
目录
1 概念
2 Springboot
3 Spring Cloud Eureka
4 Spring Cloud Ribbon
5 Spring Cloud Hystrix
6 Spring Cloud Feign
7 Spring Cloud Zuul
8 Spring Cloud Config参考资料
· 《Spring Cloud 微服务实战》
概念
微服务
微服务是系统架构上的一种设计风格, 它的主旨是将一个原本独立的系统拆分成多个小型服务,这些小型服务都在各自独立的进程中运行,服务之间通过基于HTTP的RESTful API进行通信协作。
被拆分成的每一个小型服务都围绕着系统中的某一项或一些耦合度较高的业务功能进行构建, 并且每个服务都维护着自身的数据存储、 业务开发、自动化测试案例以及独立部署机制。 由千有了轻量级的通信协作基础, 所以这些微服务可以使用不同的语言来编写。
Spring Cloud
Spring Cloud是一个基于SpringBoot实现的微服务架构开发 工具。它为微服务架构中涉及的 配置管理、服务治理、 断路器、 智能路由、微代理、 控制总线、 全局锁、 决策竞选、分布式会话和集群状态管理等操作提供了一种简单的开发方式。
Spring Cloud包含了多个子项目,其中Spring Cloud Netflix是核心组件, 对多个Netflix OSS开源套件进行整合。
• Ribbon: 客户端负载均衡的服务调用组件。
• Eureka: 服务治理组件, 包含服务注册中心、 服务注册与发现机制的实现。
• Hystrix: 容错管理组件,实现断路器模式,帮助服务依赖中出现的延迟和为故障提供强大的容错能力。
• Feign: 基于伈bbon 和 Hystrix 的声明式服务调用组件。
• Zuul: 网关组件, 提供智能路由、 访问过滤等功能。
• Archaius: 外部化配置组件。
SpringCloud注解和配置概览
Spring Cloud Eureka
服务治理
服务治理可以说是微服务架构中最为核心和基础的模块, 它主要用来实现各个微服务实例的自动化注册与发现。
(1)服务注册
在服务治理框架中, 通常都会构建一个注册中心, 每个服务单元向注册中心登记自己提供的服务, 将主机与端口号、 版本号、 通信协议等一些附加信息告知注册中心, 注册中心按服务名分类组织服务清单。

另外, 服务注册中心还需要以心跳的方式去监测清单中的服务是否可用, 若不可用需要从服务清单中剔除, 达到排除故障服务的效果。
(2)服务发现
调用方需要向服务注册中心咨询服务, 并获取所有服务的实例清单, 以实现对具体服务实例的访问。
实现
角色
(1)Eureka服务端
服务注册中心。Netflix推荐每个可用的区域运行一个Eureka服务端,通过它来形成集群。不同可用区域的服务注册中心通过异步模式互相复制各自的状态,这意味着在任意给定的时间点每个实例关于所有服务的状态是有细微差别的。
(2)Eureka客户端
主要处理服务的注册与发现。Eureka客户端向注册中心注册自身提供的服务并周期性地发送心跳来更新它的服务租约。同时,它也能从服务端查询当前注册的服务信息并把它们缓存到本地并周期性地刷新服务状态。
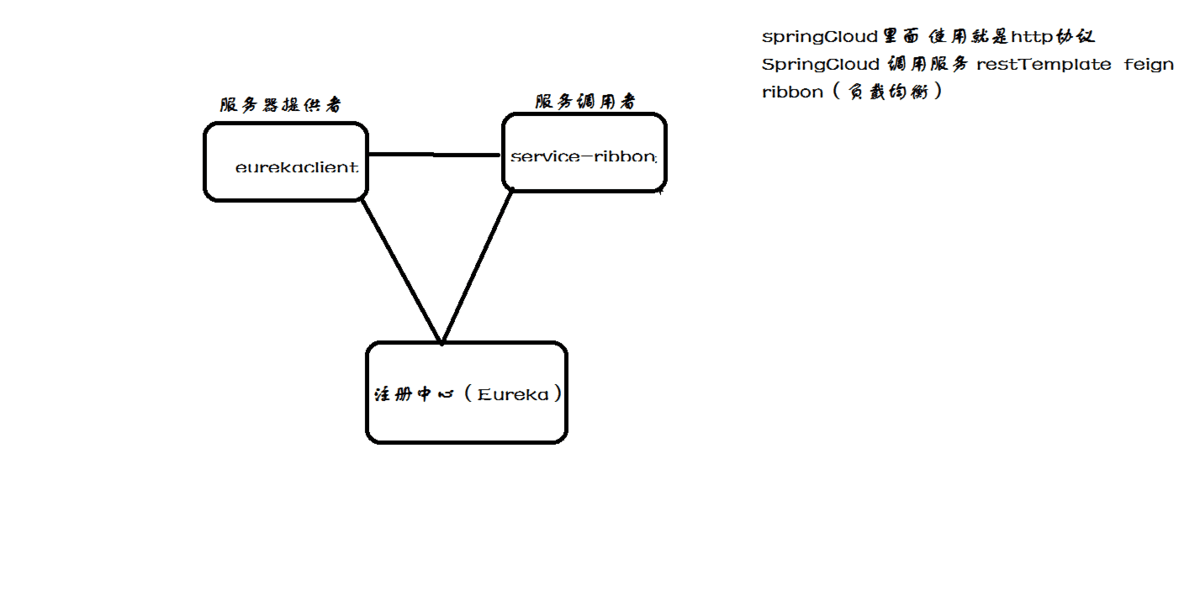
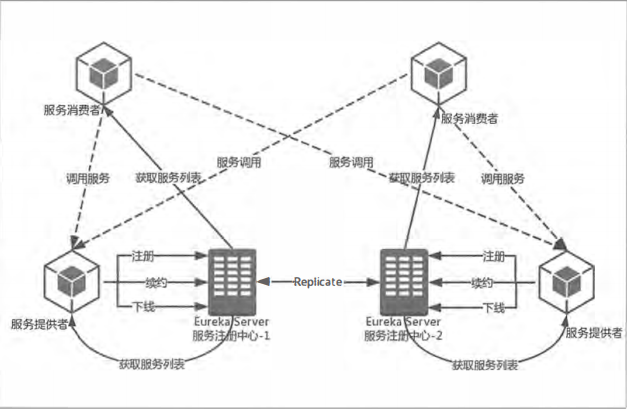
架构
• 服务注册中心: Eureka 提供的服务端, 提供服务注册与发现的功能,即eureka-server。
• 服务提供者:提供服务的应用, 可以是 Spring Boot 应用, 也可以是其他技术平台且遵循 Eureka 通信机制的应用。它将自己提供的服务注册到 Eureka, 以供其他应用发现。
• 服务消费者:消费者应用从服务注册中心获取服务列表, 从而使消费者可以知道去何处调用其所需要的服务,可以使用 Ribbon或Feign来实现服务消费。
高可用注册中心
(1)Eureka Server的高可用实际上就是将自己作为服务向其他服务注册中心注册自己,这
样就可以形成一组互相注册的服务注册中心, 以实现服务清单的互相同步, 达到高可用的
效果
(2)相关参数
eureka.client.register-with-eureka: 设置为 false,代表不向注册中心注册自己
eureka.client.fetch-registry: 注册中心的职责就是维护服务实例,它并不需要去检索服务, 所以也设置为 false
eureka.client.register-with-eureka=false
eureka.client.fetch-registry=false详解
服务提供者
(1)服务注册
· 在启动的时候会通过发送REST请求的方式将自己注册到EurekaServer 上, 同时带上了自身服务的一些元数据信息。
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful
· Eureka Server接收到这个REST请求之后,将元数据信息存储在一个双层结构Map中, 其中第一层的key是服务名, 第二层的key是具体服务的实例名。
(2)服务同步
由于服务注册中心之间因互相注册为服务, 当服务提供者发送注册请求到一个服务注册中心时, 它会将该请求转发给集群中相连的其他注册中心, 从而实现注册中心之间的服务同步 。 通过服务同步,两个服务提供者的服务信息就可以通过这两台服务注册中心中的任意一台获取到。
(3)服务续约
在注册完服务之后,服务提供者会维护一个心跳用来持续告诉EurekaServer: “我还活着 ”, 以防止Eureka Server的 “剔除任务 ” 将该服务实例从服务列表中排除出去,我们称该操作为服务续约(Renew)。
关于服务续约有两个重要属性,我们可以关注并根据需要来进行调整:
eureka.instance.lease-renewal-interval-in-seconds=30
eureka.instance.lease-expiration-duration-in-seconds=90eureka.instance.lease-renewal-interval-in-seconds 参数用于定义服务续约任务的调用间隔时间,默认为30秒。 eureka.instance.lease-expiration-duration-in-seconds参数用于定义服务失效的时间,默认为90秒。
服务消费者
(1)获取服务
启动服务消费者的时候, 它会发送一个REST请求给服务注册中心,来获取上面注册的服务清单 。 为了性能考虑, Eureka Server会维护一份只读的服务清单来返回给客户端,同时该缓存清单会每隔30秒更新一次。
若希望修改缓存清单的 更新时间,可以通过 eureka.client.registry-fetch-interval-seconds= 30参数进行修改,该参数默认值为30, 单位为秒。
(2)服务调用
通过服务名可以获得具体提供服务的实例名和该实例的元数据信息。在Ribbon中会默认采用轮询的方式进行调用,从而实现客户端的负载均衡。
Eureka中有Region和Zone的概念, 一个Region中可以包含多个Zone, 每个服务客户端需要被注册到 一个Zone中, 所以每个客户端对应一个Region和一个Zone。 在进行服务调用的时候,优先访问同处一个 Zone 中的服务提供方, 若访问不到,就访问其他的Zone。
(3)服务下线
当服务实例进行正常的关闭操作时, 它会触发一个服务下线的REST请求给Eurka Server, 告诉服务注册中心:“我要下线了”。 服务端在接收到请求之后, 将该服务状态置为下线(DOWN), 并把该下线事件传播出去。
注册中心
(1)失效剔除
为了从服务列表中将这些无法提供服务的实例剔除, Eureka Server在启动的时候会创建一个定时任务,默认每隔一段时间(默认为60秒) 将当前清单中超时(默认为90秒)没有续约的服务剔除出去。
(2)自我保护
EurekaServer 在运行期间,会统计心跳失败的比例在15分钟之内是否低于85%, 如果出现低于的情况(在单机调试的时候很容易满足, 实际在生产环境上通常是由于网络不稳定导致), EurekaServer会将当前的实例注册信息保护起来, 让这些实例不会过期, 尽可能保护这些注册信息。
相应的客户端必须要有容错机制, 比如可以使用请求重试、 断路器等机制。
源码分析
客户端Client
在将一个普通的 Spring Boot 应用注册到 Eureka Server 或是从 Eureka Server 中获取服务列表时, 主要就做了两件事:
• 在应用主类中配置了@EnableDiscoveryClient注解。
• 在 app让cation.properties 中用 eureka .client.serviceUrl.defaultZone参数指定了服务注册中心的位置。
(1)URLs表获取

注意:
· Region与Zone是一对多的关系
· eureka.client.serviceUrl.defaultZone 属性可以配置多个,并且需要通过逗号分隔。
(2)服务注册

com.netflix.appinfo.Instanceinfo 对象, 该对象就是注册时客户端给服务端的服务的元数据。
(3)服务获取与服务续约

“服务获取 ” 任务相对于 “服务续约” 和 “服务注册“ 任务更为独立。”服务续约” 与 “服务注册 “ 在同一个 if逻辑中,这个不难理解,服务注册到 EurekaServer 后, 自然需要一个心跳去续约, 防止被剔除, 所以它们肯定是成对出现的。
“服务获取 ” 的逻辑在独立的一个 W 判断中, 其判断依据就是我们之前所提到的eureka.client-fetch-registry=true 参数, 它默认为 true,大部分情况下我们不需要关心。 为了定期更新客户端的服务清单, 以保证客户端能够访问确实健康的服务实例, “服务获取 ” 的请求不会只限于服务启动, 而是一个定时执行的任务。
服务端Server
服务注册中心处理

将InstanceInfo中的元数据信息存储在 一个ConcurrentHashMap对象中。正如我们之前所说的,注册中心存储了两层Map结构, 第一层的key存储服务名:InstanceInfo中的appName属性, 第二层的key存储实例名: Instancelnfo中的InstanceId属性。
Eureka客户端配置
Eureka服务端更多地类似于一个现成产品,这些参数均以eureka.server 作为前缀,暂不讨论。下面为客户端的两类配置信息。
服务注册相关的配置信息
包括服务注册中心的地址、 服务获取的间隔时间、 可用区域等。
(1)参数前缀为eureka.client
(2)配置信息被疯转为EurekaClientConfigBean
(3)指定注册中心
当构建了高可用的服务注册中心集群时, 我们可以为参数的 value 值配置多个注册中
心的地址(通过逗号分隔)。它的配置值存储在HashMap 类型中,key为Zone名称,value为url。
eureka.client.serviceUrl.defaultZone=http://peerl: 1111/eureka/, http://peer2:1112/eureka/服务实例相关的配置信息
包括服务实例的名称、IP地址、 端口号、 健康检查路径等。
(1)前缀为eureka.instance
(2)被封装为EurekaInstanceConfigBean
(3)元数据
· 定义:它是Eureka 客户端在向服务注册中心发送注册请求时, 用来描述自身服务信息的对象, 其中包含了一些标准化的元数据, 比如服务名称、实例名称、实例IP、实例端口等用于服务治理的重要信息;以及一些用于负载均衡策略或是其他特殊用途的自定义元数据信息。
· 在真正进行服务注册的时候, 还是会包装成com.netflix.appinfo.Instancelnfo 对象发送给Eureka 服务端。类定义中,Map<String, String> metadata= new ConcurrentHashMap<String, String> ()是自定义的元数据信息, 而其他成员变量则是标准化的元数据信息。
(4)我们可以通过eureka.instance.<properties>=<value>的格式对标准化元数据直接进行配置, 其中 <properties>就是 EurekainstanceConfigBean对象中的成员变量名 。 而对于自定义 元数据, 可以通过 eureka.instance.metadataMap.<key>=<value>的格式来进行配置, 比如:
eureka.instance.metadataMap.zone=shanghai(6)常用元数据配置
· 实例名
即Instanceinfo 中的instanceId参数, 它是区分同一服务中不同实例的唯一 标识。默认规则:
${spring.cloud.client.hostname}:
${spring.application.name}:
${spring.application.instance—id: ${server.port}}· 端点配置
状态页和健康检查的 URL 在 Spring Cloud Eureka 中默认使用了spring-boot-actuator 模块提供的/info 端点和/health 端点。
endpoints.info.path=/appinfo
endpoints.health.path=/checkHealth
eureka.instance.statusPageOrlPath=/${endpoints.info.path}
eureka.instance.healthCheckOrlPath=/${endpoints.health.path}· 健康检测
默认情况下,Eureka中各个服务实例的健康检测并不是通过spring-boot-actuator模块的/health 端点来实现的, 而是依靠客户端心跳的方式来保持服务实例的存活。通过简单的配置, 把Eureka客户端的健康检测交给spring-boot-actuator模块的/health端点, 以实现更加全面的健康状态维护。
代码
Eureka Server
(1)依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Dalston.RC1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>(2)配置文件
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/(3)启动
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}配置了context-path后,就需要输入localhost:8761/context-path打开eureka界面。
服务提供者
(1)依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>(2)配置文件
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 8762
spring:
application:
name: service-hi(3)发布服务
@SpringBootApplication
@EnableEurekaClient
@RestController
public class ServiceHiApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceHiApplication.class, args);
}
@Value("${server.port}")
String port;
@RequestMapping("/hi")
public String home(@RequestParam String name) {
return "hi " + name + ",i am from port:" + port;
}
}Spring Cloud Ribbon
概念
是一个基于 HTTP 和 TCP 的客户端负载均衡工具,它基于 Netflix Ribbon 实现。 通过 Spring Cloud 的封装, 可以让我们轻松地将面向服务的REST 模板请求自动转换成客户端负载均衡的服务调用。
客户端负载均衡
(1)服务提供者只需要启动多个服务实例并注册到一个注册中心或是多个相关联的服务注册中心。
(2)服务消费者直接通过调用被@LoadBalanced 注解修饰过的 RestTemplate 来实现面向服务的接口调用。
RestTemplate
RestTemplate对象会使用 Ribbon 的自动化配置, 同时通过配置@LoadBalanced 还能够开启客户端负载均衡。下面我们将详细介绍 RestTemplate 针对几种不同请求类型和参数类型的服务调用实现。
GET
(1)getForEntity 函数。该方法返回的是 ResponseEntity, 该对象是 Spring对 HTTP 请求响应的封装, 其中主要存储了 HTTP 的几个重要元素。
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<User> responseEntity = restTemplate.getForEntity("http://USER-SERVICE/user?name= {l}", User.class, "didi");
User body= responseEntity.getBody();(2)getForObject 函数。该方法可以理解为对 getForEntity 的进一步封装,它通过 HttpMessageConverterExtractor 对 HTTP 的请求响应体 body内容进行对象转换, 实现请求直接返回包装好的对象内容。
RestTemplate restTemplate = new RestTemplate();
User result = restTemplate.getForObject(uri, User.class);POST
(1)postForEntity 函数。 该方法同 GET 请求中的 getForEntity 类似, 会在调用后返回 ResponseEntity
RestTemplate restTemplate = new RestTemplate();
User user = new User("didi", 30);
ResponseEntity<String> responseEntity =restTemplate.postForEntity("http://USER-SERVICE/user", user, String.class);
String body = responseEntity.getBody();PUT请求
RestTemplate restTemplate = new RestTemplate ();
Long id = 100011;
User user = new User("didi", 40);
restTemplate.put("http://USER-SERVICE/user/{l}", user, id);DELETE请求
RestTemplate restTemplate = new RestTemplate();
Long id= 10001L;
restTemplate.delete("http://USER-SERVICE/user/{1)", id);源码分析

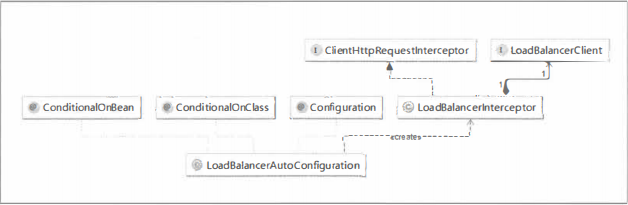
负载均衡器
在ILoadBalancer接口中定义了 一个客户端负载均衡器需要的一系列抽象操作,是具体的实现了客户端负载均衡。
public interface ILoadBalancer {
public void addServers(Lis七<Server> newServers);
public Server chooseServer(Objectkey);
public void markServerDown(Server server);
public List<Server> getReachableServers () ;
public List<Server> getA11Servers();
}• addServers: 向负载均衡器中维护的实例列表增加服务实例。
• chooseServer: 通过某种策略, 从负载均衡器中挑选出 一个具体的服务实例。
• markServerDown: 用来通知和标识负载均衡器中某个具体实例已经停止服务, 不然负载均衡器在下一次获取服务实例清单前都会认为服务实例均是正常服务的。
• getReachableServers: 获取当前正常服务的实例列表。
• getAllServers: 获取所有已知的服务实例列表, 包括正常服务和停止服务的实例。
(1)AbstractLoadBalancer 抽象实现
(2)BaseLoadBalancer 是Ribbon 负载均衡器的基础实现类
定义了负载均衡的处理规 则IRule 对 象, 从 BaseLoadBalancer中chooseServer (Object key) 的实现源码, 我们可以知道, 负载均衡器实际将服务实例选择任务委托给了 IRule 实例中的 choose 函数来实现。 而在这里, 默认初始化了 RoundRobinRule 为IRule 的实现对象。 RoundRobinRule 实现了最基本且常用的线性负载均衡规则。
(3)DynamicServerlistloadBalancer 继承于BaseLoadBalancer 类, 它是对基础负载均衡器的扩展
(4)ZoneAwareloadBalancer 是对 DynamicServerListLoadBalancer的扩展
负载均衡策略
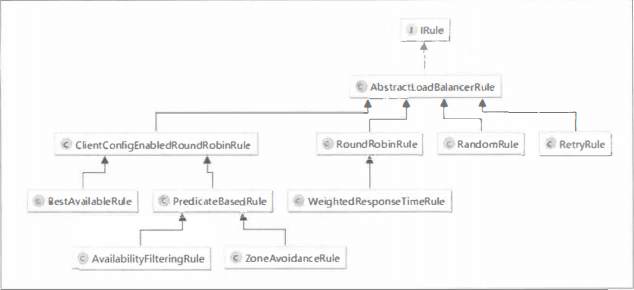
实现IRule接口来制定负载均衡策略。
(1)Random Rule 从服务实例清单中随机选择 一个服务实例
(2)RoundRobinRule 按照线性轮询的方式依次选择每个服务实例
(3)RetryRule 具备重试机制的实例选择。在其内部还定义了 一个 IRule 对象,默认使用了 RoundRobinRule 实例。
(4)Weighted Response TimeRule 对 RoundRobinRule 的扩展, 增加了根据实例的运行情况来计算权重, 并根据权重来挑选实例, 以达到更优的分配效果
(5)ClientConfigEnabledRoundRobinRule 在它的内部定义了一个 RoundRobinRule 策略, 而 choose函数的实现也正是使用了 RoundRobinRule 的线性轮询机制, 所以它实现的功能实际上与 RoundRobinRule 相同。
(6)BestAvailableRule 找出并发请求数最小的一个, 即该策略的特性是可选出最空闲的实例
(7)PredicateBasedRule 抽象策略。先通过子类中实现的 Predicate 逻辑来过滤一部分服务实例, 然后再以线性轮询的方式从过滤后的实例清单中选出一个
(8)AvailabilityFilteringRule 继承自上面介绍的抽象策略 PredicateBasedRule
(9)ZoneAvoidanceRule 是PredicateBasedRule 的具体实现类
重试机制
对比ZooKeeper
(1)Spring Cloud Eureka实现的服务治理机制强调了CAP原理中的AP, 即可用性与可靠性
(2)ZooKeeper强调CP( 一致性、可靠性)
整合 Spring Retry
(1)原因
Eureka则会因为超过85%的实例丢失心跳而会触发保护机制,注册中心将会保留此时的所有节点, 以实现服务间依然可以进行互相调用的场景, 即使其中有部分故障节点, 但这样做可以继续保障大多数的服务正常消费。
SpringCloud整合了SpringRetry来增强RestTernplate的重试能力, 对于开发者来说只需通过简单的配置, 原来那些通过RestTemplate 实现的服务访问就会自动根据配置来实现重试策略。
(2)原理
当访问到故障请求的时候, 它会再尝试访问 一次当前实例(次数由MaxAutoRetries配置), 如果不行, 就换 一个实例进行访问, 如果还是不行, 再换一次实例访问(更换次数由MaxAutoRediesNextServer配置), 如果依然不行, 返回失败信息。
(3)配置
spring.cloud.loadbalancer.retry.enabled=true
hystrix.command.default.execution.isolation.thread.timeoutinMilliseconds=10000
hello-service.ribbon.ConnectTimeout=250
hello-service.ribbon.ReadTimeout=1000
hello-service.ribbon.OkToRetryOnAllOperations=true
hello-service.ribbon.MaxAutoRetriesNex七Server=2
hello-service.ribbon.MaxAutoRetries=1代码
(1)依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
</dependency>(2)配置文件
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 8764
spring:
application:
name: service-ribbon(3)Service
@Service
public class HelloService {
@Autowired
RestTemplate restTemplate;
public String hiService(String name) {
return restTemplate.getForObject("http://SERVICE-HI/hi?name="+name,String.class);
}
}(4)Controller
@RestController
public class HelloControler {
@Autowired
HelloService helloService;
@RequestMapping(value = "/hi")
public String hi(@RequestParam String name){
return helloService.hiService(name);
}
}(5)启动
@EnableAutoConfiguration
@ComponentScan(basePackages={"com.itmayiedu.controller","com.itmayiedu.service","com.itmayiedu.app"})
@EnableDiscoveryClient
public class ServiceRibbonApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceRibbonApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
}Spring Cloud Hystrix
概念
当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回 一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
工作流程
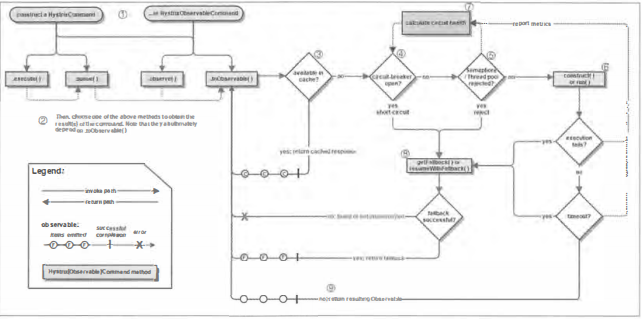
(1)创建HystrixCommand或HystrixObservableCommand对象
• HystrixCommand: 用在依赖的服务返回单个操作结果的时候。
• HystrixObservableCommand: 用在依赖的服务返回多个操作结果的时候。
采用“命令模式”设计,用来表示对依赖服务的操作请求, 同时传递所有需要的参数。
(2)命令执行
Hystrix在执行时会根据创建的Command对象以及具体的情况来选择4个执行方式中的一个执行。
• execute (): 同步执行,从依赖的服务 返回一个单一的结果对象, 或是在发生错误的时候抛出异常。
• queue (): 异步执行,直接返回一个Future对象, 其中包含了服务 执行 结束时要返回的单 一 结果对象。
R value = command. execute() ;
Future<R> fValue = command. queue() ;而HystrixObservableCommand实现了另外两种 执行方式。
• observe () : 返回Observable对象,它代表了操作的多个结果,它是 一个Hot Observable。
• toObservable(): 同样会返回Observable对象, 也代表了操作的多个结果,但它返回的是 一个Cold Observable。
Observable<R> ohValue = command.observe(};
Observable<R> ocValue = command. toObservable(};在Hystrix的底层实现中大量地使用了RxJava,。rxjava是一个异步框架,功能和handler类似,特点是链式调用,逻辑简单,使用了观察者-订阅者模式。参考资料:RXJAVA - 简书
(3)结果是否被缓存
若当前命令的请求缓存功能是被启用的, 并且该命令缓存命中, 那么缓存的结果会立即以Observable 对象的形式 返回。
(4)断路器是否打开
如果断路器是打开的,那么Hystrix不会执行命令,而是转接到fallback处理逻辑。如果断路器是关闭的, 那么Hystrix继续执行第5步,检查是否有可用资源来 执行命令。
(5)线程池I请求队列I信号量是否占满
(6)HystrixObservableCommand.construct()或HystrixCommand.run()
采取什么样的方式去请求依赖服务。
(7)计算断路器的健康度
Hystrix会将 “ 成功 ”、 “ 失败”、 “ 拒绝”、 “ 超时 ” 等信息报告给断路器,而断路器会维护一组计数器来统计这些数据。
(8) fallback处理
当命令执行失败的时候, Hystrix会进入fallback尝试回退处理, 我们通常也称该操作为 “ 服务降级”。
(9)返回成功的响应
断路器
HystrixCircuitBreaker
public interface HystrixCircuitBreaker {
public static class Factory { ... }
static class HystrixCircuitBreakerimpl implements HystrixCircuitBreaker { ... }
Static class NoOpCircuitBreaker implements HystrixCircuitBreaker { ... }
public boolean allowRequest();
public boolean isOpen();
void markSuccess();
}详解
(1)静态类 Factory 中维护了一个 Hystrix 命令与 HystrixCircuitBreaker 的关系集合: ConcurrentHashMap<String, HystrixCircui七Breaker> circuitBreakersByCommand, 其中 String 类型的 key 通过 HystrixCommandKey 定义,每一个 Hystrix 命令需要有一个 key 来标识, 同时一个 Hystrix 命令也会在该集合中找到它对应的断路器 HystrixCircuitBreaker 实例.
(2)isOpen (): 判断断路器的打开/关闭状态
· 如果它的请求总数(QPS)在预设的阙值范围内就返回 false, 表示断路器处于未打开状态。该阙值的配置参数为circuitBreakerRequestVolumeThreshold,默认值为20。
· 如果错误百分比在阑值范围内就返回 false, 表示断路器处于未打开状态。该阙值的配置参数为 circuitBreakerErrorThresholdPercentage, 默认值为50。
(3)allowRequest(): 判断请求是否被允许。
(4)markSuccess(): 该函数用来在 “ 半开路” 状态时使用。
若Hystrix 命令调用成功,通过调用它将打开的断路器关闭, 并重置度量指标对象。
依赖隔离
(1)概念
Hystrix 使用该模式实现线程池的隔离,它会为每一个依赖服务创建一个独立的线程池, 这样就算某个依赖服务出现延迟过高的情况, 也只是对该依赖服务的调用产生影响, 而不会拖慢其他的依赖服务。
(2)在 Hystrix中除了可使用线程池之外, 还可以使用信号量来控制单个依赖服务的并发度, 信号量的开销远比线程池的开销小, 但是它不能设置超时和实现异步访问。 所以,只有在依赖 服 务是足够可靠的情况 下才使用信号量
其他
(1)请求缓存
在高并发的场景之下, Hystrix 中提供了请求缓存的功能, 我们可以方便地开启和使用请求缓存来优化系统, 达到减轻高并发时的请求线程消耗、 降低请求响应时间的效果。
在实现 HystrixCommand 或HystrixObservableCommand 时, 通过重载 getCacheKey ()方法来开启请求缓存。
(2)请求合并
在高并发的情况之下, 因通信次数的增加, 总的通信时间消耗将会变得不那么理想。 同时, 因为依赖服务的线程池资源有限,将出现排队等待与响应延迟的清况。为了优化这两个问题, Hystrix 提供了 HystrixCollapser 来实现请求的合并,以减少通信消耗和线程数的占用。
HystrixCollapser实现 了在 HystrixCommand 之前放置一个合并处理器, 将处于一个很短的时间窗(默认 10 毫秒)内对同一依赖服务的多个请求进行整合并以批量方式发起请求的功能(服 务提供方也需 要 提供相应的批 量实 现 接口)。
代码
(1)继承式
public class UserCommand extends Hys七rixCommand<User> {
private RestTemplate restTemplate;
private Long id;
public UserCommand(Setter se七ter, RestTemplate restTemplate, Long id) {
super(setter);
this.restTemplate = restTemplate;
this.id= id;
}
@Override
protected User run() {
return restTemplate.getForObject("http://USER-SERVICE/users/{1}",User.class, id);
}
}• 同步执行:
User u = new UserCommand (restTemplate, lL) . execute ();。
• 异步执行:
Future
futureUser = new UserCommand (restTemplate,lL) .queue(); 。 异步执行的时候, 可以通过对返回的 futureUser 调用get 方法来获取结果
(2)注解式
// 同步
public class UserService {
@Autowired
private RestTemplate restTemplate;
@HystrixCommand
public User getUserByid(Long id) {
return restTemplate.getForObjec七("http://USER-SERVICE/users/{1}",User.class, id);
}
}
// 异步
@HystrixCommand
public Future<User> getUserByidAsync(final String id) {
return new AsyncResult<User>() {
@Override
public User invoke() {
return restTemplate.getForObject("http://USER-SERVICE/users/{1}",User.class, id);
}
};
}Spring Cloud Feign
概念
它基于 Netflix Feign 实现,整合了 Spring Cloud Ribbon 与 Spring Cloud Hystrix,它还提供了一种声明式的 Web 服务客户端定义方式。Spring Cloud Feign 具备可插拔的注解支持,包括 Feign 注解和 JAX-RS 注解。
继承特性
在工程安排上,将服务接口的定义从代码中剥离出来作为单独的maven工程模块,让服务提供者和服务消费者依赖此工程即可。
· 服务接口,可以写上带context-path的mappingurl。
· provider在controller层实现接口,并需要覆盖服务接口的mappingurl,去掉context-path部分
· Feign在service层定义一个接口并继承服务接口即可。不需要使用@Service注解了。
配置
由于SpringCloud Feign的客户端负载均衡是通过SpringCloud Ribbon实现的,所以我
们可以直接通过配置Ribbon客户端的方式来自定义各个服务客户端调用的参数。
(1)全局配置
使用ribbon.<key>=<value>的方式来设置ribbon的各项默认参数。
ribbon.ConnectTimeout=500
ribbon.ReadTimeout=5000(2)指定服务配置
采用<client>.Ribbon.key=value 的格式进行设置。
HELLO-SERVICE.ribbon.ConnectTimeout=500
HELLO-SERVICE.ribbon.ReadTimeout=2000
HELLO-SERVICE.ribbon.OkToRetryOnAllOperations=true
HELLO-SERVICE.ribbon.MaxAutoRetriesNextServer=2
HELLO-SERVICE.ribbon.MaxAutoRetries=1(3)重试机制
在 Spring Cloud Feign中默认实 现了 请求的重试机制, 而上面我 们对于HELLO-SERVICE 客户端的配置内容就是对于请求超时以及重试机制配置的详情。同Ribbon配置。
(4)Hystrix配置
默认情况下,SpringCloud Feign会为将所有Feign客户端的方法都封装到Hystrix命令中进行服务保护。
需要确认 feign.hystrix.enabled参数没有被设置为false, 否则该参数设置会关闭Feign客户端的Hystrix支持。
代码
(1)依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-feign</artifactId>
</dependency>(2)配置文件
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 8765
spring:
application:
name: service-feign(3)定义Feign接口
@FeignClient(value = "service-hi")
public interface SchedualServiceHi {
//这里注意,url要写上client的context-path
@RequestMapping(value = "/hi", method = RequestMethod.GET)
String sayHiFromClientOne(@RequestParam(value = "name") String name);
}(4)Controller
@RestController
public class HiController {
@Autowired
SchedualServiceHi schedualServiceHi;
@RequestMapping(value = "/hi",method = RequestMethod.GET)
public String sayHi(@RequestParam String name){
return schedualServiceHi.sayHiFromClientOne(name);
}
}(5)启动
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
public class SericeFeign {
public static void main(String[] args) {
SpringApplication.run(SericeFeign.class, args);
}
}Spring Cloud Zuul
概念
是SpringCloud基于NetflixZuul实现的API网关组件。
API网关是一个更为智能的应用服务器, 它的定义类似于面向对象设计模式中的Facade模式, 它的存在就像是整个微服务架构系统的门面一样,所有的外部客户端访问都需要经过它来进行调度和过滤。它除了要实现请求路由、 负载均衡、 校验过滤等功能之外, 还需要更多能力, 比如与服务治理框架的结合、 请求转发时的熔断机制、 服务的聚合等一系列高级功能。
请求路由
传统路由
(1)配置
// 单实例
zuul.routes.api-a-url.path=/api-a-url/**
zuul.routes.api-a-url.url=http://localhost:8080/
// 多实例
zuul. routes. user - service. path=/user - service/**
zuul. routes. user - service. serviceid=user - service
ribbon.eureka.enabled=false
user - service. ribbon. listOfServers=http://localhost:8080/,http://localhost:8081/ 所有符合/api-a-url/**规则的访问都将被路由 转发到http://localhost:8080/地址上。当我们 访问http://localhost:5555/api-a-url/hello的时候,API网关服务会将该请求路由到http://localhost: 8080/hello 提供的微服务接口上。
(2)配 置属性zuul.routes.api-a-url.path中的api-a-url部分为路由的名字, 可以任意定义,但是一组path和url 映射关系的路由名要相同。
面向服务路由
SpringCloud Zuul实现了与Spring Cloud Eureka的无缝整合, 我们可以让路由的path不是映射具体的url, 而是让它映射到某个具体的服务 , 而具体的url则交给Eureka的服务发现机制去自动维护。
(1)配置
zuul.routes.api-a.path=/api-a/**
zuul.routes.api-a.serviceid=hello-service
zuul.routes.api-b.path=/api-b/**
zuul.routes.api-b.serviceid=feign-consumer
eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/请求过滤
为了实现对客户端请求的安全校验和权限控制,Zuul 允许开发者在API网关上通过定义过滤器来实现对请求的拦截与过滤,实现的方法非常简单,我们只需要继承 ZuulFilter 抽象类并实现它定义的4个抽象函数就可以完成对请求的拦截和过滤了。为其创建具体的Bean就可以启动了。
public class AccessFil ter extends ZuulFil ter {
private static Logger log= LoggerFactory.getLogger(AccessFilter.class);
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder () {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
log.info("send {} request to{}", reques七.getMethod () ,request.getRequestURL().toString());
Object accessToken = request.getParameter("accessToken");
if(accessToken == null) {
log.warn("access token is empty");
ctx.setSendZuulResponse(false);
Ctx.setResponseStatusCode(401);
return null;
}
log.info("access token ok");
return null;
}
} • filterType: 过滤器的类型, 它决定过滤器在请求的哪个生命周期中执行。 这里定义为pre, 代表会在请求被路由之前执行。在 Zuul 中默认定义了 4 种不同生命周期的过滤器类型:
· pre: 可以在请求被路由之前调用。
· routing: 在路由请求时被调用。
· post: 在 routing 和 error 过滤器之后被调用。
· error: 处理请求时发生错误时被调用
• filterOrder: 过滤器的执行顺序。 当请求在一个阶段中存在多个过滤器时, 需要根据该方法返回的值来依次执行。
• shouldFilter: 判断该过滤器是否需要被执行。 这里我们直接返回了true, 因此该过滤器对所有请求都会生效。 实际运用中我们可以利用该函数来指定过滤器的有效范围。
• run: 过滤器的具体逻辑。 这里我们通过ctx.setSendZuulResponse(false)令zuul过滤该请求, 不对其进行路由, 然后通过 ctx.setResponseStatusCode (401)设置了其返回的错误码, 当然也可以进 一步优化我们的返回, 比如, 通过ctx.setResponseBody(body)对返回的body内容进行编辑等。
路由详解
面向服务路由的默认规则
(1)Zuul为Eureka中的每个服务都自动创建一个默认路由规则, 这些默认规则的path会使用service Id配置的服务名作为请求前缀。
zuul.routes.user-service.path=/user-service/**
zuul.routes.user-service.serviceid=user-serviceuser-service为服务名。
(2)可以使用zuul.ignored-services参数来设置一个服务名匹配表达式来定义不自动创建路由的规则。 Zuul在自动创建服务路由的时候会根据该表达式来进行判断, 如果服务名匹配表达式 , 那 么 Zuul 将跳过该服务,不为其创建路由规则。
路径匹配
(1) 在Zuul中, 路由匹配的路径表达式采用了Ant风格定义。Ant风格的路径表达式使用起来非常简单, 它一共有下面这三种通配符。


(2)在使用路由规则匹配请求路径的时候是通过线性遍历的方式,在请求路径获取到第一个匹配的路由规则之后就返回并结束匹配过程。所以当存在多个匹配的路由规则时, 匹配结果完全取决于路由规则的保存顺序。
LinkedHashMap<String, ZuulRoute> routesMap = new LinkedHashMap<String,ZuulRoute>();路由规则的保存是有序的, 而内容的加载是通过遍历配置文件中路由规则依次加入的,所以导致问题的根本原因是对配置文件中内容的读取。
路由前缀
为了方便全局地为路由规则增加前缀信息,Zuul提供了 zuul.prefix 参数来进行设置。比如,希望为网关上的路由规则都增加/api前缀,那么我们可以在配置文件中增加配置: zuul.prefix=/api。 另外, 对于代理前缀会默认从路径中移除,我们可以通过设置zuul.stripPrefix=false 来关闭该移除代理前缀的动作,也可以通过 zuul.routes.<route>.strip-prefix=true 来对指定路由关闭移除代理前缀的动作。
本地跳转
通过url 中使用forward来指定需要跳转的服务器资源路径。
zuul.routes.api-a.path=/api-a/**
zuul.routes.api-a.url=http://localhost:8001/
zuul.routes.api-b.path=/api-b/**
zuul.routes.api-b.url=forward:/local@RestController
public class HelloController {
@RequestMapping ("/local /hello")
public String hello() {
return "Hello World Local";
}
}Cookie头信息
默认情况下, Spring Cloud Zuul在请求路由时, 会过滤掉HTTP请求头信息中的 一些敏感信 息, 防止它们被传递到下游的外部服务器。 默认的敏感头信息通过zuul.sensitiveHeaders参数定义,包括Cookie、Set-Cookie、Authorization三个属性。所以, 我们在开发Web项目时常用的Cookie在 Spring Cloud Zuul网关中默认是不会传递的。解决方法如下:
#方法一:对指定路由开启自定义敏感头
zuul.routes.<router>.customSensitiveHeaders=true#方法二:将指定路由的敏感头设置为空
zuul.routes.<router>.sensitiveHeaders=
重定向问题
(1)现象
通过网关访问登录页面并发起登录请求, 但是登录成功之后, 我们跳转到的页面URL却是 具体Web应用实例的地址, 而不是通过网关的路由地址。这个问题非常严重, 因为使用API网关的一个重要原因就是要将网关作为统一入口, 从而不暴露所有的内部服务细节
(2)解决
Zuul中增加了一个参数配置,能够使得网关在进行路由转发前为请求设置Host头信息,以标识最初的服务端请求地址。 具体配置方式如下:
zuul.addHostHeader=true
Hystrix和Ribbon支持
spring-cloud-starter-zuul依赖自身就包含了对 spring-cloud-starter-hystrix 和 spring-cloud-starter-Ribbon模块的依赖, 所以 Zuul天生就拥有线程隔离和断路器的自我保护功能,以及对服务调用的客户端负载均衡功能。
过滤器
在Spring Cloud Zuul中实现的过滤器必须包含4个基本特征: 过滤类型、 执行顺序、执行条件、 具体操作。 这些元素看起来非常熟悉,实际上它就是ZuulFiler接口中定义的4个抽象方法。
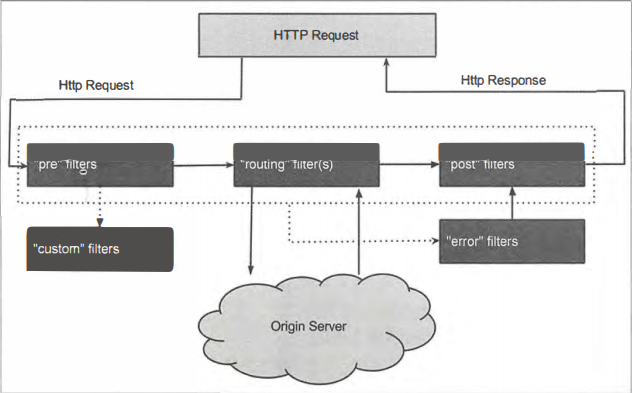
(1)第一个阶段pre, 在这里它会被pre类型的过滤器进行处理, 该类型过滤器的主要目的是在进行请求路由之前做一些前置加工, 比如请求的校验等
(2)请求进入第二个阶段routing, 也就是之前说的路由请求转发阶段, 请求将会被routing类型过滤器处理。这里的具体处理 内容就是将外部请求转发到具体服务实例上去的过程, 当服务实例将请求结果都返回之后, routing 阶段完成
(3)请求进入第三个阶段post。 此时请求将会被post类型的过滤器处理, 这些过滤器在处理的时候不仅可以获取到请求信息, 还能获取到服务实例的返回信息, 所以在 post类型的过滤器 中, 我们可以对处理结果进行 一些加工或转换等内容
(4)还有一个特殊的阶段error, 该阶段只有 在上述三个阶段中发生异常的时候才会触发,但是它的最后流向还是 post类型的过滤器, 因为它需要通过post过滤器将最终结果返回给请求客户端
动态加载
(1)概念
在微服务架构中, 由于API网关服务担负着外部访问统一入口的重任, 它同其他应用不同, 任何关闭应用和重启应用的操作都会使系统对外服务停止, 对于很多7 X 24小时服务的系统来说, 这样的情况是绝对不被允许的。 所以, 作为最外部的网关, 它必须具备动态更新内部逻辑的能力, 比如动态修改路由规则、 动态添加/删除过滤器等。
(2)动态路由
对于如何实现Zuul的动态路由,我们很自然地会将它与SpringCloud Config的动态刷新机制联系到一起。 只需将API网关服务的配置文件通过Spring Cloud Config连接的Git仓库存储和管理, 我们就能轻松实现动态刷新路由规则的功能。
(3)动态过滤器
请求路由通过配置文件就能实现,而请求过滤则都是通过编码实现。 所以,对于实现请求过滤器的动态加载, 我们需要借助基于NM实现的动态语言的帮助, 比如Groovy。
Spring Cloud Config
概念
Spring Cloud Config 是 Spring Cloud 团队创建的一个全新项目,用来为分布式系统中的基础设施和微服务应用提供集中化的外部配置支持, 它分为服务端与客户端两个部分。 其中服务端也称为分布式配置中心。
Spring Cloud Config 实现的配置中心默认采用 Git 来存储配置信息, 所以使用 Spring Cloud Config 构建的配置服务器, 天然就支持对微服务应用配置信息的版本管理, 并且可以通过 Git 客户端工具来方便地管理和访问配置内容。
配置文件
调用方式
根据url 会映射对应的配置文件
• /{application}/{profile} [/{label}]
• /{application}一{profile}. yrnl
• /{label}/{application}-{profile}.yrnl
• /{application}-{profile}.properties
• /{label}/{application}-{profile}.properties
缓存
获取配置文件后,通过Git在本地仓库暂存。可以有效防止当 Git 仓库出现故障而引起无法加载配置信息的情况。
服务端架构
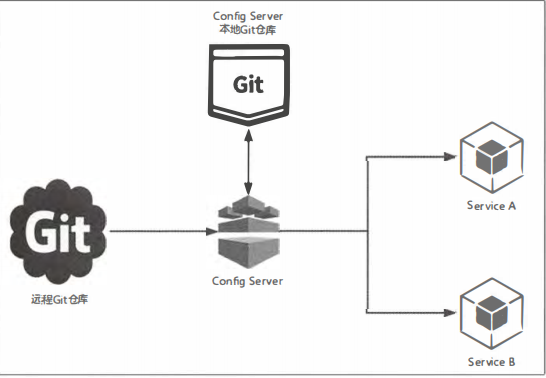
• 远程 Git 仓库: 用来存储配置文件的地方
• Config Server: 这是我们上面构建的分布式配置中心, config-server工程, 在该工程中指定了所要连接的Git仓库位置以及账户、 密码等连接信息。
• 本地Git仓库: 在Config Server的文件系统中, 每次客户端请求获取配置信息时,Config Server从Git仓库中获取最新配置到本地,然后在本地Git仓库中读取并返回 。当远程仓库无法获取时, 直接将本地内容返回。
设置属性spring.profiles.active= native, Config Server会默认从应用的 src/main/resource 目录下搜索配置文件。 如果需要指定搜索配置文件的路径, 我们可以通过spring.cloud.config.server.native.searchLocations 属性来指定具体的配置文件位置。
• Service A、 Service B: 具体的微服务应用, 它们指定了ConfigServer的地址, 从而实现从外部化获取应用 自己要用的配置信息。 这些应用在启动的时候, 会向Config Server请求获取配置信息来进行加载。
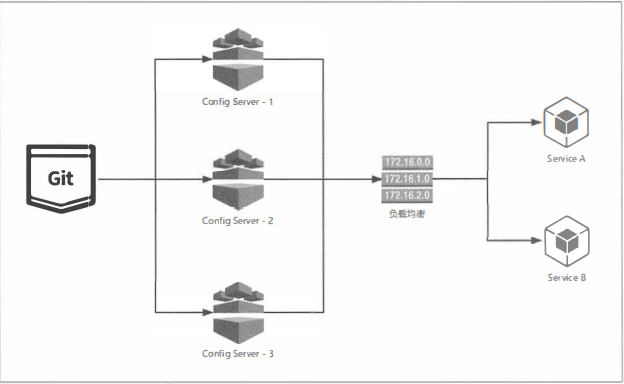
服务端高可用配置
(1) 传统模式: 不需要为这些服务端做任何额外的配置, 只需要遵守一个配置规则, 将所有的 Config Server 都指向同一个 Git 仓库, 这样所有的配置内容就通过统一的共享文件系统来维护。而客户端在指定 Config Server 位置时,只需要配置 Config Server上层的负载均衡设备地址即可, 就如下图所示的结构。
(2)服务模式:除了上面这种传统的实现模式之外, 我们也可以将 Config Server 作为一个普通的微服务应用,纳入 Eureka 的服务治理体系中。 这样我们的微服务应用就可以通过配置中心的服务名来获取配置信息, 这种方式比起传统的实现模式来说更加有利于维护, 因为对于服务端的负载均衡配置和客户端的配置中心指定都通过服务治理机制一并解决了, 既实现了高可用, 也实现了自维护。
客户端
配置方式
(1)URI 指定配置中心
Spring Cloud Config的客户端在启动的时候,默认会从工程的classpath中加载配置信息并启动应用。 只有当我们配置spring.cloud.config.uri 的时候, 客户端应用才会尝试连接Spring Cloud Config的服务端来获取远程配置信息并初始化Spring环境配置。 同时, 我们必须将该参数配置在bootstrap.properties、 环境变量或是其他优先级高于应用Jar包内的配置信息中,才能正确加载到远程配置。
(2)服务化配置中心
将ConfigServer注册到服务中心, 并通过服务发现来访问ConfigServer并获取Git仓库中的配置信息。
失败快速响应与重试
Spring Cloud Config的客户端会预先加载很多其他信息,然后再开始连接ConfigServer 进行属性的注入。要实现客户端优先判断ConfigServer获取是否正常, 并快速响应失败内容, 只需在bootstrap.properties中配置参数spring.cloud.config.failFast= true即可。
动态刷新配置
通过spring-boot-starter-actuator监控模块,其中包含了/refresh 端点的实现,该端点将用于实现客户端应用配置信息的重新获取与刷新。当有Git提交变化时, 就给对应的配置主机发送/refresh请求来实现配置信息的实时更新。



