T 要替换成具体类。Class<?>它是个通配泛型,? 可以代表任何类型,所以主要用于声明时的限制情况
// 可以
public Class<?> clazz;
// 不可以,因为 T 需要指定类型
public Class<T> clazzT;那如果也想 public Class<T> clazzT;这样的话,就必须让当前的类也指定 T ,
public class Test3<T> {
public Class<?> clazz;
// 不会报错
public Class<T> clazzT;分类
Java容器类类库的用途是“保存对象”。
Collection
· Collection容器继承了Iterable接口( 实现iterator()方法 ),都可以使用foreach。
· Collection容器都覆盖了toString(),可以直接使用print()
List表
(1)必须按照插入的顺序保存元素
(2)常见接口方法
| 方法 | 功能 |
|---|---|
| boolean add(E e) | 在尾部追加元素 |
| void add(int index, E element) | |
| void clear() | |
| boolean contains(Object o) | |
| E get(int index) | 获取指定下标的元素 |
| int indexOf(Object o) | 获取指定元素的下标 |
| boolean isEmpty() | 判断是否为空 |
| E remove(int index / Object o) | 移除 |
| E set(int index, E element) | 修改元素 |
| int size() | 获得大小 |
| Object[] toArray[] | 转化为数组 |
Set
(1)不能用重复元素
(2)常见接口方法
| 方法 |
|---|
| void clear() |
| boolean add(E e) |
| boolean contains(Object o) |
| boolean isEmpty() |
| boolean remove(Object o) |
| int size() |
| Object[] toArray() |
Queue
(1)按照排队规则来确定对象产生的顺序
(2)@常见接口方法
· Throws exception
· boolean add(E e) · E remove() 返回并删除头元素 · E element() 返回头元素
· Returns special value
· boolean offer(E e) · E poll() 返回并弹出头节点 · E peek() 返回头元素
Map
(1)一组成对的“键值对”对象,允许使用键来查找值
(2)常见接口方法
| 方法 |
|---|
| void clear() |
| boolean containsKey(Object key) |
| boolean containsValue(Object value) |
| Set<Map.Entry<K,V>> entrySet() |
| boolean equals(Object o) |
| Object get(Object key) |
| boolean isEmpty() |
| Object put(Object k, Object v) 会覆盖前面的值 |
| Object remove(Object key) |
| default boolean replace(Object key, Object value, Object newValue) |
| int size() |
| remove(Object key) |
| getOrDefault(Object key, V defaultValue) |
| Object result = hashMap.computeIfAbsent(Object key, Function remappingFunction) 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hashMap. 如果 key 对应的 value 不存在,则使用获取 remappingFunction 重新计算后的值,并保存为该 key 的 value,否则返回 value。 |
| putIfAbsent(Object key, Object value) 如果key不存在,写入;如果key存在,跳过 |
| foreach(lamda表达式) 遍历Map |
说明:
调用Map.entrySet(),将集合中的映射关系对象存储Set中。迭代Set集合,通过entry的getKey()和getValue()方法获取映射关系对象。
迭代器Iterator
概念
· 迭代器是一个对象,它的工作是遍历并选择序列中的对象,而客户端程序员不必知道或关心该序列底层的结构。
· 迭代器只能单向移动。
· 不能对正在被迭代的集合进行结构上的改变,否则抛出异常。但可以使用iterator自己的remove方法
使用
(1)使用iterator()返回一个Iterator对象,并准备返回序列的第一个元素。
(2)使用next()获得序列的下一个元素
(3)使用hasNext()检查序列中是否还有元素
(4)使用remove()将迭代器新近返回的元素删除
public class Demo{
public static void mian(String[] args){
List<Pet> pets = Pets.arrayList(12);
Iterator<Pet> it = pets.iteratror();
while(it.hasNext()){
Pet p = it.next();
system.out.print(p);
}
for(Pet p : pets){
system.out.print(p);
}
}
}使用foreach语法更简洁。
List的实现
ArrayList
基本特性
(1)擅长于随机访问元素,但插入和移除元素慢
(2)线程不安全,底层为Object数组
扩容机制
(1)无参构造时,初始为空数组。当添加第一个元素时,扩为10(默认)。
(2)填满时,自动扩容,变为原来的1.5倍左右(奇数偶数不同)。
LinkedList
(1)插入删除代价较低,但随即访问慢。
(2)线程不安全,底层为双向链表。
(3)没有实现RandomAccess接口(标识是否具有随机访问能力)。
(4)实现了基本的List接口,同时添加了可以使用其作栈、队列或者双端队列的方法。
Vector
(1)Vector简介
Vector 是矢量队列,它是JDK1.0版本添加的类。继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口。
Vector 继承了AbstractList,实现了List;所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能。
Vector 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。
和ArrayList不同,Vector中的操作是线程安全的。
(2)底层分析
·Vector实际上是通过一个数组去保存数据的。当我们构造Vecotr时;若使用默认构造函数,则Vector的默认容量大小是10。
·当Vector容量不足以容纳全部元素时,Vector的容量会增加。若容量增加系数 >0,则将容量的值增加“容量增加系数”;否则,将容量大小增加一倍。
·Vector的克隆函数,即是将全部元素克隆到一个数组中。
Stack栈
(1)后进先出(LIFO)的容器,是限制插入和删除只能在一个位置上进行的表。
(2)LinkedList作为底层实现。
(3)常用方法:
· push(Object o) · pop() · peek()
(4)常见应用:
· 后缀表达式
Set的实现
HashSet
(1)最快的获取元素的方式
(2)利用HashMap的Key存储
(3)判断重复元素原理:
· 利用hashCode()和equals()方法。先计算加入对象的hashcode值来判断加入的位置,同时与其他对象的hashcode值比较,如果没有相同的hashcode,则假设对象没有重复出现。若hashcode相同,则通过equals方法价差hashcode相等的对象是否真的相同,若相同,则插入操作不成功;若不同,则重新散列。
· equals()方法被覆盖,则hashCode()方法也必须被覆盖。原因:
· 两个对象相等,hashcode值一定相同。
· 两个对象相等,equals()方法放回true。
· 相同hashcode值,对象不一定相等。
TreeSet
(1)具有有序的存储顺序,按照比较结果的升序保存对象
1. 利用Comparator排序
TreeSet<User> users = new TreeSet<User>(new MyComparator());
2. 装入的对象实现了Comparator接口,有顺序也行(2)利用红黑树结构实现
LinkedHashSet
(1)按照添加的顺序保存对象
(2)使用链表来维护元素的插入顺序
Map的实现
HashMap
概念
(1)提供最快的查找技术
(2)基于散列表实现
(3)线程不安全
(4)hash()方法
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:⽆符号右移,忽略符号位,空位都以0补⻬
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}· HashMap通过key的hashCode经过扰动函数处理过后得到hash值
· 然后通过(n - 1) & hash判断当前元素存放的位置,n为数组的长度。
· 判断该元素与存入的元素的hash值和key是否相同,相同则直接覆盖,不相同就通过“拉链法”解决冲突。
底层数据结构
(1)JDK1.8之前,使用数组+链表
数组中存储Node<K,V>(implements Map.Entry<K,V>)。数组初始大小为16.
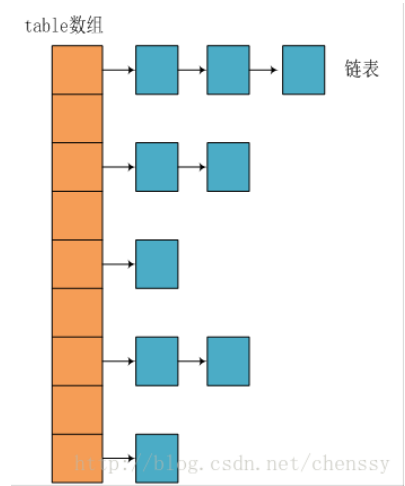
(2)JDK1.8之后,使用数组+链表+红黑树,当链表的长度大于阈值(默认8)时 ,变为红黑树
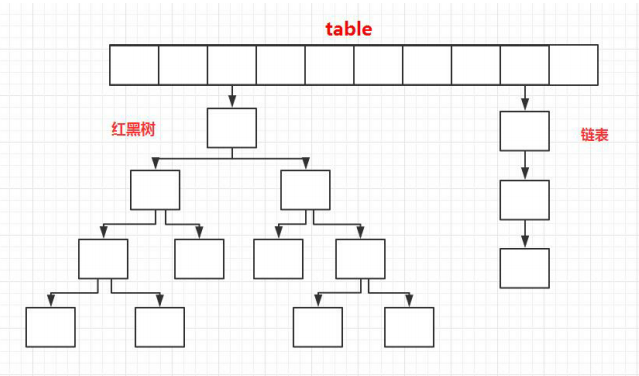
rehash扩容机制
(1)哈希桶数组table的长度length大小必须为2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数
为什么要是2的n次方:取余(%)操作中,如果除数是2的幂次则等价于其除数减一的与(
&)操作,即hash%length == hash & (length - 1)。采用二进制的位操作后,相对于%能提高运算效率。
(2)扩容条件
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;首先,Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
if (++size > threshold)
resize();当大于阈值threshold 时,进行扩容。
(3)rehash过程
· 数组大小扩容为原来的2倍。
· 再散列到新数组。
(4)弊端
多线程操作可能导致形成循环链表(rehash过程)。
TreeMap
(1)默认按照key的字典顺序来排序(升序)
字典序
- 排序规则
两个字符串 s1, s2比较
1. 如果s1和s2是父子串关系,则 子串 < 父串 2. 如果非为父子串关系, 则从第一个非相同字符来比较。 例子 s1 = "ab", s2 = "ac" 这种情况算法规则是从第二个字符开始比较,由于'b' < 'c' 所以 "ab" < "ac" 3. 字符间的比较,是按照字符的字节码(ascii)来比较- compareTo 实现机制:对于字符串来说,字典排序规则;对于数字字符串来说,直接按照大小排序
(2)基于红黑树(自平衡的排序二叉树)实现,次序由Comparable或者Comparator决定
TreeMap<String, String> map = new TreeMap<String, String>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});LinkedHashMap
(1)按照插入顺序保存键值,同时保留HashMap的查询速度
(2)使用链表维护内部顺序。
(3)采用基于访问的最近最少使用(LRU)算法,没有被访问过的元素就会出现在队列的前面。
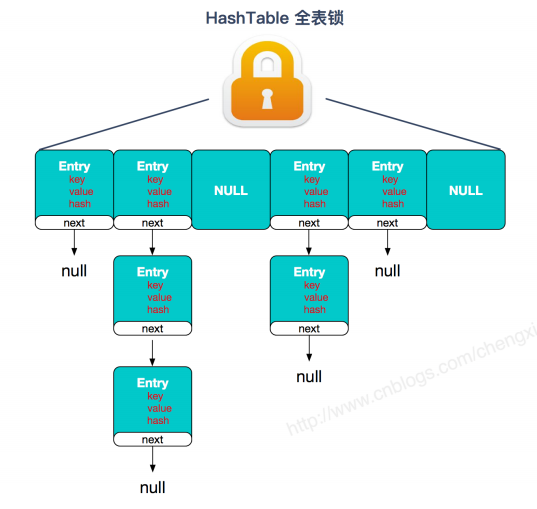
HashTable
(1)线程安全,内部的方法基本都是经过synchronized修饰,其他使用与HashMap类似。
(2)与concurrentHashMap相比,HashTable使用全表锁。
ConcurrentHashMap
与HashMap相比,线程安全,适合并发环境。
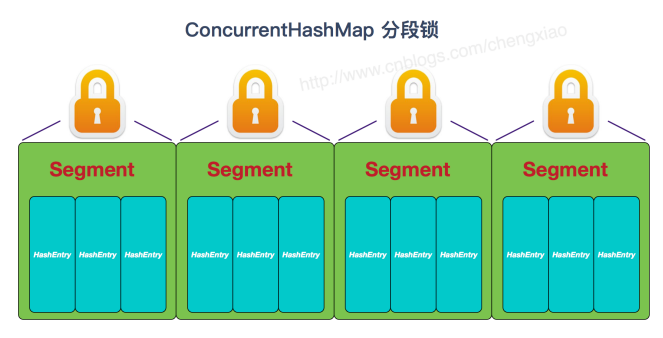
(1)JDK1.7 分段锁
对整个通数组进行分割分段(Segment),多线程访问容器不同段数据时,不会存在锁竞争,提高并发访问效率。
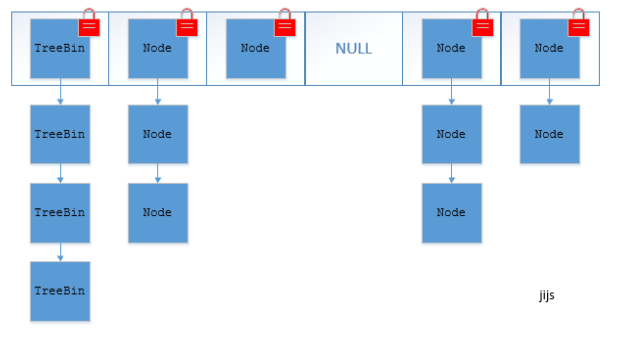
(2)JDK1.8 synchronized + CAS
看起来是一个优化过且线程安全的HashMap。synchronized只锁定当前链表或红黑树的首节点。
Queue
先进先出(FIFO)的容器,在一端进行插入而在另一端进行删除的表。
实现方式
(1)Deque接口,双端队列,底层实现可以选择LinkedList。
(2)LinkedList
(3)PriorityQueue
优先级队列(堆),用Comparator对象修改排序顺序,默认为最小堆。
分类
(1)单队列,存在“假溢出”问题
(2)循环队列
比较器
Comparable
来自java.lang包,使用comparaTo(Object obj)方法排序。
Comparable是排序接口。若一个类实现了Comparable接口,就意味着该类支持排序。实现了Comparable接口的类的对象的列表或数组可以通过Collections.sort或Arrays.sort进行自动排序。
此外,实现此接口的对象可以用作有序映射中的键或有序集合中的集合,无需指定比较器。
public class Person implements Comparable<Person>{
@Override
publicint compareTo(Person p)
{
return this.age-p.getAge();
}
}上述demo表示按照从小到大的年纪排序对象。
Comparator
来自java.util包,使用compare(Object obj1, Object obj2)方法排序。
Comparator是比较接口,我们如果需要控制某个类的次序,而该类本身不支持排序(即没有实现Comparable接口)。
int compare(T o1, T o2) 是“比较o1和o2的大小”。返回“负数”,意味着“o1比o2小”;返回“零”,意味着“o1等于o2”;返回“正数”,意味着“o1大于o2”.
public class PersonCompartor implements Comparator{
@Override
publicint compare(Person o1, Person o2)
{
return o1.getAge()-o2.getAge();//从小到大排序
}
}
Arrays.sort(people,new PersonCompartor());
// 定制排序的⽤法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1); //从大到小排序
}
}); 注意:上面demo的compareTo方法,在String类中有,按字典序或自然顺序排序。
工具类Collections和Arrays
Arrays
在java.util中有一个Arrays类,此类包含用于操纵数组的各种方法,例如:二分查找(binarySearch)、拷贝操作(copyOf)、比较(equals)、填充(fill)、排序(sort)等,功能十分强大。
排序 :sort() 默认从小到大排序
查找 :binarySearch()
比较: equals
填充 :fill(int[], int),可以用作批量初始化
转列表: asList(int, int, int) 参数用逗号隔开
哈希:hashCode()
转字符串 :toString()
拷贝:copyOfRange(int[], int from, int to)
Collections
(1)排序
void reverse(List list)//反转
void shuffle(List list)//随机排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j)//交换两个索引位置的元素
void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
(2)查找替换
int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素。
int frequency(Collection c, Object o)//统计元素出现次数
int indexOfSubList(List list, List target)//统计targe在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素



