目录
- 为什么使用消息队列
- 消息队列有什么优点和缺点
- 不同MQ都有什么优点和缺点
- 如何保证消息队列的高可用
- 如何保证消息消费时的幂等性
- 如何保证消息的可靠性传输
- 如何保证消息的顺序性
- 大量消息在mq里积压了几个小时了怎么解决
为什么使用消息队列
其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么?
三大作用:解耦、异步、削峰
(1)解耦
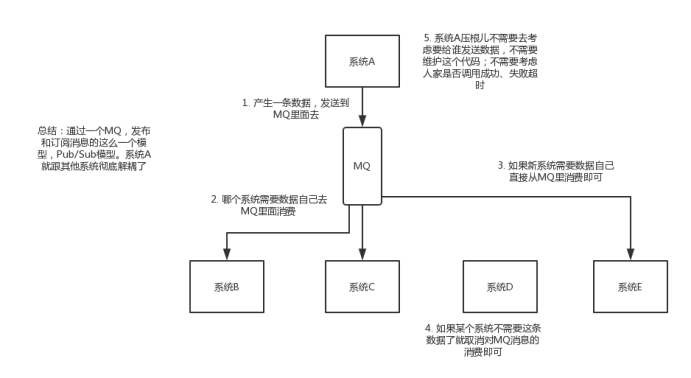
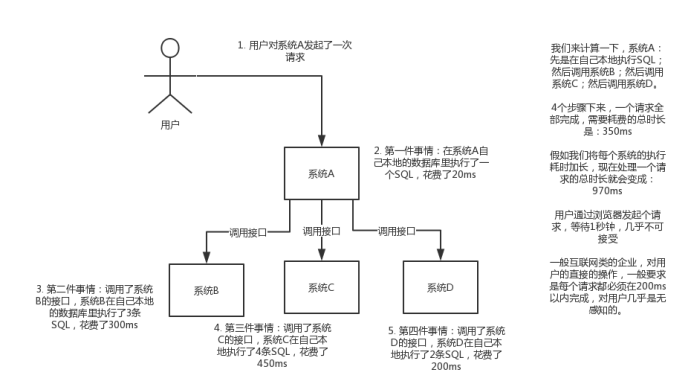
(2)异步
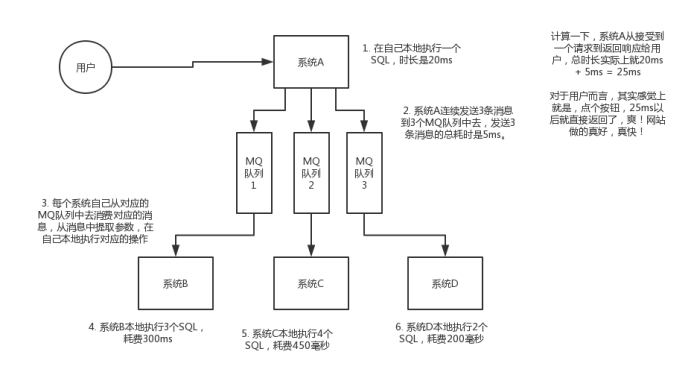
(3)削峰
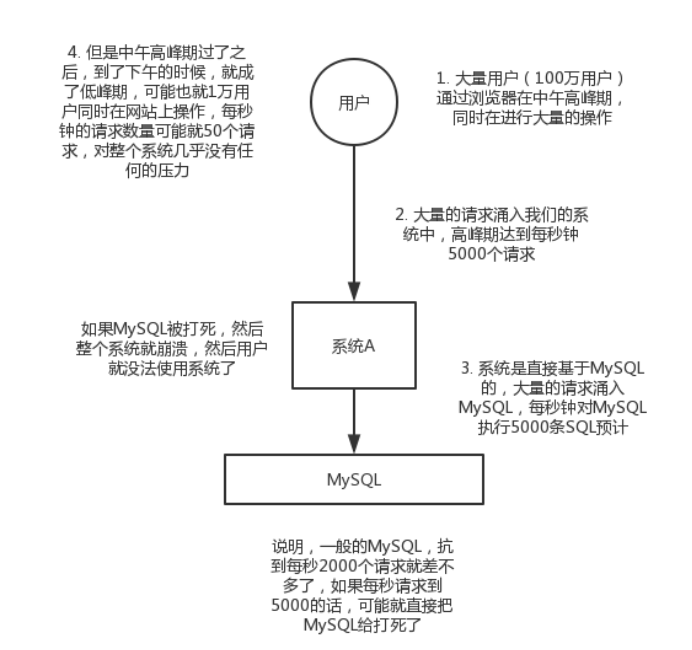
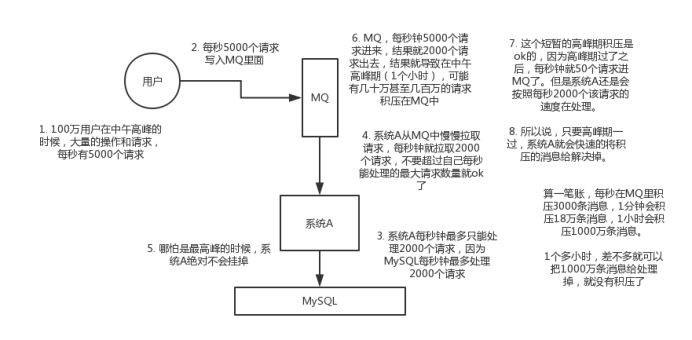
消息队列有什么优点和缺点
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。缺点呢?显而易见的
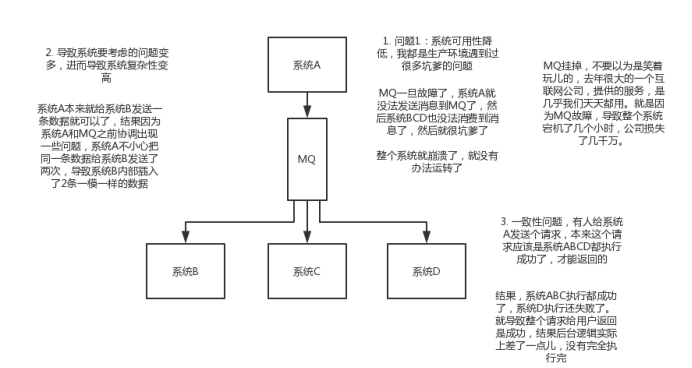
(1)系统可用性降低:系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,人ABCD四个系统好好的,没啥问题,你偏加个MQ进来,万一MQ挂了咋整?MQ挂了,整套系统崩溃了,你不就完了么。
(2)系统复杂性提高:硬生生加个MQ进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已
(3)一致性问题:A系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是BCD三个系统那里,BD两个系统写库成功了,结果C系统写库失败了,咋整?你这数据就不一致了。
(4)所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,最好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了10倍。但是关键时刻,用,还是得用的。
不同MQ都有什么优点和缺点
如何保证消息队列的高可用
如何保证消息消费时的幂等性
如何保证消息不被重复消费啊
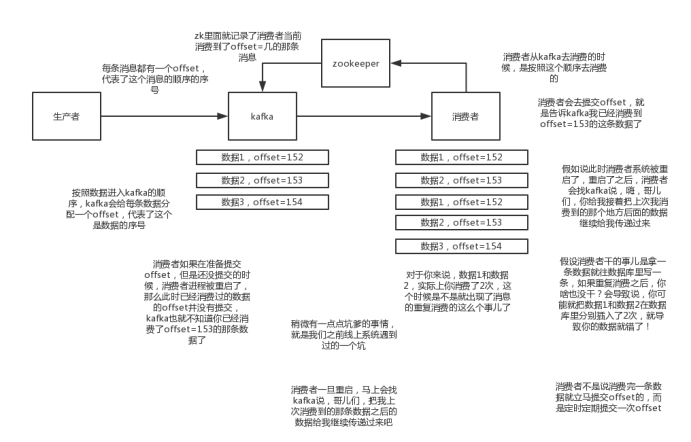
得结合业务来思考:
(1)比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下好吧
(2)比如你是写redis,那没问题了,反正每次都是set,天然幂等性
(3)内存Set
(4)比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西,然后你这里消费到了之后,先根据这个id去比如redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
如何保证消息的可靠性传输
如何处理消息丢失的问题
如何保证消息的顺序性
顺序会错乱的俩场景
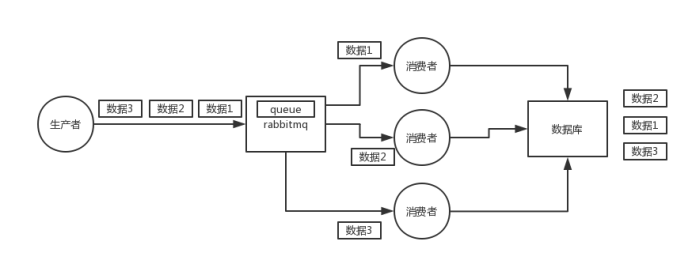
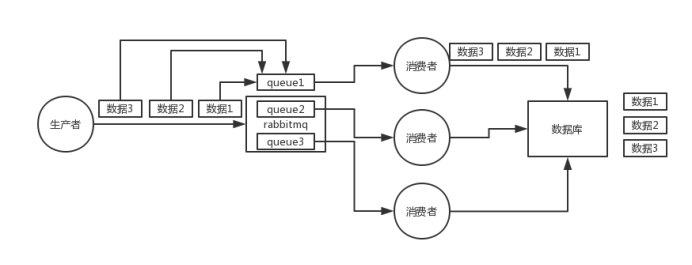
(1)rabbitmq:一个queue,多个consumer,这不明显乱了
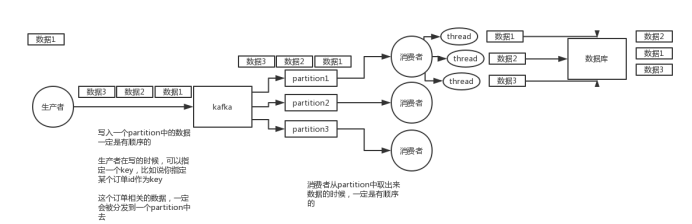
(2)kafka:一个topic,一个partition,一个consumer,内部多线程,这不也明显乱了
那如何保证消息的顺序性呢
(1)rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理
(2)kafka:一个topic,一个partition,一个consumer,内部单线程消费,写N个内存queue,然后N个线程分别消费一个内存queue即可
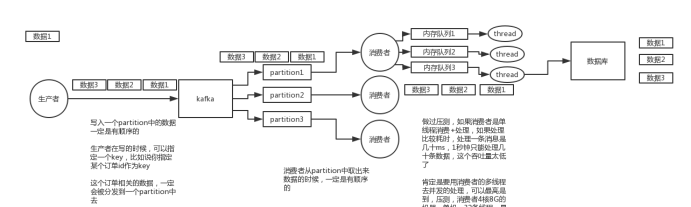
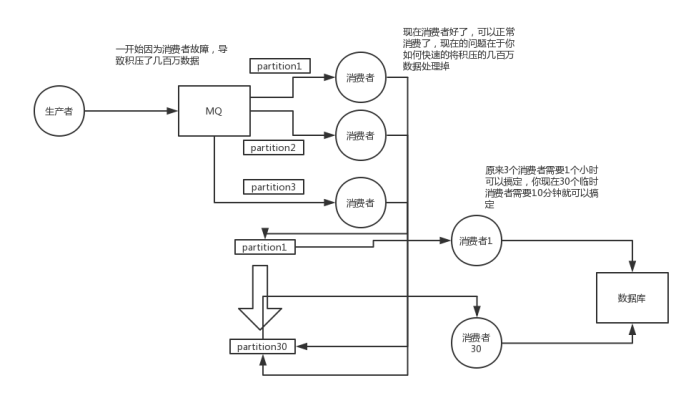
大量消息在mq里积压了几个小时了怎么解决
1)先修复consumer的问题,确保其恢复消费速度,然后将现有cnosumer都停掉
2)新建一个topic,partition是原来的10倍,临时建立好原先10倍或者20倍的queue数量
3)然后写一个临时的分发数据的consumer程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的10倍数量的queue
4)接着临时征用10倍的机器来部署consumer,每一批consumer消费一个临时queue的数据
5)这种做法相当于是临时将queue资源和consumer资源扩大10倍,以正常的10倍速度来消费数据
6)等快速消费完积压数据之后,得恢复原先部署架构,重新用原先的consumer机器来消费消息