《开发内功修炼-磁盘篇》学习笔记
目录
- 磁盘结构
- 机械硬盘
- 固态硬盘
- Linux查看磁盘信息
- 磁盘IO
- IO延时
- Linux IO 读取
- Linux IO 写入
- 磁盘的随机IO和顺序IO
- 磁盘分区
- 文件系统
参考/来源
- 《开发内功修炼》微信公众号
磁盘结构
机械硬盘
结构
常见的机械磁盘,分磁盘面、磁道、柱面和扇区。
机械硬盘拆开以后,结构如下:

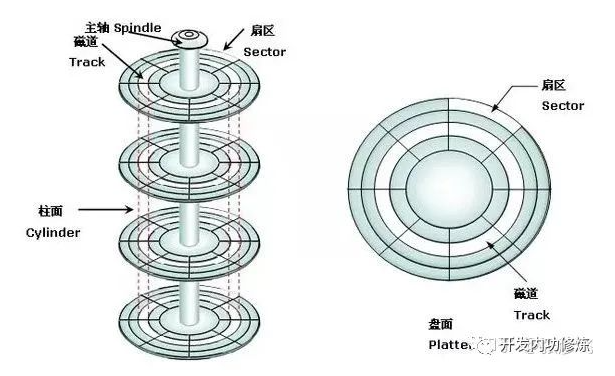
可见有以下概念 :
磁盘面:磁盘是由一叠磁盘面叠加组合构成,每个磁盘面上都会有一个磁头负责读写。
磁道(Track):每个盘面会围绕圆心划分出多个同心圆圈,每个圆圈叫做一个磁道。
柱面(Cylinders):所有盘片上的同一位置的磁道组成的立体叫做一个柱面。
扇区(Sector):以磁道为单位管理磁盘仍然太大,所以计算机前辈们又把每个磁道划分出了多个扇区。
**所以,磁盘存储的最小组成单位就是扇区。 **
单柱面的存储容量 = 每个扇区的字节数 * 每柱面扇区数 * 磁盘面数
整体磁盘的容量 = 单柱面容量 * 总的柱面数字。
RAID
把带有机械技术基因的磁盘搭到计算机,尤其是再应用到服务器领域的时候,暴露出了机械技术的两个严重问题:
第一,速度慢。如果把内存和CPU的速度比作汽车和飞机的话,这个大哥毫秒级别的延迟几乎就是牛车级别的。
第二,容易坏。经常听说谁谁的磁盘坏了,很少有听说过谁的内存条,CPU坏了。笔者就有在读研期间实验室里正在拷贝资料,突然一个断电直接废了一块硬盘的经历。
RAID即是为了解决机械硬盘既慢又容易坏的问题,应运而生。
多硬盘连接
RAID0
把一个文件分成N片,每一片都散列在不同的硬盘上。这样当文件进行读取的时候,就可以N块硬盘一起来工作,从而达到读取速度提高到N倍的效果,这就是RAID 0。
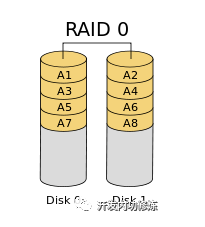
不过这个方案没有解决容易坏的问题,任何一块硬盘坏了都会导致存储系统故障。
RAID1
仍然把文件分片,但是所有的分片都存在一块硬盘上,其它的硬盘只存拷贝。这既提高了硬盘的访问速度,也解决了坏的问题。任意一块硬盘坏了,存储系统都可以正常使用,只不过速度会打一点折扣。
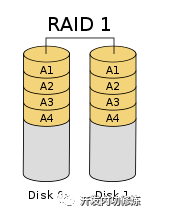
不过这个方案又带来了新的问题,那就是实现成本有点高了。假如我们用256G硬盘想实现512G的存储容量的话,最少得需要4块硬盘才能实现。
RAID5
最常见的raid5 RAID 5同样要对文件进行分片,但是不对存储的数据进行备份,而是会再单独存一个校验数据片。假如文件分为A1 A2 A3,然后需要再存一个校验片到别的磁盘上。这样不管A1,A2还是A3那一片丢失了,都可以根据另外两片和校验片合成出来。既保证了数据的安全性,又只用了一块磁盘做冗余存储。
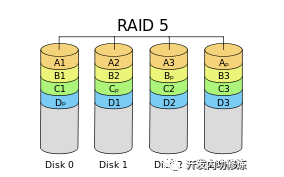
假如我们有8块256GB的硬盘,那么RAID5方案下的磁盘阵列从用户角度来看可用的存储空间是7256GB,只“浪费”了一块盘的空间,所以*目前RAID5应用比较广泛~~
RAID缓存
磁盘本身也基本都带了缓存,另外在一些比较新的raid卡里,硬件开发者们又搞出来了一层“内存”,并且还自己附带一块电池,这就是RAID卡缓存。
电池的作用就是当发现主机意外断电的时候,能够快速把缓存中的数据写回到磁盘中去。对于写入,一般操作系统写到这个RAID卡里就完事了,所以速度快。对于读取也是,只要缓存里有,就不会透传到磁盘的机械轴上。
PERC S120 入门软件阵列卡,主板集成无缓存 支持RAID0 1
PERC H330 入门硬件RAID卡,无板载缓存, 支持RAID 0 1 5 10 50
PERC H730 主流硬件RAID卡带有1G缓存和电池 支持RAID 0 1 5 6 10 50 60
PERC H730P 高性能硬件RAID卡带有2G缓存和电池 支持RAID 0 1 5 6 10 50 60
PERC H830 同H730P,没有内置接口,使用外置接口连接附加存储磁盘柜用
固态硬盘
结构
机械硬盘和ssd虽然都同为硬盘,但底层实现技术却完全不一样,机械硬盘使用的是磁性材料记忆,而SSD用的是类似u盘的闪存技术。实现技术的不同,必然在硬盘内部结构上他们就有天壤之别。他们的果照对比如下图所示:

SSD是由一些电路和黑色的存储颗粒构成。
SSD硬盘是基于NAND Flash存储技术的,属于非易失性存储设备,换成人话说,就是掉电了数据不会丢。
其中每一个黑色的存储颗粒也叫做一个Die。我们“拆开”一个Die来看一下
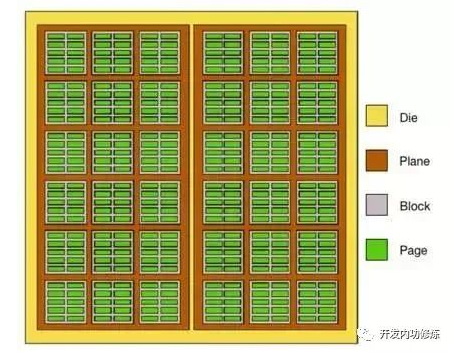
每个Die有若干个Plane
每个Plane有若干个Block
每个Block有若干个Page。
Page是磁盘进行读写的最小单位,一般为2KB/4KB/8KB/16KB等。
每一个Page里,又包含了许许多多的闪存单元。
现代的闪存单元有多种类型,目前主流的主要分为SLC、MLC和TLC。
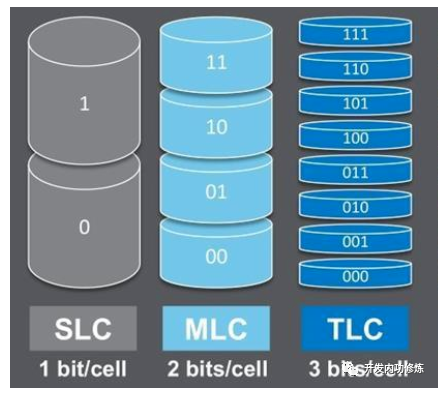
以上三种闪存单元对比:从性能和稳定性角度来看,SLC最好。从容量角度看,TLC最大。
这就是为什么日常我们看到的工业级的SSD要比笔记本SSD要贵很多,其中一个很重要的原因就是工业级的盘往往采用的闪存单元是SLC或MLC,而我们家用的笔记本一般都是TCL,因为便宜嘛。我们用表格再对它们直观对比一下:
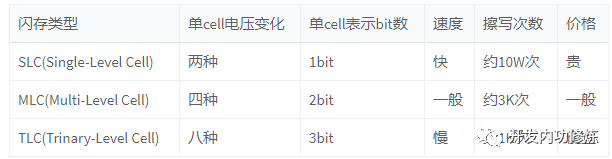
目前主流闪存类型TLC居多,因为价格便宜,容量大。
扇区
新的机械硬盘虽然把物理扇区已经做到4KB的了,但为了兼容老系统还得整出个逻辑扇区的概念来适配。到了SSD里也一样,虽然每一个物理Page的大小为2K到16K不等,但是为了兼容性,也必须得整出个逻辑扇区才行。
SSD控制器在逻辑上会把整个磁盘再重新划分成一个个的“扇区”,采用和新机械硬盘一样的LBA方式来进行编址(整个磁盘的扇区从0到某个最大值方式排列,并连成一条线)。、
当需要读取某几个”扇区”上数据的时候,SSD控制器通过访问这个LBA MapTable, 再来找到要实际访问的物理Page,如下图:
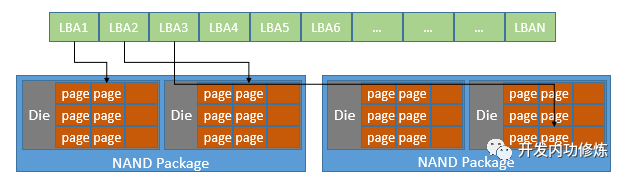
不过SSD最小的读写单位就是Page,他是没办法用扇区来进行读写的。
文件存储方式
假设某SSD的Page大小是4KB,一个文件是16KB。那么该文件是存在一个黑色的存储颗粒里,还是多个颗粒里?
我们先把SSD的逻辑结构用个直观一点的图来看:
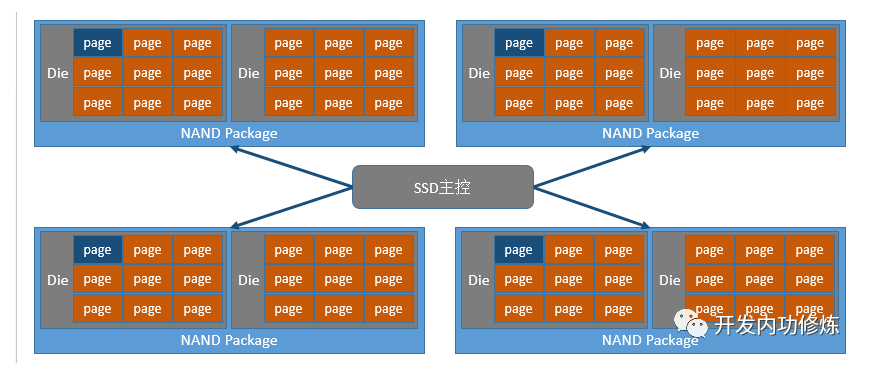
假设只写在一个颗粒里,那么对该文件进行读取的时候,就只能用到一条Flash通道,这样速度就会比较慢。如果存在相邻的4个颗粒里,每个写入4KB。这样多个Flash通道的带宽会充分发挥出来,传输速度也更快。所以,实际中是分散在多个。
Linux查看磁盘信息
lsblk,查看服务器上安装的硬盘数量以及大小# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb 8:16 0 20T 0 disk `-sdb1 8:17 0 20T 0 part /search sda 8:0 0 278.5G 0 disk |-sda1 8:1 0 200M 0 part /boot `-sda2 8:2 0 278.3G 0 part |-vgroot-lvroot (dm-0) 253:0 0 10G 0 lvm / |-vgroot-lvswap (dm-1) 253:1 0 8G 0 lvm [SWAP] |-vgroot-lvvar (dm-2) 253:2 0 15G 0 lvm /var |-vgroot-lvusr (dm-3) 253:3 0 10G 0 lvm /usr `-vgroot-lvopt (dm-4) 253:4 0 136.7G 0 lvm /optfdisk,查看硬盘更详细的信息#fdisk -l /dev/sda Disk /dev/sda: 299.0 GB, 298999349248 bytes 255 heads, 63 sectors/track, 36351 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disk identifier: 0x00053169 Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 36352 291785728 8e Linux LVMsda这块磁盘:有255个heads(磁头),也就是说共有255个盘面。
36351个cylinders,也就是说每个盘面上都有36351个磁道,
63sectors/track说的是每个磁道上共有63个扇区。
逻辑扇区大小是512 bytes
上面的Units说的是每个磁道的存储容量大小
几个特殊的参数:
physical Sector size
现代科技进步了,磁盘底层的最小组成单位并不是扇区512字节,而是physical Sector size 4KB。
但这时存在一个问题是扇区大小为512字节的假设已经贯穿于整个软件链,比如BIOS,启动加载器,操作系统内核,文件系统代码,以及磁盘工具,等等。直接切换到4096 byte兼容性问题太大了,所以每个新的磁盘控制器将4096字节的物理扇区对应成了8个512字节的逻辑扇区,兼容各种老软件。
虚拟的磁头head和磁道cylinders
从磁盘上拆下来的磁头的真实照片

上面的图片里只有几个磁头,如果硬盘里真的装下255个这样的磁头的话,很难想象磁盘得有多厚。而且磁头多了以后硬盘的可靠性就越差,因为多磁头出故障的几率总会比单磁头要高一些。所以
fdisk -l里看到的255 heads其实和扇区一样,也是虚拟出来的。 另外cylinders也一样,也是虚拟出来的。
磁盘IO
IO延时
读写原理说起来也简单,就是磁头要找到指定的磁道,指定的扇区,进而把数据读取出来或者写入进去的过程。这个过程分成如下三步:
- 第一步,首先是磁头径向移动来寻找数据所在的磁道。这部分时间叫寻道时间。寻道时间,现代磁盘大概在3-15ms,其中寻道时间大小主要受磁头当前所在位置和目标磁道所在位置相对距离的影响
- 第二步,找到目标磁道后通过盘面旋转,将目标扇区移动到磁头的正下方,这部分时间叫旋转延迟。现在主流服务器上经常使用的是1W转/分钟的磁盘,每旋转一周所需的时间为60*1000/10000=6ms,故其旋转延迟为(0-6ms)
- 第三步,向目标扇区读取或者写入数据,这部分时间叫存取时间。这个是电磁操作,所以一般耗时较短,为零点几ms。
到此为止,单次磁盘IO时间 = 寻道时间 + 旋转延迟 + 存取时间
Linux IO 读取
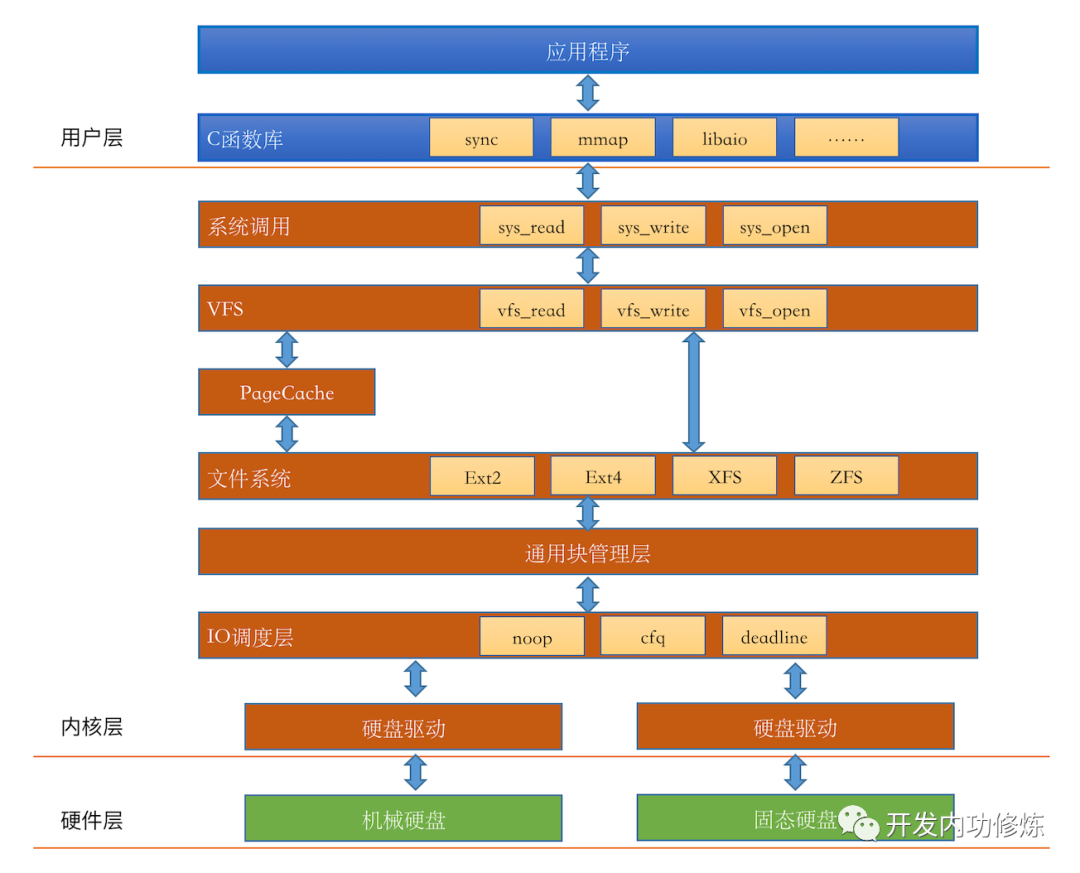
Linux读取文件的过程:
.png)
如果 Page Cache 命中的话,根本就没有磁盘 IO 产生。
假如 Page Cache 没有命中,访问磁盘缓存
因为现在的磁盘本身就会带一块缓存。另外现在的服务器都会组建磁盘阵列,在磁盘阵列里的核心硬件Raid卡里也会集成RAM作为缓存。只有所有的缓存都不命中的时候,机械轴带着磁头才会真正工作。
缓存没有命中,进行磁盘IO
- Page Cache 是以页为单位的,Linux 页大小一般是 4KB
- 文件系统是以块(block)为单位来管理的。使用
dumpe2fs可以查看,一般一个块默认是 4KB - 通用块层是以段为单位来处理磁盘 IO 请求的,一个段为一个页或者是页的一部分
- IO 调度程序通过 DMA 方式传输 N 个扇区到内存,扇区一般为 512 字节
- 硬盘也是采用“扇区”的管理和传输数据的
Linux IO 写入
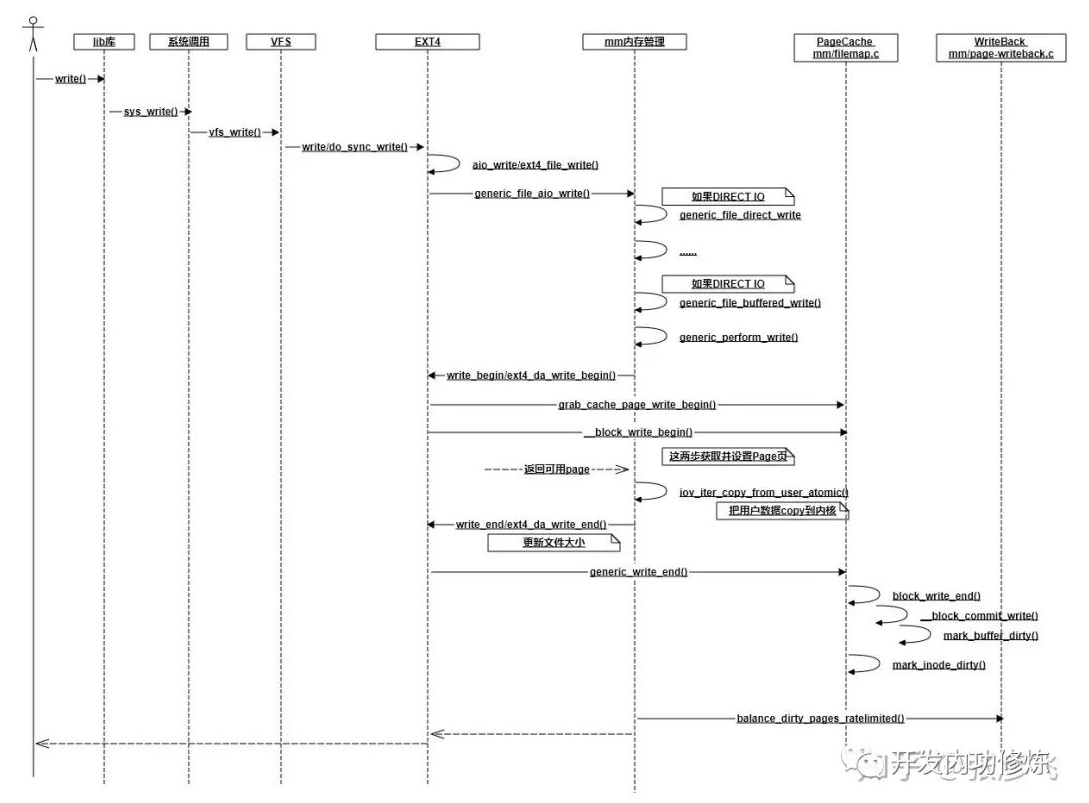
绝大部分情况都是写入到PageCache中就返回了,这时并没有真正写入磁盘。我们的数据会在如下三个时机下被真正发起写磁盘IO请求:
- 第一种情况,如果write系统调用时,如果发现PageCache中脏页占比太多,超过了dirty_ratio或dirty_bytes,write就必须等待了。
- 第二种情况,write写到PageCache就已经返回了。worker内核线程异步运行的时候,再次判断脏页占比,如果超过了dirty_background_ratio或dirty_background_bytes,也发起写回请求。
- 第三种情况,这时同样write调用已经返回了。worker内核线程异步运行的时候,虽然系统内脏页一直没有超过dirty_background_ratio或dirty_background_bytes,但是脏页在内存中呆的时间超过dirty_expire_centisecs了,也会发起回写。
如果对以上配置不满意,你可以自己通过修改/etc/sysctl.conf来调整,修改完了别忘了执行sysctl -p。
磁盘的随机IO和顺序IO
机械硬盘在顺序IO和随机IO下的巨大性能差异。
在顺序IO情况下,磁盘是最擅长的顺序IO,再加上Raid卡缓存命中率也高。这时带宽表现有几十、几百M,最好条件下甚至能达到1GB。IOPS这时候能有2-3W左右。
到了随机IO的情形下,机械轴也被逼的跳来跳去寻道,RAID卡缓存也失效了。带宽跌到了1MB以下,最低只有100K,IOPS也只有可怜巴巴的200左右。
很多工程实践中的许多的事情都和这个有关:
复制文件夹:我们都知道,在复制一个文件夹的时候,如果这个文件夹里面包含了许多堆碎文件,这时候复制起来非常慢。原因就是这时候机械硬盘大概率都是在随机IO。怎么提高复制速度呢?很简单,就是把它们先打一个包。打包之后这个文件夹就变成一个大文件了,这时候再复制的话,磁盘就是执行的最擅长的顺序IO了,所以会快很多。
数据库事务:所有的数据库在实现事务的时候,都要保证写数据落盘成功才能返回。但为什么他们几乎都是落盘到自己的事务日志文件里去就返回成功的,而不是直接写入到数据表文件里。这背后的原因还是磁盘读写性能问题,事务只需要保证数据落地成功就可以,至于写到哪里并不重要。写到数据文件中的话大概率就变成随机IO了。如果写到一个日志文件中,就是地地道道的顺序IO,性能就发挥到极致。
Mysql的B+树:无论是顺序IO还是随机IO,只要增加每次IO的单位,性能都会上涨。理解了这个,你就能真正理解为什么Mysql是采用B+树当索引,而不是用其它的树了(比如二叉树)。因为B+树的节点更大,IO起来会让磁盘工作更舒服一些。
磁盘分区
分区方式
考虑磁盘IO时间,采用柱面进行分区,如
3263个柱面,C盘0-1000个柱面,D盘1001-20001个柱面,……这样而来,对于磁盘C,只需要在磁头在1-1000个磁道间移动就可以了,大大降低了寻道时间。
fdisk命令分区分区的过程就是你输入起始柱面号和截至柱面号的过程。
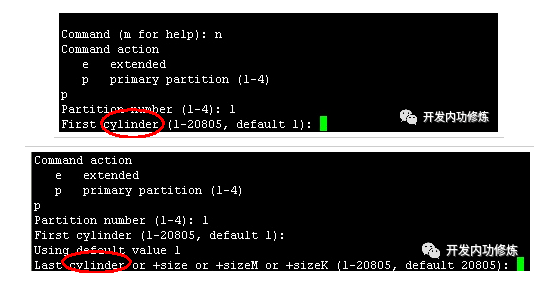
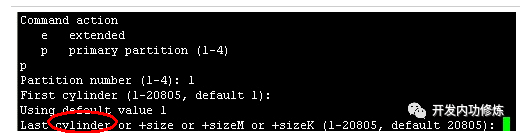
不过在实际中,分区并不能从0号柱面开始的,因为磁盘的第一个磁道对应的柱面会被用来安装引导加载程序以及磁盘分区表。
文件系统
空文件占用多少磁盘空间
Inode占用
新建一个空文件会占用一个Inode。
Linux的inode结构
struct ext2_inode { __le16 i_mode; # 文件权限 __le16 i_uid; # 文件所有者ID __le32 i_size; # 文件字节数大小 __le32 i_atime; # 文件上次被访问的时间 __le32 i_ctime; # 文件创建时间 __le32 i_mtime; # 文件被修改的时间 __le32 i_dtime; # 文件被删除的时间 __le16 i_gid; # 文件所属组ID __le16 i_links_count; # 此文件的inode被连接的次数 __le32 i_blocks; # 文件的block数量 ...... __le32 i_block[EXT2_N_BLOCKS]; # 指向存储文件数据的块的数组 ......stat命令查看文件inode中数据# stat test File: `test' Size: 0 Blocks: 0 IO Block: 1024 regular empty file Device: 801h/2049d Inode: 26 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2020-03-01 12:14:31.000000000 +0800 Modify: 2020-03-01 12:14:31.000000000 +0800 Change: 2020-03-01 12:14:31.000000000 +0800dumpe2fs命令查看inode大小# dumpe2fs -h /dev/mapper/vgroot-lvroot dumpe2fs 1.41.12 (17-May-2010) ...... Inode size: 256
占用其父目录空间
文件名存储在目录结构中。
struct ext2_dir_entry {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__le16 name_len; /* Name length */
char name[]; /* File name, up to EXT2_NAME_LEN */
};这个结构体就是我们司空见惯的文件夹所使用的数据结构,每个文件都占用一个ext2_dir_entry。没错,文件名是存在其所属的文件夹中的,就是其中的char name[]字段。和文件名一起,文件夹里还记录了该文件的inode号等信息。
和空文件一样,空的文件夹也会消耗掉一个inode。
一个文件夹当然消耗的磁盘空间:
- 首先要消耗掉一个inode,我的机器上它是256字节
- 需要消耗其父目录下的一个目录项
ext4_dir_entry,保存自己inode号,目录名。 - 其下面如果创建文件夹或者文件的话,它就需要在自己的block里保存
ext4_dir_entry数组
目录下的文件/子目录越多,目录就需要申请越多的block。另外ext4_dir_entry大小不是固定的,文件名/子目录名越长,单个目录项消耗的空间也就越大。
进一步的,结合后面格式化中块组group知识点,创建目录的过程为:
创建目录的时候,操作系统会在inode位图上寻找尚未使用的inode编号,找到后把inode分配给你。
目录会默认分配一个block,所以还需要查询block位图,找到后分配一个block。在block里面,存储的就是文件系统自己定义的目录项数据结构了,例如ext4_dir_entry_2。每一个结构里会保存其下的文件名,文件的inode编号等信息。某个实际文件夹在磁盘上最终使用的空间如下图所示:
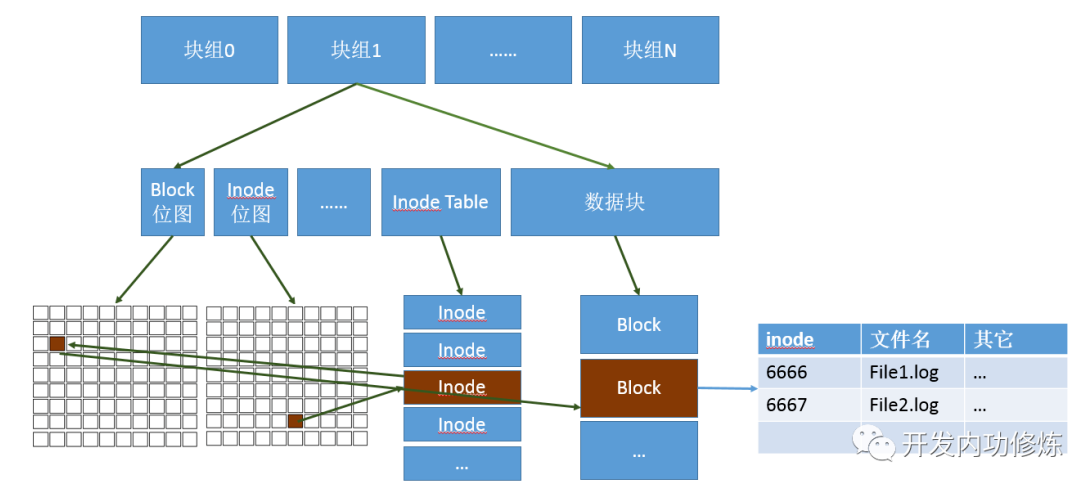
目录的block中保存的是其下面的文件和子目录的目录项结构体,保存着它们的文件名和inode号。理解了目录,对于文件也是一样的。也需要消耗inode,当有数据写入的时候,再去申请block。
1个字节的文件占用多少磁盘空间
文件里的内容不论多小,哪怕是一个字节,其实操作系统也会给你分配4K的。
inode结构中的block数组
struct ext2_inode { ...... __le32 i_block[EXT2_N_BLOCKS]; # 指向存储文件数据的块的数组 ......当文件没有数据需要存储的时候,这个数组都是空值。
而当我们写入了1个字节以后,文件系统就需要申请block去存储了,申请完后,指针放在这个数组里。哪怕文件内容只有一个字节,仍然会分配一个整的Block,因为这是文件系统的最小工作单位。
那么这个block大小是多大呢,ext下可以通过
dumpe2fs查看。#dumpe2fs -h /dev/mapper/vgroot-lvroot ...... Block size: 4096
大文件的block分级存储
inode中定义的block数组大小呢,只有EXT2_N_BLOCKS个。我们再查看一下这个常量的定义,发现它是15,相关内核中定义如下:
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)就按4K的block size来看,15个block只够存的下15*4=60K的文件。 这个文件大小相信你一定不满意,你存一个avi大片都得上G了。那Linux是怎么实现大文件存储的呢?嗯,其实上面宏的定义过程已经告诉你了,就是只有12个数组直接存block指针,其余的用来做间接索引(EXT2_IND_BLOCK),二级间接索引(EXT2_DIND_BLOCK)和三级索引(EXT2_TIND_BLOCK)。
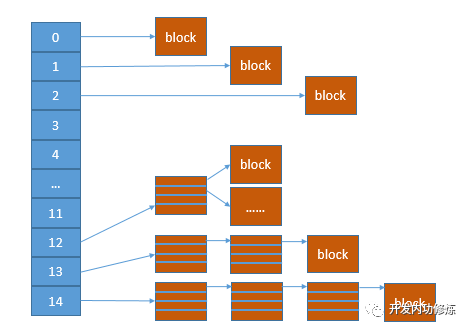
这样,一个文件可以使用的空间就指数倍的扩展了。 文件小的时候,都用直接索引,磁盘IO少,性能好。文件大的时候,访问一个block可能得先进行三次的IO,性能略慢,不过有OS层面的页缓存、目录项缓存的加持,也还好。
删除文件后依然占空间
文件夹下的文件都已经删了,该文件夹为什么还占用72K的磁盘空间?
问题关键在于ext4_dir_entry中的rec_len。这个变量存储了当前整个ext4_dir_entry对象的长度,这样操作系统在遍历文件夹的时候,就可以通过当前的指针,加上这个长度就可以找到文件夹中下一个文件的dir_entry了。这样的优势是遍历起来非常方便,有点像是一个链表,一个一个穿起来的。
但是,如果要删除一个文件的话,就有点小麻烦了,当前文件结构体变量不能直接删,否则链表就断了。Linux的做法是在删除文件的时候,在其目录中只是把inode设置为0就拉倒,并没有回收整个ext4_dir_entry对象。
其实和大家做工程的时候经常用到的假删除是一个道理。现在的xfs文件系统好像已经没有这个小问题了,但具体咋解决的,暂时没有深入研究。
格式化
Linux下的格式化命令是mkfs.
mkfs在格式化的时候需要制定分区以及文件系统类型。该命令其实就是把我们的连续的磁盘空间进行划分和管理。
# mkfs -t ext4 /dev/vdb
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
6553600 inodes, 26214400 blocks
1310720 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=2174746624
800 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872块大小、block数量、inode数量
其中块大小、block数量、inode数量可以根据具体业务逻辑进行修改。
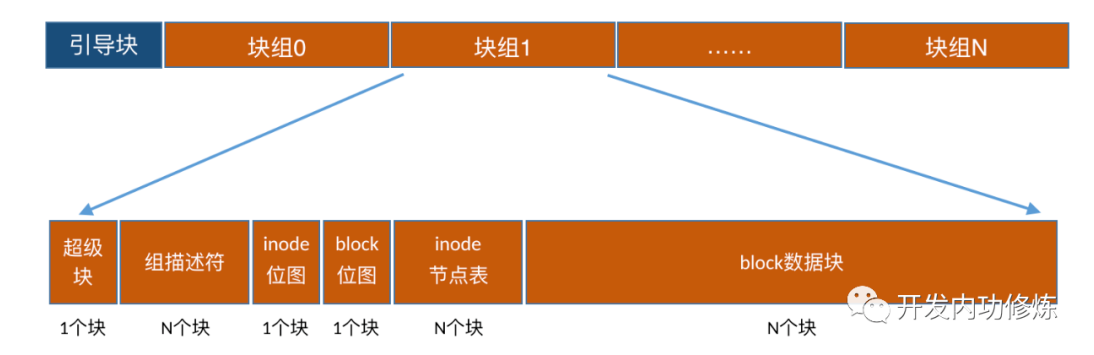
mke2fs,这个命令允许你输入更详细的格式化选项,demo如下:mke2fs -j -L "卷标" -b 2048 -i 8192 /dev/sdb1块组groups
格式化后的所有inode并不是挨着一起放的,同样block也不是。而是分成了一个个的group,每一个group里都有一些inode和block。逻辑图如下: