《开发内功修炼-内存篇》学习笔记
目录
- CPU与内存的连接架构
- 查看Linux内存情况
- 内存的频率
- 内存在顺序IO和随机IO的延时差异
- 内存带宽
- 内核对内存的使用
- 关于内核问题的例子
参考/来源:
- 《开发内功修炼》微信公众号
从2001年DDR内存面世以来发展到2019年的今天,已经走过了DDR、DDR2、DDR3、DDR4四个大的规格时代了(DDR5现在也出来了)
CPU与内存的连接架构
FSB
是历史上CPU、内存数量比较少的年代里的总线方案-FSB。FSB的全称是Front Side Bus,因此也叫前端总线。CPU通过FSB总线连接到北桥芯片,然后再连接到内存。内存控制器是集成在北桥里的,Cpu和内存之间的通信全部都要通过这一条FSB总线来进行。
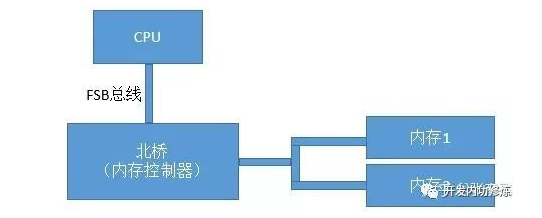
提高计算机系统整体性能的方式就是不断地提高CPU、FSB总线、内存条的数据传输频率。
NUMA时代
CPU制造商们把内存控制器从北桥搬到了CPU内部,这样CPU便可以直接和自己的内存进行通信了。那么,如果CPU想要访问不和自己直连的内存条怎么办呢?所以就诞生了新的总线类型,它就叫QPI总线。

查看NUMA的内存组
每一个物理CPU都有不同的内存组,通过numactl命令可以查看这个分组情况。
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 32756 MB
node 0 free: 19642 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 32768 MB
node 1 free: 18652 MB
node distances:
node 0 1
0: 10 21
1: 21 10通过上述命令可以看到,每一组CPU核分配了32GB(4条)的内存。
node distance是一个二维矩阵,描述node访问所有内存条的延时情况。 node 0里的CPU访问node 0里的内存相对距离是10,因为这时访问的内存都是和该CPU直连的。而node 0如果想访问node 1节点下的内存的话,就需要走QPI总线了,这时该相对距离就变成了21。
测试内存访问速度
拿8M数组,循环步长为64的数组来测试访问速度,同node耗时3.15纳秒,跨node为3.96纳秒。所以属于同一个node里的CPU和内存之间访问速度会比较快。而如果跨node的话,则需要经过QPI总线,总体来说,速度会略慢一些。
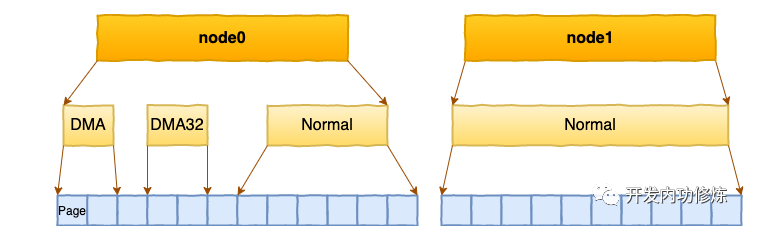
ZONE的划分
每个 node 又会划分成若干的 zone(区域) 。zone 表示内存中的一块范围
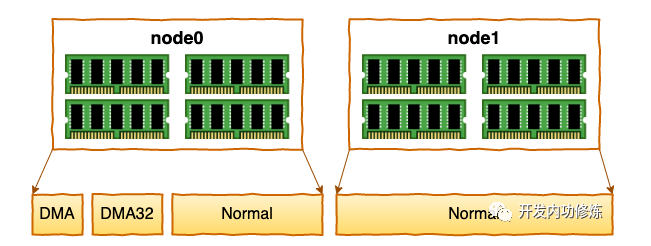
- ZONE_DMA:地址段最低的一块内存区域,ISA(Industry Standard Architecture)设备DMA访问
- ZONE_DMA32:该Zone用于支持32-bits地址总线的DMA设备,只在64-bits系统里才有效
- ZONE_NORMAL:在X86-64架构下,DMA和DMA32之外的内存全部在NORMAL的Zone里管理
在每个zone下,都包含了许许多多个 Page(页面), 在linux下一个Page的大小一般是 4 KB。
# 查看zone的情况
# cat /proc/zoneinfo
Node 0, zone DMA
pages free 3973
managed 3973
Node 0, zone DMA32
pages free 390390
managed 427659
Node 0, zone Normal
pages free 15021616
managed 15990165
Node 1, zone Normal
pages free 16012823
managed 16514393 基于伙伴系统管理空闲页面
每个 zone 下面都有如此之多的页面,Linux使用伙伴系统对这些页面进行高效的管理。在内核中,表示 zone 的数据结构是 struct zone。其下面的一个数组 free_area 管理了绝大部分可用的空闲页面。这个数组就是伙伴系统实现的重要数据结构。
//file: include/linux/mmzone.h
#define MAX_ORDER 11
struct zone {
free_area free_area[MAX_ORDER];
......
}free_area是一个11个元素的数组,在每一个数组分别代表的是空闲可分配连续4K、8K、16K、……、4M内存链表。
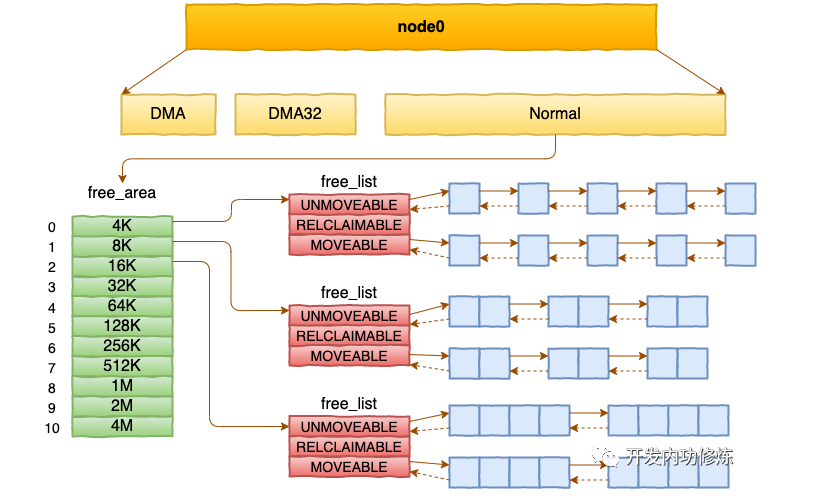
基于伙伴系统的内存分配中,有可能需要将大块内存拆分成两个小伙伴。在释放中,可能会将两个小伙伴合并再次组成更大块的连续内存。
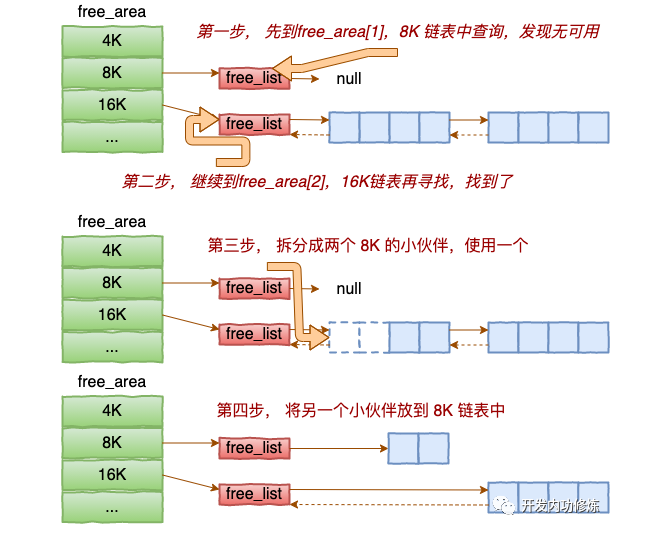
内核提供分配器函数 alloc_pages 到上面的多个链表中寻找可用连续页面。
NUMA陷阱
NUMA陷阱指的是引入QPI总线后,在计算机系统里可能会存在的一个坑。
大致的意思就是如果你的机器打开了numa,那么你的内存即使在充足的情况下,也会使用磁盘上的swap,导致性能低下。
原因就是NUMA为了高效,会仅仅只从你的当前node里分配内存,只要当前node里用光了(即使其它node还有),也仍然会启用硬盘swap。
再看zone_reclaim_mode,它用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项:
- 0 关闭zone_reclaim模式,可以从其他zone或NUMA节点回收内存
- 1 打开zone_reclaim模式,这样内存回收只会发生在本地节点内
- 2 在本地回收内存时,可以将cache中的脏数据写回硬盘,以回收内存
- 4 在本地回收内存时,表示可以用Swap 方式回收内存
# cat /proc/sys/vm/zone_reclaim_mode
1查看Linux内存情况
# dmidecode|grep -P -A5 "Memory\s+Device"|grep Size
Size: 8192 MB
Size: 8192 MB
Size: No Module Installed
Size: 8192 MB
Size: No Module Installed
Size: 8192 MB
Size: 8192 MB
Size: 8192 MB
Size: No Module Installed
Size: 8192 MB
Size: No Module Installed
Size: 8192 MB共插了8条8G的内存, 所以总共是64GB。
内存的频率
实际上有两个频率参数:
工作频率
内存的工作频率从DDR时代的266MHz进化到了今天的3200MHz。这个频率在操作系统里叫Speed,在内存术语里叫等效频率、或干脆直接简称频率。
这个频率越高,每秒钟内存IO的吞吐量越大。
核心频率
但其实内存有一个最最基本的频率叫核心频率,是实际内存电路的工作时的一个振荡频率。它是内存工作的基础,很大程度上会影响内存的IO延迟。我今天想给大家揭开另外一面,这个叫核心频率的东东其实在最近的18年里,基本上就没有什么太大的进步。
查询内存的频率信息
# dmidecode | grep -P -A16 "Memory Device"
Memory Device
Array Handle: 0x0009
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: None
Locator: DIMM02
Bank Locator: BANK02
Type: Other
Type Detail: Unknown
Speed: 1067 MHz
Manufacturer: Micron
Serial Number: 65ED91DC
Asset Tag: Unknown
Part Number: 36KSF1G72PZ-1G4M1
......其中有两个数据比较关键。
- Speed: 1067 MHz:每秒能进行内存数据传输的速度. 这里实际是工作频率
- Data Width: 64 bits:内存工作一次传输的数据宽度
对比历代DDR参数
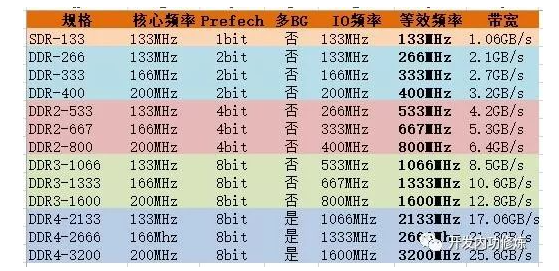
汇总一句话,内存真正的工作频率是核心频率,时钟频率和数据频率都是在核心频率的基础上,通过技术手段放大出来的。内存越新,放大的倍数越多。
内存在顺序和随机IO的延时差异
测试顺序IO
void init_data(double *data, int n){
int i;
for (i = 0; i < n; i++) {
data[i] = i;
}
}
void seque_access(int elems, int stride) {
int i;
double result = 0.0;
volatile double sink;
for (i = 0; i < elems; i += stride) {
result += data[i];
}
sink = result;
}- 一是数组大小,数组越小,高速缓存命中率越高,平均延时就会越低。
- 二是循环步长,步长越小,顺序性越好,同样也会增加缓存命中率,平均延时也低。
我们在测试的过程中采取的办法是,固定其中一个变量,然后动态调节另外一个变量来查看效果。现象:
固定数组大小2K,调节步长
数组足够小的时候,L1 cache全部都能装的下。内存IO发生较少,大部分都是高效的缓存IO,所以我这里看到的内存延时只有1ns左右,这其实只是虚拟地址转换+L1访问的延时。
固定步长为8,数组从32K到64M
当数组越来越大,Cache装不下,导致穿透高速缓存,到内存实际IO的次数就会变多,平均耗时就增加
步长为32,数组从32K到64M
步长变大以后,局部性变差,穿透的内存IO进一步增加。虽然数据量一样大,但是平均耗时就会继续有所上涨。不过虽然穿透增加,但由于访问地址仍然相对比较连续,所以即使发生内存IO也绝大部分都是行地址不变的顺序IO情况。所以耗时在9ns左右
测试随机IO
void init_data(double *data, int n){
int i;
for (i = 0; i < n; i++) {
data[i] = i;
}
}
void random_access(int* random_index_arr, int count) {
int i;
double result = 0.0;
volatile double sink;
for (i = 0; i < count; i++) {
result += data[*(random_index_arr+i)];
}
sink = result;
}数组从32K到64M。当数据集比较小的时候、L1、L2、L3还能抗一抗。但当增加到16M、64M以后,穿透到内存的IO情况会变多,穿透过去以后极大可能行地址也会变。在64M的数据集中,内存的延时竟然下降到了38.4ns.
总结
内存存在随机访问比顺序访问慢的多的情况,大概是4:1的关系。
内存带宽
理论上内存带宽的计算公式是:Band Width = Speed * Data Width。
在DDR3,1067MHz的条件下,测量的实际带宽:
在数据较小,实际内存IO发生的很少时,大部分都是更高效的L1 cache的IO,在CPU内部就完成了。但最高值也才6G而已,也没有达到厂家宣称的8GB。
在随机IO工作模式的情况下,带宽只有474M而已。现在SSD固态硬盘顺序IO也差不多能达到这个数量级了
内核对内存的使用
不同于给应用程序提供的虚拟内存机制,内核使用slab的分配器来申请内存。比如TCP连接时内存的运用等等。
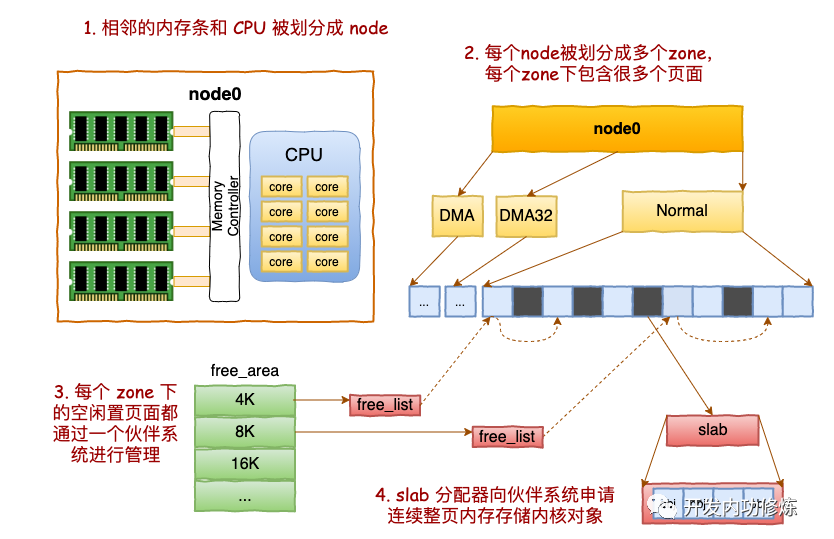
对于各个内核运行中实际使用的对象来说,多大的对象都有。有的对象有1K多,但有的对象只有几百、甚至几十个字节。如果都直接分配一个 4K的页面 来存储的话也太败家了,所以伙伴系统并不能直接使用。
在伙伴系统之上,内核又给自己搞了一个专用的内存分配器, 叫slab或slub。
这个分配器最大的特点就是,一个slab内只分配特定大小、甚至是特定的对象。这样当一个对象释放内存后,另一个同类对象可以直接使用这块内存。通过这种办法极大地降低了碎片发生的几率。
slab相关的内核对象定义如下:
//file: include/linux/slab_def.h
struct kmem_cache {
struct kmem_cache_node **node
......
}
//file: mm/slab.h
struct kmem_cache_node {
struct list_head slabs_partial;
struct list_head slabs_full;
struct list_head slabs_free;
......
}每个cache都有满、半满、空三个链表。每个链表节点都对应一个 slab,一个 slab 由 1 个或者多个内存页组成。
在每一个 slab 内都保存的是同等大小的对象。 一个cache的组成示意图如下:
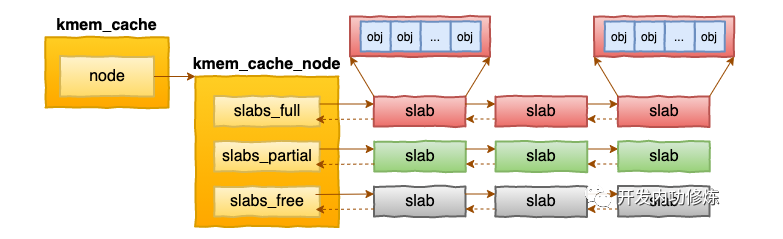
当 cache 中内存不够的时候,会调用基于伙伴系统的分配器(__alloc_pages函数)请求整页连续内存的分配。
关于内存问题的例子
Redis存储结构的设计
需求
需求的几个关键点:
- 每个数据id是一个int整数来表示
- 每个用户要保存1万条id
- 每次用户刷新开始的时候需要将这1万条历史全部读取出来过滤一遍
- 每次用户刷新结束的时候需要将新访问过的10条写入一遍,如果超过1万需将最早的记录挤掉
所以,每次用户访问的时候,会涉及到一个1万规模的数据集上的一次读取和一次写入操作。
Redis的两种使用方法
用list存储
用string存储
把1万个int表示的数据id拼接成一个字符串,用一个特殊的字符把他们分割开。例如:”100000_100001_10002”这种。存储的时候,拼接一下,然后把这个大字符串写到Redis里。读取的时候,把大字符串整体读取出来,然后再用字符切割成数组来使用。
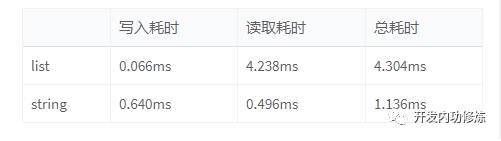
测试结果
结果分析
List
基于list的方案里,写入速度非常快,只需要0.066ms,因为仅仅只需要写入新添加的10条记录就可以了,再加一次链表的截断操作,
但是读取性能可就要慢很多了,超过了4ms。原因之一是因为读取需要整体遍历,但其实还有第二个原因。我们本案例中的数据量过大,所以Redis在内部实际上是用双端链表来实现的。链表是通过指针串起来的。大量的node之间极大可能是随机地分布在内存的各个位置上,这样你遍历整个链表的时候,实际上大概率会导致内存的随机模式下工作。.
String
基于string方案在写入的时候耗时比list要高,因为每次都得需要将1万条全部写入一遍。
但是读取性能却比list高了10倍,这和Redis的String数据结构有关(底层是个数组来保存)。用string来存储的话,不管用户的数据id有多少,访问将全部都是顺序IO。顺序IO的好处有两点:
- 一内存的顺序IO的耗时大约只是随机IO的1/3-1/4左右,
- 对于读取来说,顺序访问将极大地提升CPU的L1、L2、L3的cache命中率
Redis内存过高性能将急剧下降
由NUMA陷阱引起的
实验1
在zone_reclaim_mode为1的情况下,Redis是平均在两个node里申请节点的,并没有固定在某一个cpu里。
因为如果不绑定亲和性的话,分配内存是当进程在哪个node上的CPU发起内存申请,就优先在哪个node里分配内存。之所以是平均分配在两个node里,是因为redis-server进程实验中经常会进入主动睡眠状态,醒来后可能CPU就换了。所以基本上,最后看起来内存是平均分配的。如下图,CPU进行了500万次的上下文切换,用top命令看到cpu也是在node0和node1跳来跳去。
实验2
绑定CPU和内存的亲和性,然后再启动。
numactl --cpunodebind=0 --membind=0 /search/odin/daemon/redis/bin/redis-server /search/odin/daemon/redis/conf/redis.conf这时候,Redis实际使用的物理内存RES定格到了30g不再上涨,而是开始消耗Swap。又过了一会儿,Redis被oom给kill了。
当通过
numactl绑定CPU和mem都在一个node里的时候,内存IO不需要经过总线,性能会比较高,你Redis的QPS能力也会上涨



