目录:
简介
核心能力
架构
通信流程示例
参考文献:
简介
Kubernetes(k8s)是自动化容器操作的开源平台,这些操作包括部署,调度和节点集群间扩展。如果你曾经用过Docker容器技术部署容器,那么可以将Docker看成Kubernetes内部使用的低级别组件。Kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术。
使用Kubernetes可以:
- 自动化容器的部署和复制
- 随时扩展或收缩容器规模
- 将容器组织成组,并且提供容器间的负载均衡
- 很容易地升级应用程序容器的新版本
- 提供容器弹性,如果容器失效就替换它,等等
总体架构如下:
核心能力
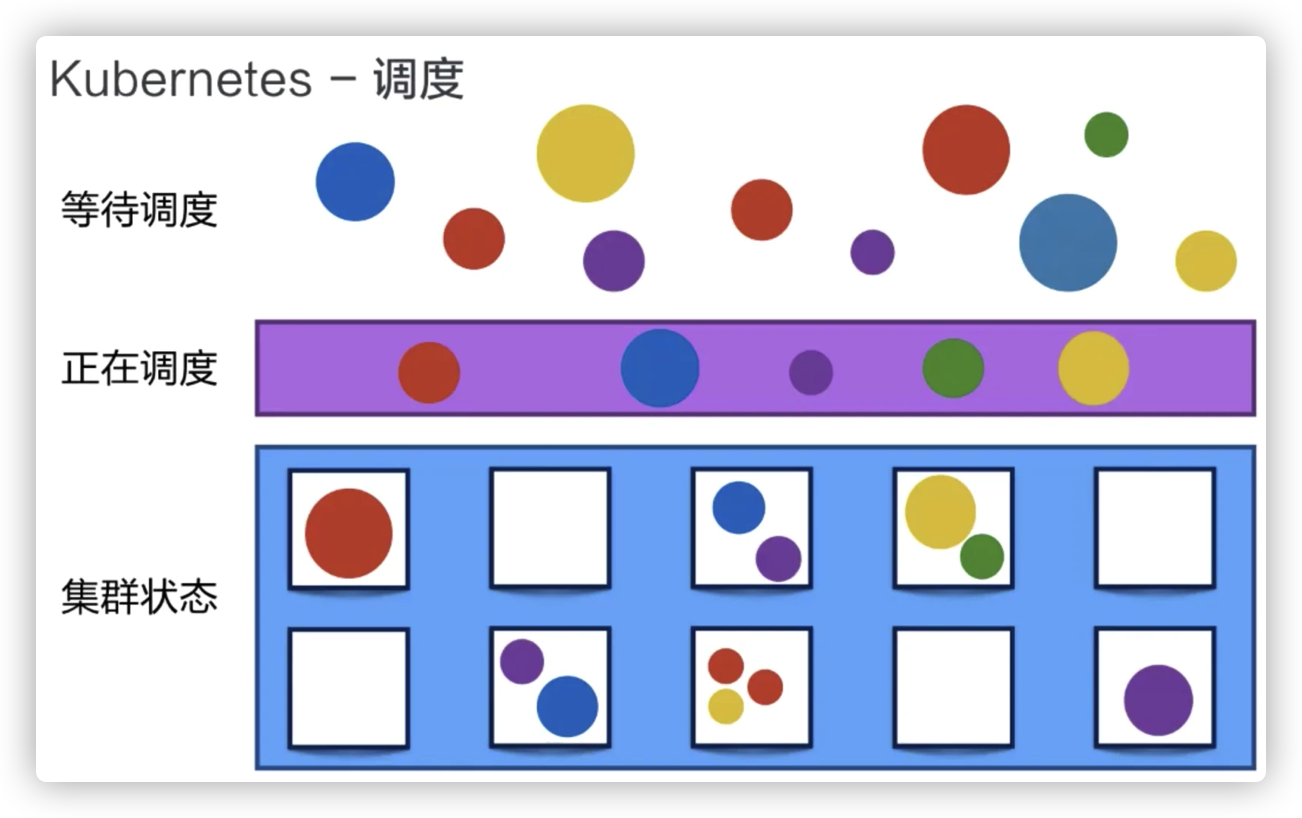
调度
Kubernetes 可以把用户提交的容器放到 Kubernetes 管理的集群的某一台节点上去。Kubernetes 的调度器是执行这项能力的组件,它会观察正在被调度的这个容器的大小、规格。
比如说它所需要的 CPU 以及它所需要的 memory,然后在集群中找一台相对比较空闲的机器来进行一次 placement,也就是一次放置的操作。在这个例子中,它可能会把红颜色的这个容器放置到第二个空闲的机器上,来完成一次调度的工作。
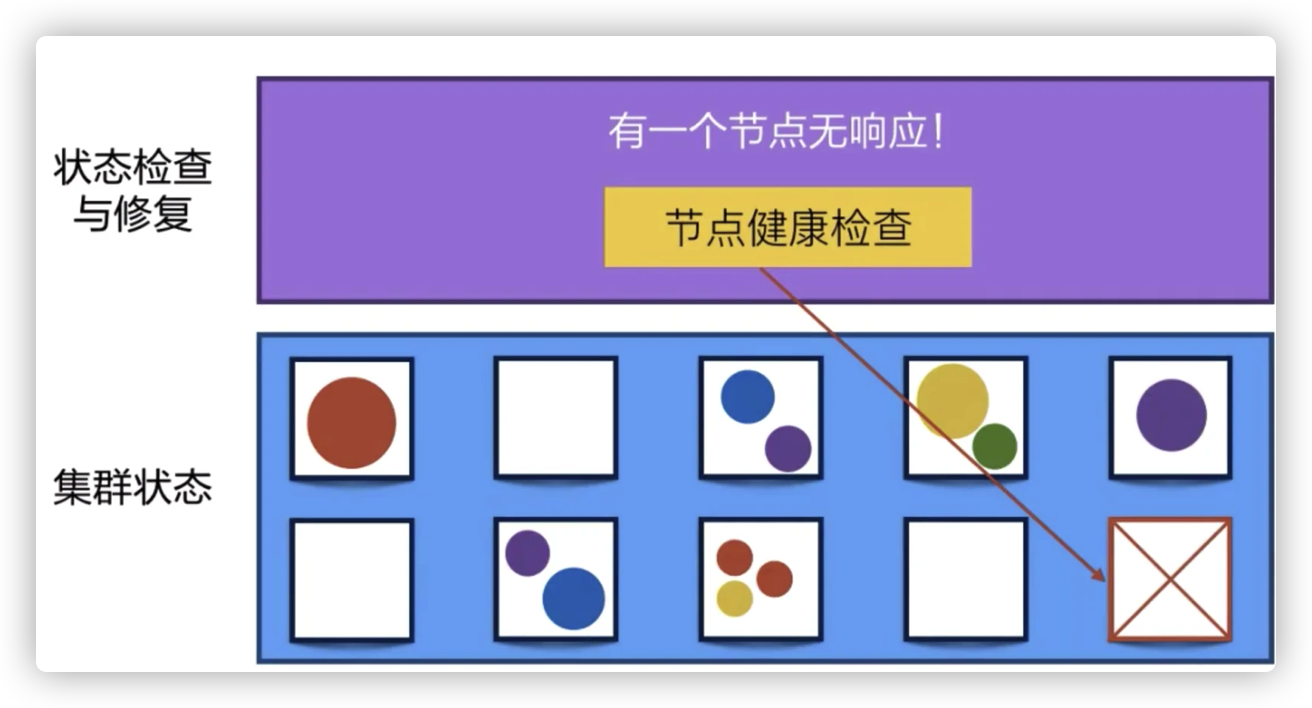
自动修复
Kubernetes 有一个节点健康检查的功能,它会监测这个集群中所有的宿主机,当宿主机本身出现故障,或者软件出现故障的时候,这个节点健康检查会自动对它进行发现。
下面 Kubernetes 会把运行在这些失败节点上的容器进行自动迁移,迁移到一个正在健康运行的宿主机上,来完成集群内容器的一个自动恢复。

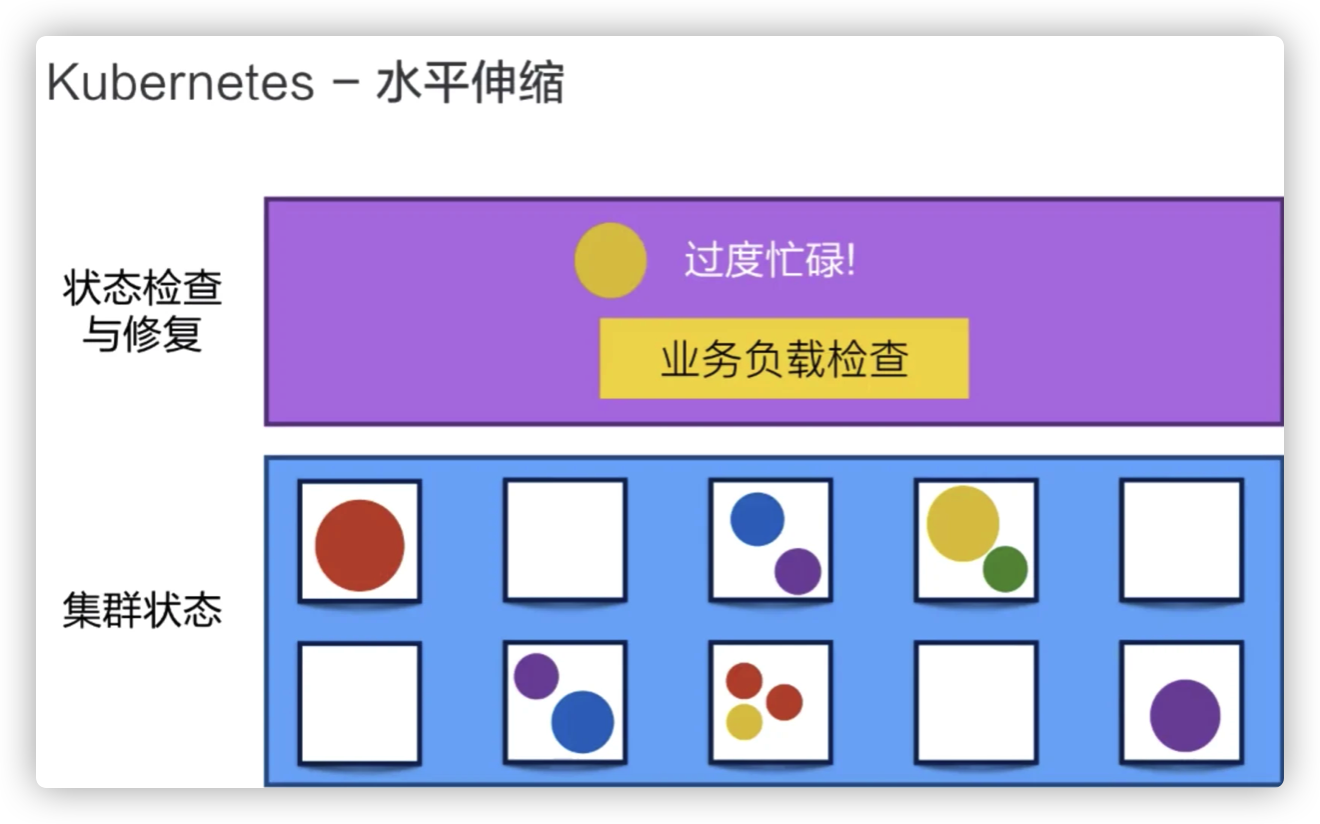
水平伸缩
Kubernetes 有业务负载检查的能力,它会监测业务上所承担的负载,如果这个业务本身的 CPU 利用率过高,或者响应时间过长,它可以对这个业务进行一次扩容。
比如说在下面的例子中,黄颜色的过度忙碌,Kubernetes 就可以把黄颜色负载从一份变为三份。接下来,它就可以通过负载均衡把原来打到第一个黄颜色上的负载平均分到三个黄颜色的负载上去,以此来提高响应的时间。

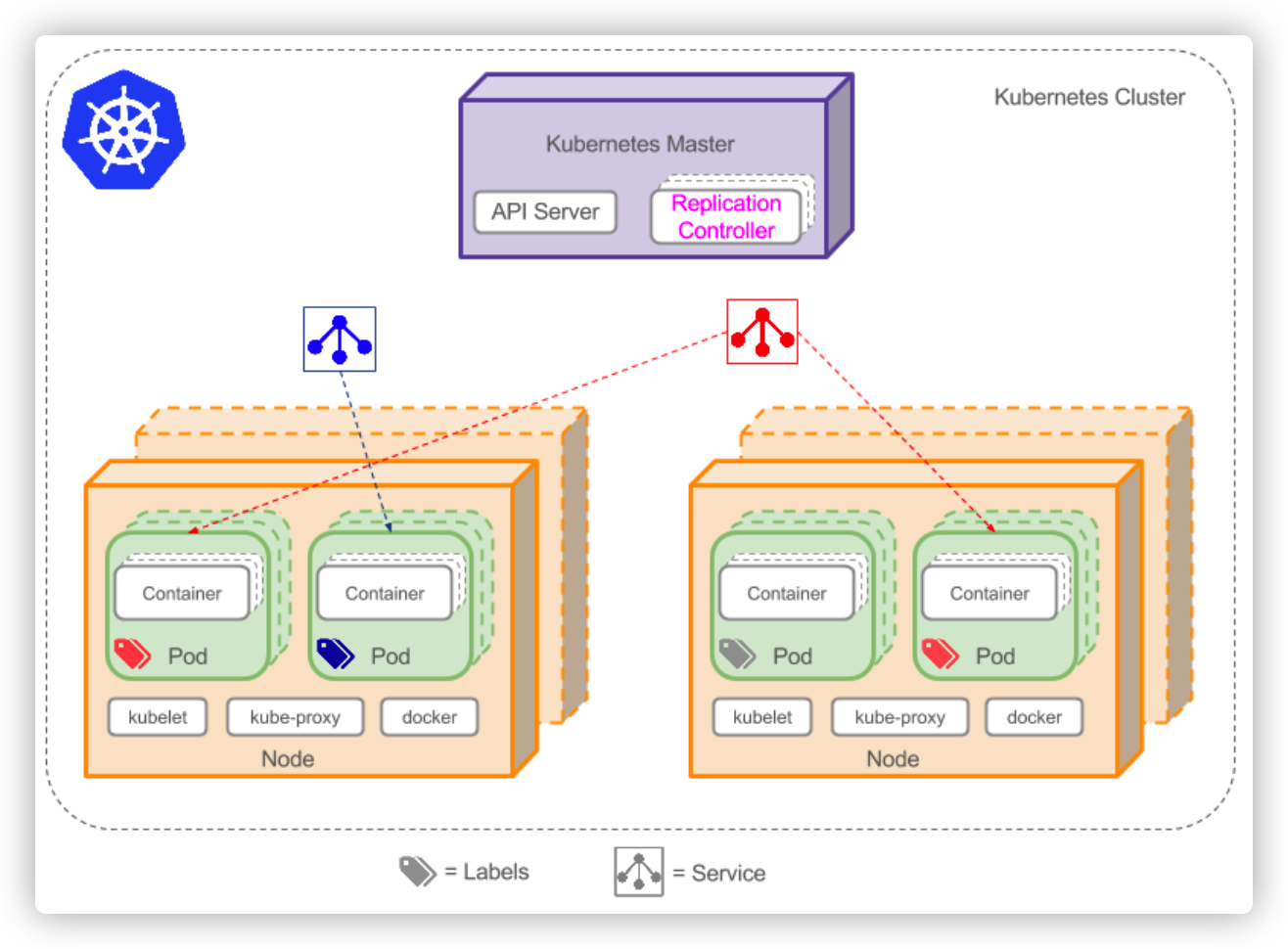
架构
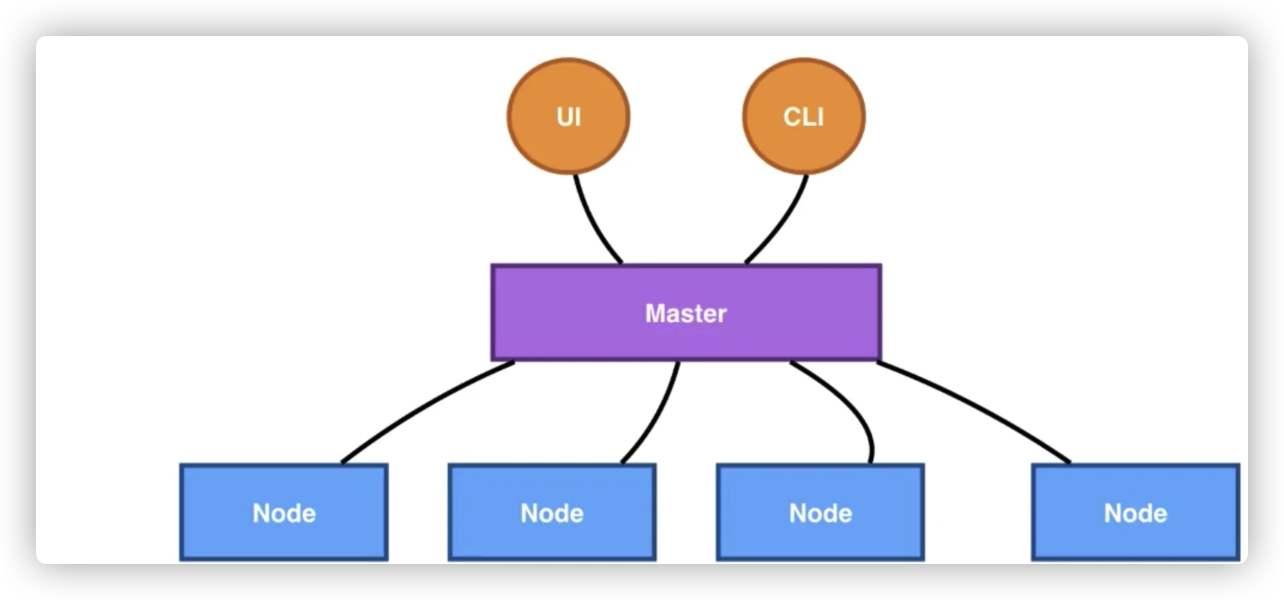
Kubernetes 架构是一个比较典型的二层架构和 server-client 架构。Master 作为中央的管控节点,会去与 Node 进行一个连接。
所有 UI 的、clients、这些 user 侧的组件,只会和 Master 进行连接,把希望的状态或者想执行的命令下发给 Master,Master 会把这些命令或者状态下发给相应的节点,进行最终的执行。
Master
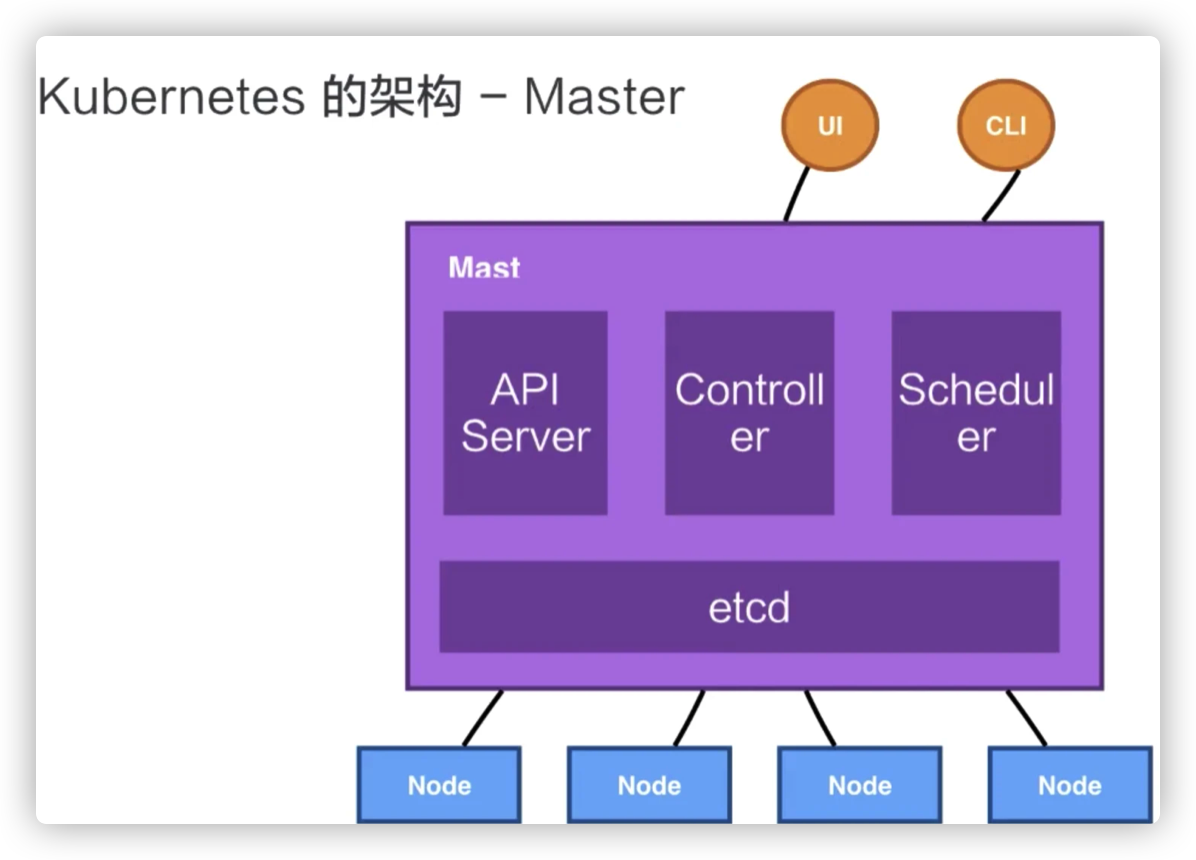
API Server:顾名思义是用来处理 API 操作的,Kubernetes 中所有的组件都会和 API Server 进行连接,组件与组件之间一般不进行独立的连接,都依赖于 API Server 进行消息的传送;
Kubernetes 的 kubectl 也就是 command tool,Kubernetes UI,或者有时候用 curl,直接与 Kubernetes 进行沟通,都是使用 HTTP + JSON 这种形式。
比如说,对于这个 Pod 类型的资源,它的 HTTP 访问的路径,就是 API,然后是 apiVesion: V1, 之后是相应的 Namespaces,以及 Pods 资源,最终是 Podname,也就是 Pod 的名字。

Controller:是控制器,它用来完成对集群状态的一些管理。比如刚刚我们提到的两个例子之中,第一个自动对容器进行修复、第二个自动进行水平扩张,都是由 Kubernetes 中的 Controller 来进行完成的;
Scheduler:是调度器,“调度器”顾名思义就是完成调度的操作,就是我们刚才介绍的第一个例子中,把一个用户提交的 Container,依据它对 CPU、对 memory 请求大小,找一台合适的节点,进行放置;
etcd:是一个分布式的一个存储系统,API Server 中所需要的这些原信息都被放置在 etcd 中,etcd 本身是一个高可用系统,通过 etcd 保证整个 Kubernetes 的 Master 组件的高可用性。
Node
Kubernetes 的 Node 是真正运行业务负载的,每个业务负载会以 Pod 的形式运行。等一下我会介绍一下 Pod 的概念。一个 Pod 中运行的一个或者多个容器,真正去运行这些 Pod 的组件的是叫做 kubelet,也就是 Node 上最为关键的组件,它通过 API Server 接收到所需要 Pod 运行的状态,然后提交到我们下面画的这个 Container Runtime 组件中。
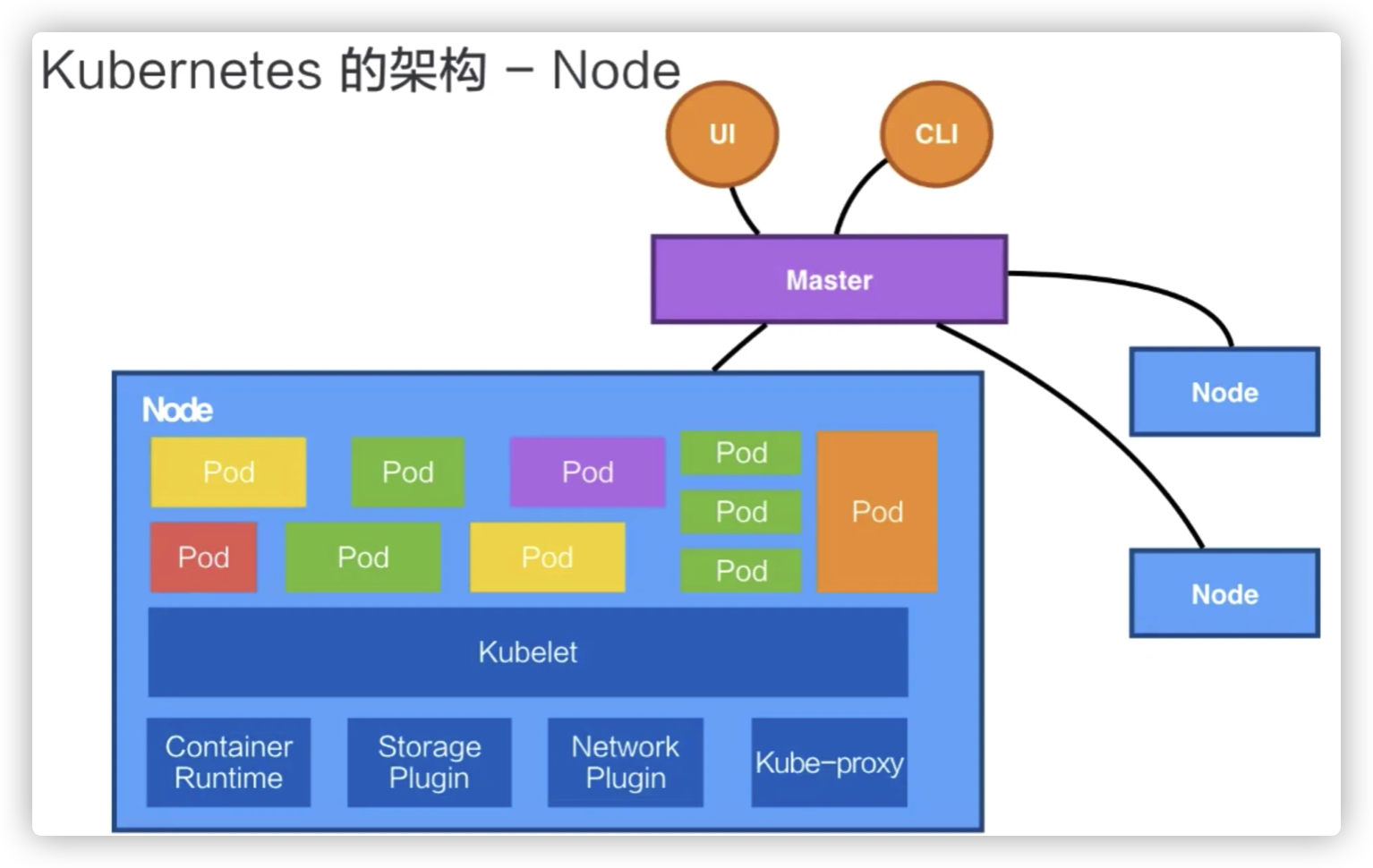
在 OS 上去创建容器所需要运行的环境,最终把容器或者 Pod 运行起来,也需要对存储跟网络进行管理。Kubernetes 并不会直接进行网络存储的操作,他们会靠 Storage Plugin 或者是网络的 Plugin 来进行操作。用户自己或者云厂商都会去写相应的 Storage Plugin 或者 Network Plugin,去完成存储操作或网络操作。
在 Kubernetes 自己的环境中,也会有 Kubernetes 的 Network,它是为了提供 Service network 来进行搭网组网的。(等一下我们也会去介绍“service”这个概念。)真正完成 service 组网的组件的是 Kube-proxy,它是利用了 iptable 的能力来进行组建 Kubernetes 的 Network,就是 cluster network.
Kubernetes 的 Node 并不会直接和 user 进行 interaction,它的 interaction 只会通过 Master。而 User 是通过 Master 向节点下发这些信息的。Kubernetes 每个 Node 上,都会运行我们刚才提到的这几个组件。
Pod
Pod 是 Kubernetes 的一个最小调度以及资源单元。用户可以通过 Kubernetes 的 Pod API 生产一个 Pod,让 Kubernetes 对这个 Pod 进行调度,也就是把它放在某一个 Kubernetes 管理的节点上运行起来。一个 Pod 简单来说是对一组容器的抽象,它里面会包含一个或多个容器。
比如像下面的这幅图里面,它包含了两个容器,每个容器可以指定它所需要资源大小。比如说,一个核一个 G,或者说 0.5 个核,0.5 个 G。
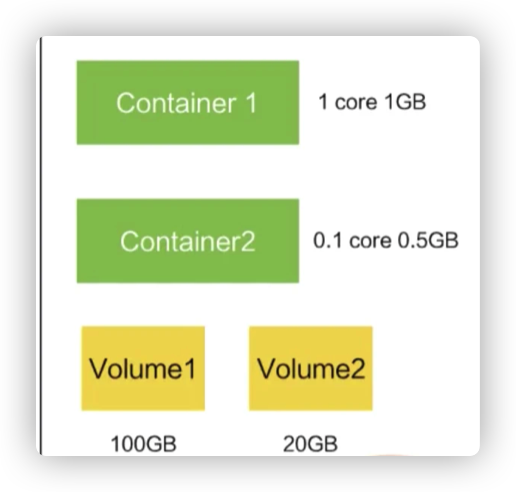
当然在这个 Pod 中也可以包含一些其他所需要的资源:比如说我们所看到的 Volume 卷这个存储资源;比如说我们需要 100 个 GB 的存储或者 20GB 的另外一个存储。
在 Pod 里面,我们也可以去定义容器所需要运行的方式。比如说运行容器的 Command,以及运行容器的环境变量等等。Pod 这个抽象也给这些容器提供了一个共享的运行环境(ex:进程空间),它们会共享同一个网络环境,这些容器可以用 localhost 来进行直接的连接。而 Pod 与 Pod 之间,是互相有 isolation 隔离的。
Label
一些Pod有Label。一个Label是attach到Pod的一对键/值对,用来传递用户定义的属性。比如,你可能创建了一个”tier”和“app”标签,通过Label(tier=frontend, app=myapp)来标记前端Pod容器,使用Label(tier=backend, app=myapp)标记后台Pod。然后可以使用Selectors选择带有特定Label的Pod,并且将Service或者Controller应用到上面。
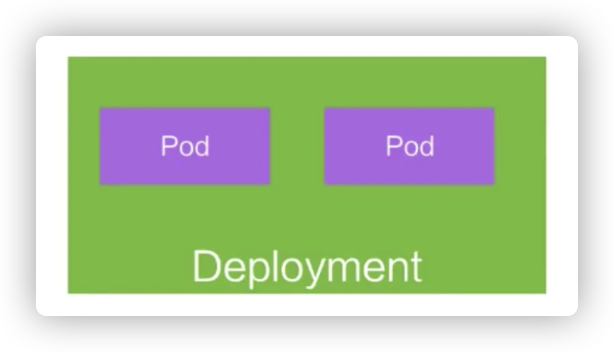
Deployment
Deployment 是在 Pod 这个抽象上更为上层的一个抽象,它可以定义一组 Pod 的副本数目、以及这个 Pod 的版本。一般大家用 Deployment 这个抽象来做应用的真正的管理,而 Pod 是组成 Deployment 最小的单元。
Kubernetes 是通过 Controller,也就是我们刚才提到的控制器去维护 Deployment 中 Pod 的数目,它也会去帮助 Deployment 自动恢复失败的 Pod。
比如说我可以定义一个 Deployment,这个 Deployment 里面需要两个 Pod,当一个 Pod 失败的时候,控制器就会监测到,它重新把 Deployment 中的 Pod 数目从一个恢复到两个,通过再去新生成一个 Pod。通过控制器,我们也会帮助完成发布的策略。比如说进行滚动升级,进行重新生成的升级,或者进行版本的回滚。
Service
Service 提供了一个或者多个 Pod 实例的稳定访问地址。
比如在上面的例子中,我们看到:一个 Deployment 可能有两个甚至更多个完全相同的 Pod。对于一个外部的用户来讲,访问哪个 Pod 其实都是一样的,所以它希望做一次负载均衡,在做负载均衡的同时,我只想访问某一个固定的 VIP,也就是 Virtual IP 地址,而不希望得知每一个具体的 Pod 的 IP 地址。
我们刚才提到,这个 pod 本身可能 terminal go(终止),如果一个 Pod 失败了,可能会换成另外一个新的。对一个外部用户来讲,提供了多个具体的 Pod 地址,这个用户要不停地去更新 Pod 地址,当这个 Pod 再失败重启之后,我们希望有一个抽象,把所有 Pod 的访问能力抽象成一个第三方的一个 IP 地址,实现这个的 Kubernetes 的抽象就叫 Service。
实现 Service 有多种方式,Kubernetes 支持 Cluster IP,上面我们讲过的**kuber-proxy 的组网,它也支持 nodePort、 LoadBalancer **等其他的一些访问的能力。
假定有2个后台Pod,并且定义后台Service的名称为‘backend-service’,lable选择器为(tier=backend, app=myapp)。backend-service 的Service会完成如下两件重要的事情:
- 会为Service创建一个本地集群的DNS入口,因此前端Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。
- 现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个(如下面的动画所示)。通过每个Node上运行的代理(kube-proxy)完成.

通信流程示例
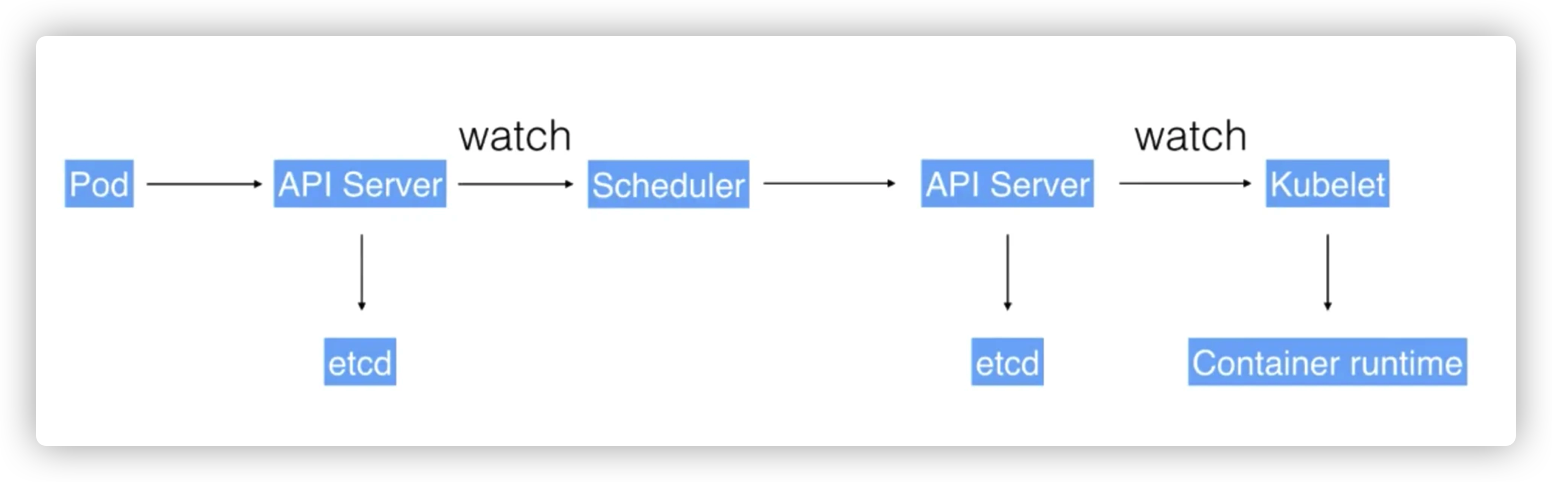
用户可以通过 UI 或者 CLI 提交一个 Pod 给 Kubernetes 进行部署,这个 Pod 请求首先会通过 CLI 或者 UI 提交给 Kubernetes API Server,下一步 API Server 会把这个信息写入到它的存储系统 etcd,之后 Scheduler 会通过 API Server 的 watch 或者叫做 notification 机制得到这个信息:有一个 Pod 需要被调度。
这个时候 Scheduler 会根据它的内存状态进行一次调度决策,在完成这次调度之后,它会向 API Server report 说:“OK!这个 Pod 需要被调度到某一个节点上。”
这个时候 API Server 接收到这次操作之后,会把这次的结果再次写到 etcd 中,然后 API Server 会通知相应的节点进行这次 Pod 真正的执行启动。相应节点的 kubelet 会得到这个通知,kubelet 就会去调 Container runtime 来真正去启动配置这个容器和这个容器的运行环境,去调度 Storage Plugin 来去配置存储,network Plugin 去配置网络。