目录
Docker简介
Docker体系结构
Docker内部组件
镜像管理
容器管理
管理应用程序数据
Dockerfile
镜像仓库
需要注意的问题
9.1 Mysql需要实现容器化吗?
参考资料
- 李振良Docker
- Mysql要不要实现Docker容器化
Docker简介
Docker概述
Docker是一个开源的应用容器引擎,使用Go语言开发,基于Linux内核的cgroup,namespace,Union Fs等技术,对应用进程进行封装隔离,并且独立与宿主机与其他进程,这种运行时封装的状态称为容器。
Docker理念是将应用及依赖包打包到一个可移植的容器中,可发布到任意Linux发行版Docker引擎上,使用沙箱机制运行程序,程序之间相互隔离。
虚拟机与容器区别


应用背景

Docker体系结构

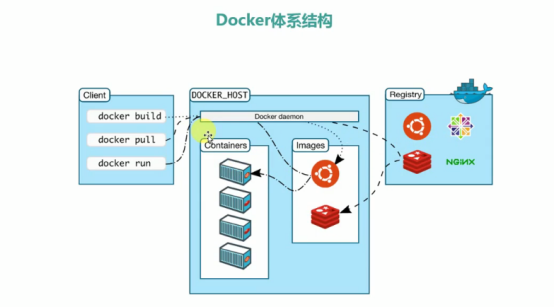
Docker客户端执行命令,Docker主机收到命令后,调用守护进程。若是拉取镜像操作,先从本地仓库拉取,没有的话再去Docker 仓库拉取。通过镜像即可启动容器。
Docker原理
Docker 底层的核心技术包括 Linux 上的命名空间(Namespaces)、控制组(Control groups)、Union 文件系统(Union file systems)和容器格式(Container format)。
我们知道,传统的虚拟机通过在宿主主机中运行 hypervisor 来模拟一整套完整的硬件环境提供给虚拟机的操作系统。虚拟机系统看到的环境是可限制的,也是彼此隔离的。 这种直接的做法实现了对资源最完整的封装,但很多时候往往意味着系统资源的浪费。 例如,以宿主机和虚拟机系统都为 Linux 系统为例,虚拟机中运行的应用其实可以利用宿主机系统中的运行环境。
我们知道,在操作系统中,包括内核、文件系统、网络、PID、UID、IPC、内存、硬盘、CPU 等等,所有的资源都是应用进程直接共享的。 要想实现虚拟化,除了要实现对内存、CPU、网络IO、硬盘IO、存储空间等的限制外,还要实现文件系统、网络、PID、UID、IPC等等的相互隔离。 前者相对容易实现一些,后者则需要宿主机系统的深入支持。
随着 Linux 系统对于命名空间功能的完善实现,程序员已经可以实现上面的所有需求,让某些进程在彼此隔离的命名空间中运行。大家虽然都共用一个内核和某些运行时环境(例如一些系统命令和系统库),但是彼此却看不到,都以为系统中只有自己的存在。这种机制就是容器(Container),利用命名空间来做权限的隔离控制,利用 cgroups 来做资源分配。
命名空间
Linux 内核中提供了 6 中隔离支持,分别是:IPC 隔离、网络隔离、挂载点隔离、进程编号隔离、用户和用户组隔离、主机名和域名隔离。
| Namespace | flag | 隔离内容 |
|---|---|---|
| IPC | CLONE_NEWIPC | IPC(信号量、消息队列和共享内存等)隔离 |
| Network | CLONE_NEWNET | 网络隔离(网络栈、端口等) |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| PID | CLONE_NEWPID | 进程编号 |
| User | CLONE_NEWUSER | 用户和用户组 |
| UTS | CLONE_NEWUTS | 主机名和域名 |
控制组
控制组是 Linux 内核的一个特性,主要用来对共享资源进行隔离、限制、审计等。只有能控制分配到容器的资源,才能避免当多个容器同时运行时的对系统资源的竞争。
CGroups 中有几个重要概念:
- cgroup:通过 CGroups 系统进行限制的一组进程。CGroups 中的资源限制都是以进程组为单位实现的,一个进程可以加入到某个进程组,从而受到相同的资源限制。
- task:在 CGroups 中,task 可以理解为一个进程。
- hierarchy:可以理解成层级关系,CGroups 的组织关系就是层级的形式,每个节点都是一个 cgroup。cgroup 可以有多个子节点,子节点默认继承父节点的属性。
- subsystem:更准确的表述应该是 ***resource controllers***,也就是资源控制器,比如 cpu 子系统负责控制 cpu 时间的分配。子系统必须应用(attach)到一个 hierarchy 上才能起作用。
其中最核心的是 ***subsystem***,CGroups 目前支持的 *subsystem* 包括:
- cpu:限制进程的 cpu 使用率;
- cpuacct:统计 CGroups 中的进程的 cpu 使用情况;
- cpuset:为 CGroups 中的进程分配单独的 cpu 节点或者内存节点;
- memory:限制进程的内存使用;
- devices:可以控制进程能够访问哪些设备;
- blkio:限制进程的块设备 IO;
- freezer:挂起或者恢复 CGroups 中的进程;
- net_cls:标记进程的网络数据包,然后可以使用防火墙或者 tc 模块(traffic controller)控制该数据包。这个控制器只适用从该 cgroup 离开的网络包,不适用到达该 cgroup 的网络包;
- ns:将不同 CGroups 下面的进程应用不同的 namespace;
- perf_event:监控 CGroups 中的进程的 perf 事件(注:perf 是 Linux 系统中的性能调优工具);
- pids:限制一个 cgroup 以及它的子节点中可以创建的进程数目;
- rdma:限制 cgroup 中可以使用的 RDMA 资源。
联合文件系统
联合文件系统是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。
联合文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
Docker 目前支持的联合文件系统包括
OverlayFS,AUFS,Btrfs,VFS,ZFS和Device Mapper。overlay2是目前 Docker 默认的存储驱动,以前则是aufs
数据存储
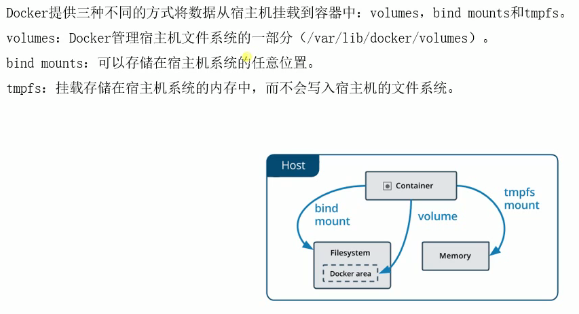
想要在 Docker 容器停止之后创建的文件依旧存在,也就是将文件在宿主机上保存。那么有两种方式:volumes、bind mounts。
数据卷volumes
数据卷 可以在容器之间共享和重用
对 数据卷 的修改会立马生效
对 数据卷 的更新,不会影响镜像
数据卷 默认会一直存在,即使容器被删除
Volumes 会把文件存储到宿主机的指定位置,在 Linux 系统上这个位置为 /var/lib/docker/volumes/。这些文件只能由 Docker 进程进行修改,是 docker 文件持久化的最好的方式。- 启动挂载数据卷的容器
在用 docker run 命令的时候,使用 --mount 标记来将 数据卷 挂载到容器里。在一次 docker run 中可以挂载多个 数据卷。
例如创建一个名为 web 的容器,并加载一个名为my-vol的 数据卷 到容器的 /usr/share/nginx/html 目录。
$ docker run -d -P \
--name web \
# -v my-vol:/usr/share/nginx/html \
--mount source=my-vol,target=/usr/share/nginx/html \
nginx:alpine在主机里使用以下命令可以查看 web 容器的信息
$ docker inspect web数据卷 信息在 “Mounts” Key 下面
"Mounts": [
{
"Type": "volume",
"Name": "my-vol",
"Source": "/var/lib/docker/volumes/my-vol/_data",
"Destination": "/usr/share/nginx/html",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
],挂载主机目录 bind mounts
使用 --mount 标记可以指定挂载一个本地主机的目录到容器中去。
Docker 挂载主机目录的默认权限是 读写,用户也可以通过增加 readonly 指定为 只读。
bind mounts 可以将文件存储到宿主机上面任意位置,而且别的应用程序也可以修改。
$ docker run -d -P \
--name web \
# -v /src/webapp:/usr/share/nginx/html \
--mount type=bind,source=/src/webapp,target=/usr/share/nginx/html \
nginx:alpine"Mounts": [
{
"Type": "bind",
"Source": "/src/webapp",
"Destination": "/usr/share/nginx/html",
"Mode": "",
"RW": true,
"Propagation": "rprivate"
}
],镜像、容器和仓库
Docker 包括三个基本概念:
镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。
Docker 容器通过 Docker 镜像来创建。
镜像
Docker 提供了一个很简单的机制来创建镜像或者更新现有的镜像,用户甚至可以直接从其他人那里下载一个已经做好的镜像来直接使用。
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变
镜像的构建是分层的,不同于ios那样的打包系统,docker的镜像只是一个虚拟的概念,实际上它并不是由一个文件组成的而是由一组文件组成的。
镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。
在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉
镜像常见操作:
docker search [镜像名称]:搜索Docker Hub(镜像仓库)上的镜像;
docker pull [镜像名称]:从仓库中获取镜像;
docker images:列出本地所有的镜像(非隐藏,可以加入-a参数显示所有);
docker build:通过 Dockerfile build 出镜像;
docker commit:将容器中的所有改动生成新的镜像;
docker history:查看镜像的历史;
docker save:将镜像保存成 tar 包;
docker import:通过 tar 包导入新的镜像;
docker load:通过 tar 包或者标志输入导入镜像;
docker rmi:删除本地镜像;
docker tag:给镜像打 tag
容器
Docker 利用容器来运行应用。
容器是从镜像创建的运行实例。它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。
可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
镜像( Image )和容器( Container )的关系,就像是面向对象程序设计中的 类 和 实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。
镜像使用的是分层存储,容器也是如此。每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个为容器运行时读写而准备的存储层为”容器存储层”。容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。

容器常见操作:
docker run [OPTIONS] IMAGE [COMMAND] [ARG…]:利用镜像创建并启动一个容器
常用参数:
--interactive 等同于 -i ,接受 stdin 的输入,(即使没有连接,也要保持STDIN打开) --tty 等同于 -t,分配一个 tty,也就是分配虚拟终端,一般和 i 一起使用; --name 给容器设置一个名字,如果没有指定将会随机产生一个名称 -d, --detach 在后台运行容器并打印出容器IDdemo
docker run --name nginx-test -p 8080:80 -d nginx
docker exec -it containerID /bin/bash:以bash方式进入容器
docker container start/stop/restart:启动/停止/重启停止状态下的容器
docker rm [容器名称]/[容器ID] :删除已关闭的容器
docker inspect [容器id]:查看容器全部信息
docker container ls -a / docker ps -a:查看所有已经创建的包括终止状态的容器
仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。一个 Docker Registry 中可以包含多个仓库( Repository );每个仓库可以包含多个标签( Tag )
仓库分为公开仓库(Public)和私有仓库(Private)两种形式。
最大的公开仓库是 Docker Hub,存放了数量庞大的镜像供用户下载。
docker官方镜像仓库:https://hub.docker.com
仓库常见操作:
- docker login: 登录镜像仓库;
- docker logout: 登出镜像仓库;
- docker pull: 从镜像仓库拉取镜像 ;
- docker push: 向镜像仓库 push 镜像,需要先 login。
搭建私有镜像仓库
创建阿里云私有镜像仓库:https://cr.console.aliyun.com/cn-hangzhou/instances
Docker Hub的使用

管理应用程序数据
存储驱动
存储驱动管理Docker容器的本地存储空间。一般设置为overlay2

Docker主机数据挂载到容器的方式
为避免数据随着容器的关闭而丢失,提供容器数据持久化方式。
Volume

多个容器可以使用同一个数据卷实现数据的共享。
Bind Mounts

Dockerfile
简介
每个仓库中都包含了一个名为Dockerfile的文件。
Dockerfile是一个纯文本文件,文本内容包含了一条条构建镜像所需的指令和说明。其中描述了如何将应用构建到Docker镜像中。
构建镜像
在一个空目录下,新建一个名为
Dockerfile文件,添加镜像指令,例如# 三步曲1:规定基础镜像 # 基础镜像可以理解为操作系统,我们在安装其他程序前,需要先安装操作系统 FROM alpine # 三步曲2:运行命令来安装必要的依赖、程序 # apk 是 alpine 内建的包管理命令,我们使用这个包管理程序安装 redis RUN apk add --update redis # 三步曲3:规定容器启动参数 CMD ["redis-server"]注意Dockerfile 的指令(
RUN)每执行一次都会在 docker 上新建一层,所以过多无意义的层,会造成镜像膨胀过大.可以
&&符号连接命令,这样执行后,只会创建 1 层镜像。构建镜像
docker build -t nginx:v3 .构建一个
nginx:v3(镜像名称:镜像标签)最后一个
.是上下文路径。在构建镜像时,有时候想要使用到本机的文件(比如复制),docker build 命令得知这个路径后,会将路径下的所有内容打包。
镜像查看
docker images镜像上传
上传到上一章节创建的镜像仓库。我一般是上传到自己的阿里云私人镜像仓库:
$ docker login --username=xxx registry.cn-hangzhou.aliyuncs.com $ docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/xxx_repo/test:[镜像版本号] $ docker push registry.cn-hangzhou.aliyuncs.com/xxx_repo/test:[镜像版本号] $ docker pull registry.cn-hangzhou.aliyuncs.com/xxx_repo/test:[镜像版本号]
指令详解
| Dockerfile 指令 | 说明 |
|---|---|
| FROM | 指定基础镜像,用于后续的指令构建。 |
| MAINTAINER | 指定Dockerfile的作者/维护者。(已弃用,推荐使用LABEL指令) |
| LABEL | 添加镜像的元数据,使用键值对的形式。 |
| RUN | 在构建过程中在镜像中执行命令。 |
| CMD | 指定容器创建时的默认命令。(可以被覆盖) |
| ENTRYPOINT | 设置容器创建时的主要命令。(不可被覆盖) |
| EXPOSE | 声明容器运行时监听的特定网络端口。 |
| ENV | 在容器内部设置环境变量。 |
| ADD | 将文件、目录或远程URL复制到镜像中。 |
| COPY | 将文件或目录复制到镜像中。 |
| VOLUME | 为容器创建挂载点或声明卷。 |
| WORKDIR | 设置后续指令的工作目录。 |
| USER | 指定后续指令的用户上下文。 |
| ARG | 定义在构建过程中传递给构建器的变量,可使用 “docker build” 命令设置。 |
| ONBUILD | 当该镜像被用作另一个构建过程的基础时,添加触发器。 |
| STOPSIGNAL | 设置发送给容器以退出的系统调用信号。 |
| HEALTHCHECK | 定义周期性检查容器健康状态的命令。 |
| SHELL | 覆盖Docker中默认的shell,用于RUN、CMD和ENTRYPOINT指令。 |
COPY
复制指令,从上下文目录中复制文件或者目录到容器里指定路径。
格式:
COPY [--chown=<user>:<group>] <源路径1>... <目标路径>
COPY [--chown=<user>:<group>] ["<源路径1>",... "<目标路径>"]**[–chown=
**<源路径>**:源文件或者源目录,这里可以是通配符表达式,其通配符规则要满足 Go 的 filepath.Match 规则。例如:
COPY hom* /mydir/
COPY hom?.txt /mydir/**<目标路径>**:容器内的指定路径,该路径不用事先建好,路径不存在的话,会自动创建。
ADD
ADD 指令和 COPY 的使用格类似(同样需求下,官方推荐使用 COPY)。功能也类似,不同之处如下:
- ADD 的优点:在执行 <源文件> 为 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,会自动复制并解压到 <目标路径>。
- ADD 的缺点:在不解压的前提下,无法复制 tar 压缩文件。会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。具体是否使用,可以根据是否需要自动解压来决定。
CMD
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
- CMD 在docker run 时运行。
- RUN 是在 docker build。
作用:为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
注意:如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。
格式:
CMD <shell 命令>
CMD ["<可执行文件或命令>","<param1>","<param2>",...]
CMD ["<param1>","<param2>",...] # 该写法是为 ENTRYPOINT 指令指定的程序提供默认参数推荐使用第二种格式,执行过程比较明确。第一种格式实际上在运行的过程中也会自动转换成第二种格式运行,并且默认可执行文件是 sh。
ENTRYPOINT
类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
但是, 如果运行 docker run 时使用了 –entrypoint 选项,将覆盖 ENTRYPOINT 指令指定的程序。
优点:在执行 docker run 的时候可以指定 ENTRYPOINT 运行所需的参数。
注意:如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
格式:
ENTRYPOINT ["<executeable>","<param1>","<param2>",...]可以搭配 CMD 命令使用:一般是变参才会使用 CMD ,这里的 CMD 等于是在给 ENTRYPOINT 传参,以下示例会提到。
示例:
假设已通过 Dockerfile 构建了 nginx:test 镜像:
FROM nginx
ENTRYPOINT ["nginx", "-c"] # 定参
CMD ["/etc/nginx/nginx.conf"] # 变参 1、不传参运行
$ docker run nginx:test容器内会默认运行以下命令,启动主进程。
nginx -c /etc/nginx/nginx.conf2、传参运行
$ docker run nginx:test -c /etc/nginx/new.conf容器内会默认运行以下命令,启动主进程(/etc/nginx/new.conf:假设容器内已有此文件)
nginx -c /etc/nginx/new.confENV
设置环境变量,定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。
格式:
ENV <key> <value>
ENV <key1>=<value1> <key2>=<value2>...以下示例设置 NODE_VERSION = 7.2.0 , 在后续的指令中可以通过 $NODE_VERSION 引用:
ENV NODE_VERSION 7.2.0
RUN curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-x64.tar.xz" \
&& curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc"ARG
构建参数,与 ENV 作用一致。不过作用域不一样。ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只有 docker build 的过程中有效,构建好的镜像内不存在此环境变量。
构建命令 docker build 中可以用 –build-arg <参数名>=<值> 来覆盖。
格式:
ARG <参数名>[=<默认值>]VOLUME
定义匿名数据卷。在启动容器时忘记挂载数据卷,会自动挂载到匿名卷。
作用:
- 避免重要的数据,因容器重启而丢失,这是非常致命的。
- 避免容器不断变大。
格式:
VOLUME ["<路径1>", "<路径2>"...]
VOLUME <路径>在启动容器 docker run 的时候,我们可以通过 -v 参数修改挂载点。
EXPOSE
仅仅只是声明端口。
作用:
- 帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射。
- 在运行时使用随机端口映射时,也就是 docker run -P 时,会自动随机映射 EXPOSE 的端口。
格式:
EXPOSE <端口1> [<端口2>...]WORKDIR
指定工作目录。用 WORKDIR 指定的工作目录,会在构建镜像的每一层中都存在。以后各层的当前目录就被改为指定的目录,如该目录不存在,WORKDIR 会帮你建立目录。
docker build 构建镜像过程中的,每一个 RUN 命令都是新建的一层。只有通过 WORKDIR 创建的目录才会一直存在。
格式:
WORKDIR <工作目录路径>USER
用于指定执行后续命令的用户和用户组,这边只是切换后续命令执行的用户(用户和用户组必须提前已经存在)。
格式:
USER <用户名>[:<用户组>]HEALTHCHECK
用于指定某个程序或者指令来监控 docker 容器服务的运行状态。
格式:
HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令
HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK [选项] CMD <命令> : 这边 CMD 后面跟随的命令使用,可以参考 CMD 的用法。ONBUILD
用于延迟构建命令的执行。简单的说,就是 Dockerfile 里用 ONBUILD 指定的命令,在本次构建镜像的过程中不会执行(假设镜像为 test-build)。当有新的 Dockerfile 使用了之前构建的镜像 FROM test-build ,这时执行新镜像的 Dockerfile 构建时候,会执行 test-build 的 Dockerfile 里的 ONBUILD 指定的命令。
格式:
ONBUILD <其它指令>LABEL
LABEL 指令用来给镜像添加一些元数据(metadata),以键值对的形式,语法格式如下:
LABEL <key>=<value> <key>=<value> <key>=<value> ...比如我们可以添加镜像的作者:
LABEL org.opencontainers.image.authors="runoob"需要注意的问题
Mysql需要实现容器化吗?
聊一下 Docker 不适合跑 MySQL 的 N 个原因
数据安全问题
不要将数据储存在容器中,这也是 Docker 官方容器使用技巧中的一条。容器随时可以停止、或者删除。当容器被rm掉,容器里的数据将会丢失。为了避免数据丢失,用户可以使用数据卷挂载来存储数据。
但是容器的 Volumes 设计是围绕 Union FS 镜像层提供持久存储,数据安全缺乏保证。如果容器突然崩溃,数据库未正常关闭,可能会损坏数据。另外,容器里共享数据卷组,对物理机硬件损伤也比较大。
性能问题
大家都知道,MySQL 属于关系型数据库,对IO要求较高。当一台物理机跑多个时,IO就会累加,导致IO瓶颈,大大降低 MySQL 的读写性能。
在一次Docker应用的十大难点专场上,某国有银行的一位架构师也曾提出过:“数据库的性能瓶颈一般出现在IO上面,如果按 Docker 的思路,那么多个docker最终IO请求又会出现在存储上面。现在互联网的数据库多是share nothing的架构,可能这也是不考虑迁移到 Docker 的一个因素吧”。
其实也有相对应的一些策略来解决这个问题,比如:
数据库程序与数据分离
如果使用Docker 跑 MySQL,数据库程序与数据需要进行分离,将数据存放到共享存储,程序放到容器里。如果容器有异常或 MySQL 服务异常,自动启动一个全新的容器。另外,建议不要把数据存放到宿主机里,宿主机和容器共享卷组,对宿主机损坏的影响比较大。
跑轻量级或分布式数据库
Docker 里部署轻量级或分布式数据库,Docker 本身就推荐服务挂掉,自动启动新容器,而不是继续重启容器服务。
合理布局应用
对于IO要求比较高的应用或者服务,将数据库部署在物理机或者KVM中比较合适。目前腾讯云的TDSQL和阿里的Oceanbase都是直接部署在物理机器,而非Docker 。
状态问题
在 Docker 中水平伸缩只能用于无状态计算服务,而不是数据库。
Docker 快速扩展的一个重要特征就是无状态,具有数据状态的都不适合直接放在 Docker 里面,如果 Docker 中安装数据库,存储服务需要单独提供。
目前,腾讯云的TDSQL(金融分布式数据库)和阿里云的Oceanbase(分布式数据库系统)都直接运行中在物理机器上,并非使用便于管理的 Docker 上。
资源隔离方面
资源隔离方面,Docker 确实不如虚拟机KVM,Docker是利用Cgroup实现资源限制的,只能限制资源消耗的最大值,而不能隔绝其他程序占用自己的资源。如果其他应用过渡占用物理机资源,将会影响容器里 MySQL 的读写效率。
需要的隔离级别越多,获得的资源开销就越多。相比专用环境而言,容易水平伸缩是Docker的一大优势。然而在 Docker 中水平伸缩只能用于无状态计算服务,数据库并不适用。
难道 MySQL 不能跑在容器里吗
MySQL 也不是全然不能容器化。
1)对数据丢失不敏感的业务(例如用户搜索商品)就可以数据化,利用数据库分片来来增加实例数,从而增加吞吐量。
2)docker适合跑轻量级或分布式数据库,当docker服务挂掉,会自动启动新容器,而不是继续重启容器服务。
3)数据库利用中间件和容器化系统能够自动伸缩、容灾、切换、自带多个节点,也是可以进行容器化的。
典型案例:同程旅游、京东、阿里的数据库容器化都是不错的案例,大家可以自行去查看。