《开发内功修炼-网络篇》学习笔记
目录
- Linux网络收包
- TCP连接的深入分析
参考/来源
- 《开发内功修炼》微信公众号
Linux网络收包
demo代码
int main(){
int serverSocketFd = socket(AF_INET, SOCK_DGRAM, 0);
bind(serverSocketFd, ...);
char buff[BUFFSIZE];
int readCount = recvfrom(serverSocketFd, buff, BUFFSIZE, 0, ...);
buff[readCount] = '\0';
printf("Receive from client:%s\n", buff);
}Linux的TCP/IP模型
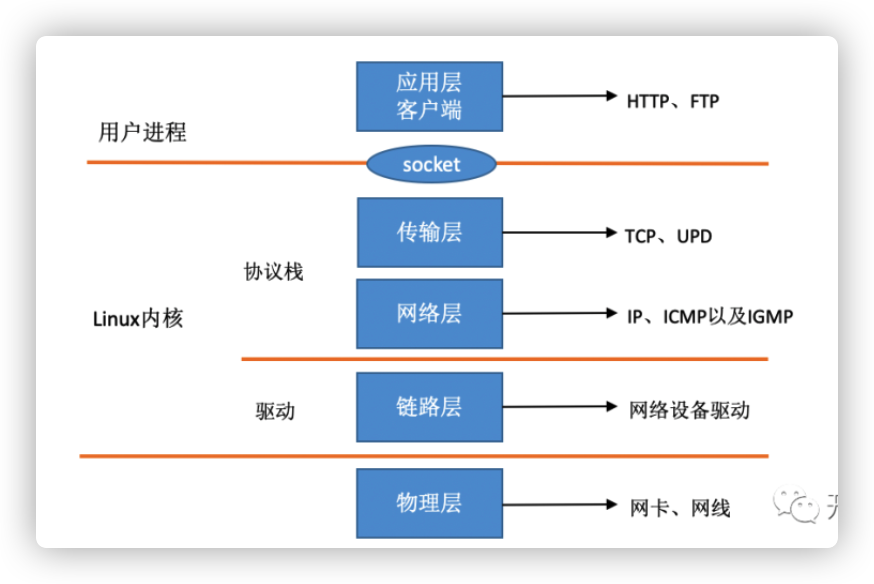
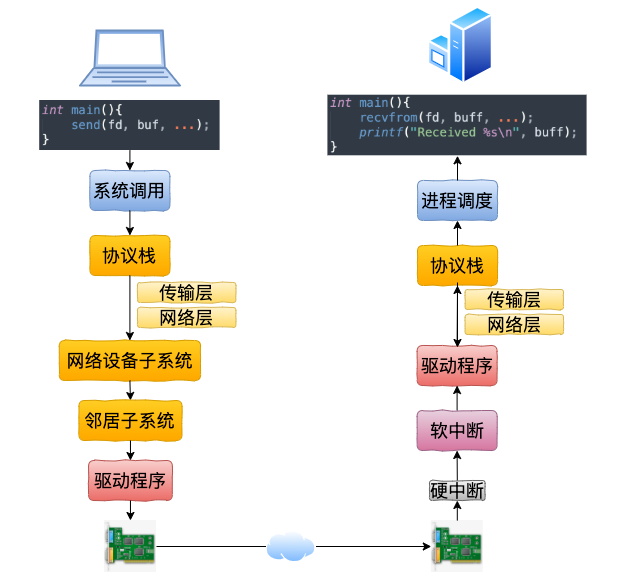
内核和网络设备驱动是通过中断的方式来处理的。
当设备上有数据到达的时候,会给CPU的相关引脚上触发一个电压变化,以通知CPU来处理数据。
对于网络模块来说,由于处理过程比较复杂和耗时,如果在中断函数中完成所有的处理,将会导致中断处理函数(优先级过高)将过度占据CPU,将导致CPU无法响应其它设备,例如鼠标和键盘的消息。因此Linux中断处理函数是分上半部和下半部的。
上半部是只进行最简单的工作,快速处理然后释放CPU,接着CPU就可以允许其它中断进来。剩下将绝大部分的工作都放到下半部中,可以慢慢从容处理。
2.4以后的内核版本采用的下半部实现方式是软中断,由ksoftirqd内核线程全权处理。
和硬中断不同的是,硬中断是通过给CPU物理引脚施加电压变化,而软中断是通过给内存中的一个变量的二进制值以通知软中断处理程序。
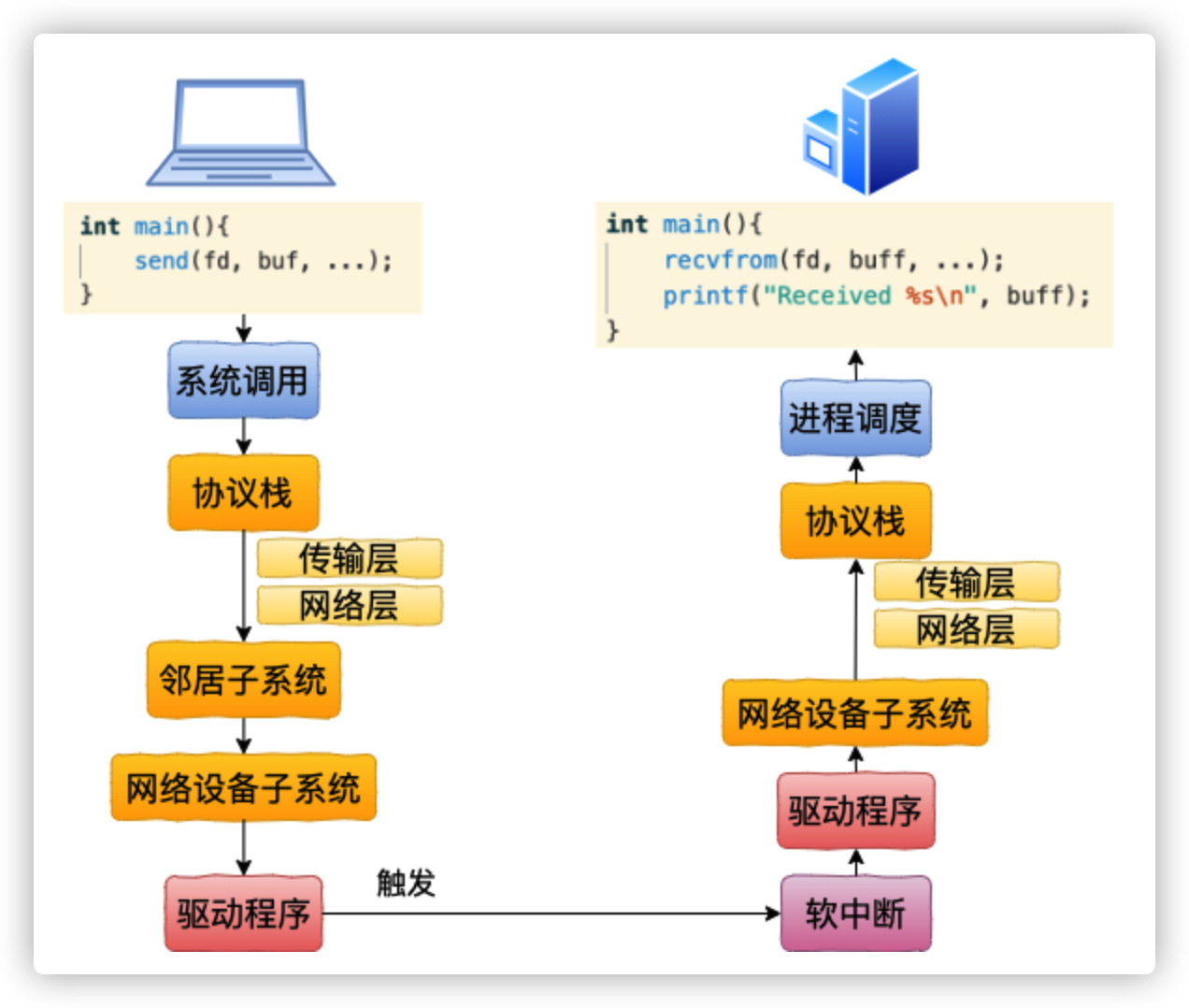
整体流程图
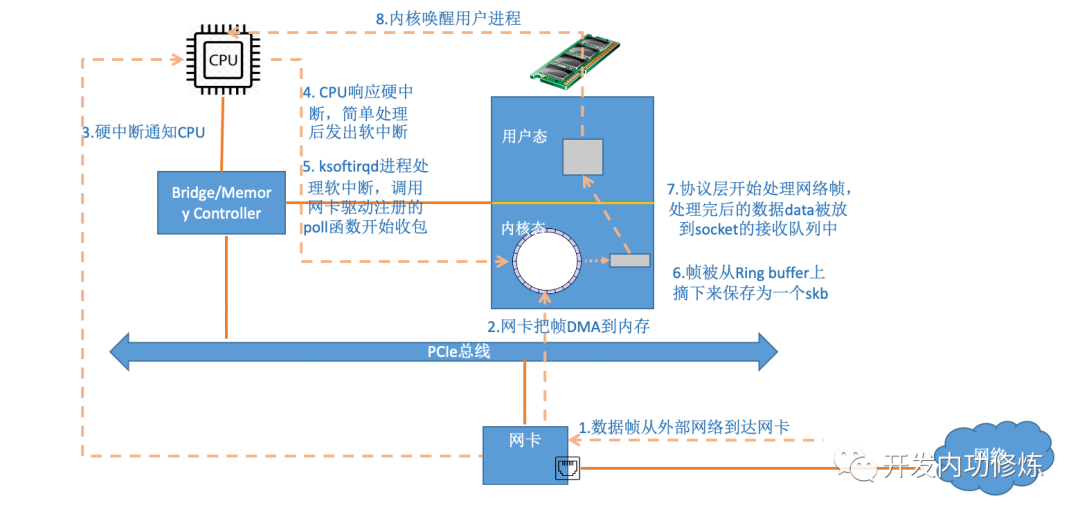
当网卡上收到数据以后,Linux中第一个工作的模块是网络驱动。
网络驱动会以DMA的方式把网卡上收到的帧写到内存里。
再向CPU发起一个中断,以通知CPU有数据到达。
当CPU收到中断请求后,会去调用网络驱动注册的中断处理函数。
网卡的中断处理函数并不做过多工作,发出软中断请求,然后尽快释放CPU。
ksoftirqd检测到有软中断请求到达,调用poll开始轮询收包
收到后交由各级协议栈处理。
每帧数据被保存为一个socketbuffer
对于UDP包来说,会被放到用户socket的接收队列中。
流程分析
原文章中有大量的源码分析过程,这里就直接记一下结论了。
当用户执行完recvfrom调用后,用户进程就通过系统调用进行到内核态工作了。如果接收队列没有数据,进程就进入睡眠状态被操作系统挂起。这块相对比较简单,剩下大部分的戏份都是由Linux内核其它模块来表演了。
准备工作
首先在开始收包之前,Linux要做许多的准备工作:
创建ksoftirqd线程,为它设置好它自己的线程函数,后面指望着它来处理软中断呢
协议栈注册,linux要实现许多协议,比如arp,icmp,ip,udp,tcp,每一个协议都会将自己的处理函数注册一下,方便包来了迅速找到对应的处理函数
网卡驱动初始化,每个驱动都有一个初始化函数,内核会让驱动也初始化一下。在这个初始化过程中,把自己的DMA准备好,把NAPI的poll函数地址告诉内核
启动网卡,分配RX,TX队列,注册中断对应的处理函数
以上是内核准备收包之前的重要工作,当上面都ready之后,就可以打开硬中断,等待数据包的到来了。
接收数据
当数据到来了以后,第一个迎接它的是网卡:
- 网卡将数据帧DMA到内存的RingBuffer中,然后向CPU发起中断通知
- CPU响应中断请求,调用网卡启动时注册的中断处理函数
- 中断处理函数几乎没干啥,就发起了软中断请求
- 内核线程ksoftirqd线程发现有软中断请求到来,先关闭硬中断
- ksoftirqd线程开始调用驱动的poll函数收包
- poll函数将收到的包送到协议栈注册的ip_rcv函数中
- ip_rcv函数再讲包送到udp_rcv函数中(对于tcp包就送到tcp_rcv)
Linux网络发包
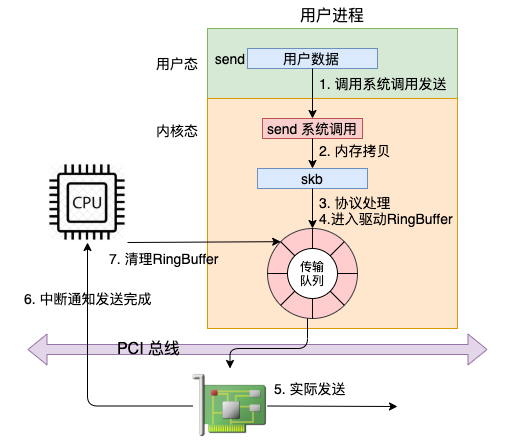
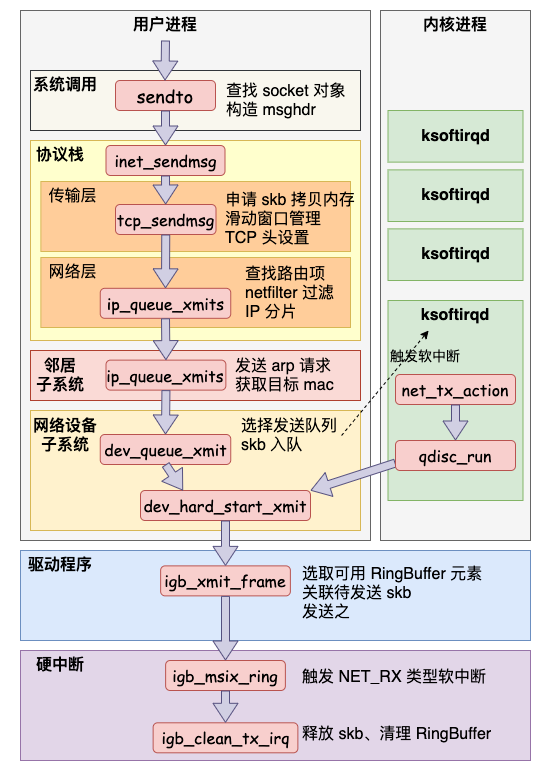
整体流程图
流程分析
网卡启动准备
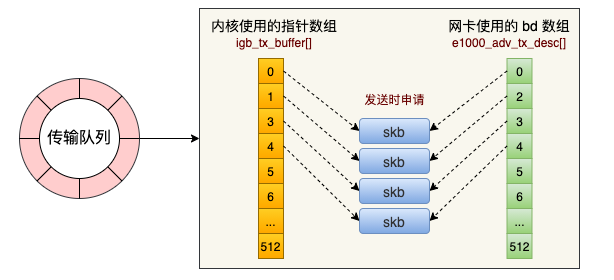
现在的服务器上的网卡一般都是支持多队列的。每一个队列上都是由一个 RingBuffer 表示的,开启了多队列以后的的网卡就会对应有多个 RingBuffer。
网卡在启动时最重要的任务之一就是分配和初始化 RingBuffer.
从源码可以看到,实际上一个 RingBuffer 的内部不仅仅是一个环形队列数组,而是有两个。
- igb_tx_buffer 数组:这个数组是内核使用的,通过 vzalloc 申请的。
- e1000_adv_tx_desc 数组:这个数组是网卡硬件使用的,硬件是可以通过 DMA 直接访问这块内存,通过 dma_alloc_coherent 分配。
这个时候它们之间还没有啥联系。将来在发送的时候,这两个环形数组中相同位置的指针将都将指向同一个 skb。这样,内核和硬件就能共同访问同样的数据了,内核往 skb 里写数据,网卡硬件负责发送。
accept 创建新 socket
在IO多路复用章节中详细介绍了,这里省略。
发送数据真正开始
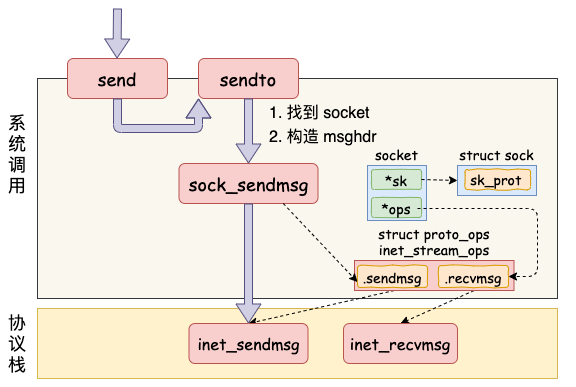
send系统调用
- 第一是在内核中把真正的 socket 找出来,在这个对象里记录着各种协议栈的函数地址。
- 第二是构造一个 struct msghdr 对象,把用户传入的数据,比如 buffer地址、数据长度啥的,统统都装进去.
传输层处理
在进入到协议栈 inet_sendmsg 以后,内核接着会找到 socket 上的具体协议发送函数。对于 TCP 协议来说,那就是 tcp_sendmsg(同样也是通过 socket 内核对象找到的)。
在这个函数中,内核会申请一个内核态的 skb 内存,将用户待发送的数据拷贝进去。注意这个时候不一定会真正开始发送,如果没有达到发送条件的话很可能这次调用直接就返回了。大概过程如图:
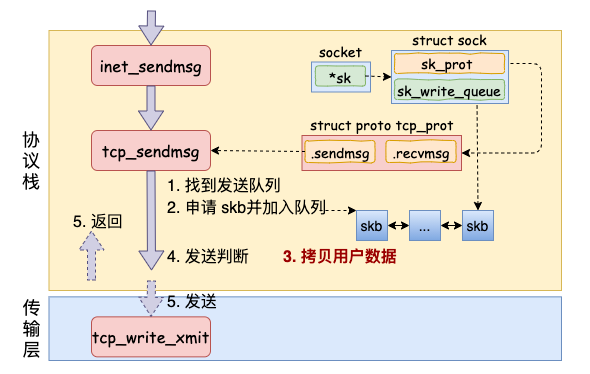
当满足真正发送条件的时候,无论调用的是 __tcp_push_pending_frames 还是 tcp_push_one 最终都实际会执行到 tcp_write_xmit。这个函数处理了传输层的拥塞控制、滑动窗口相关的工作。满足窗口要求的时候,设置一下 TCP 头然后将 skb 传到更低的网络层进行处理。
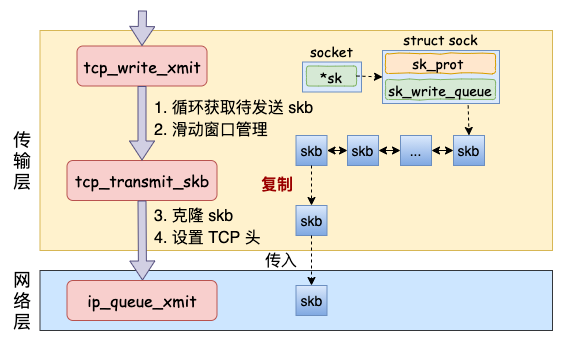
网络层发送处理
Linux 内核网络层的发送的实现位于 net/ipv4/ip_output.c 这个文件。传输层调用到的 ip_queue_xmit 也在这里。(从文件名上也能看出来进入到 IP 层了,源文件名已经从 tcp_xxx 变成了 ip_xxx。)
在网络层里主要处理路由项查找、IP 头设置、netfilter 过滤、skb 切分(大于 MTU 的话)等几项工作,处理完这些工作后会交给更下层的邻居子系统来处理。
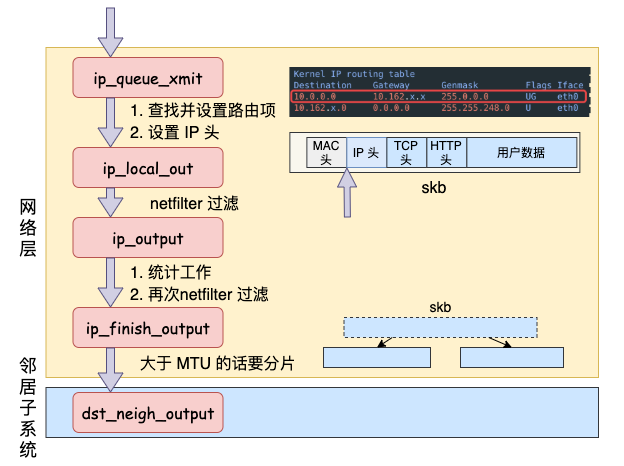
邻居子系统
邻居子系统是位于网络层和数据链路层中间的一个系统,其作用是对网络层提供一个封装,让网络层不必关心下层的地址信息,让下层来决定发送到哪个 MAC 地址。
而且这个邻居子系统并不位于协议栈 net/ipv4/ 目录内,而是位于 net/core/neighbour.c。因为无论是对于 IPv4 还是 IPv6 ,都需要使用该模块。
在邻居子系统里主要是查找或者创建邻居项,在创造邻居项的时候,有可能会发出实际的 arp 请求。然后封装一下 MAC 头,将发送过程再传递到更下层的网络设备子系统。大致流程如图:
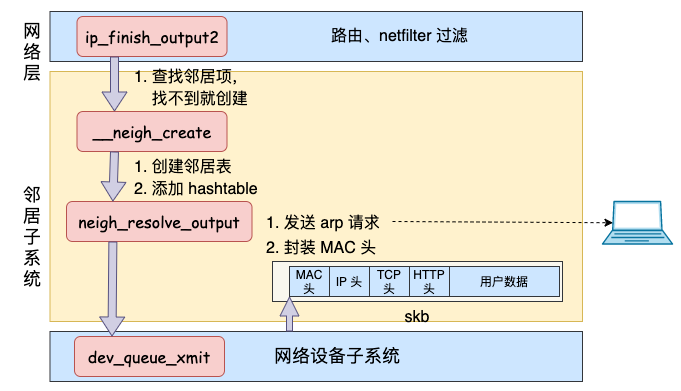
网络设备子系统
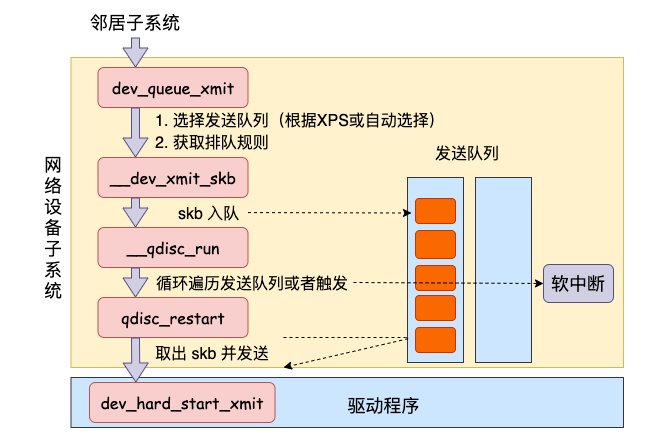
软中断调度
软中断是由内核线程来运行的,该线程会进入到 net_tx_action 函数,在该函数中能获取到发送队列,并也最终调用到驱动程序里的入口函数 dev_hard_start_xmit。
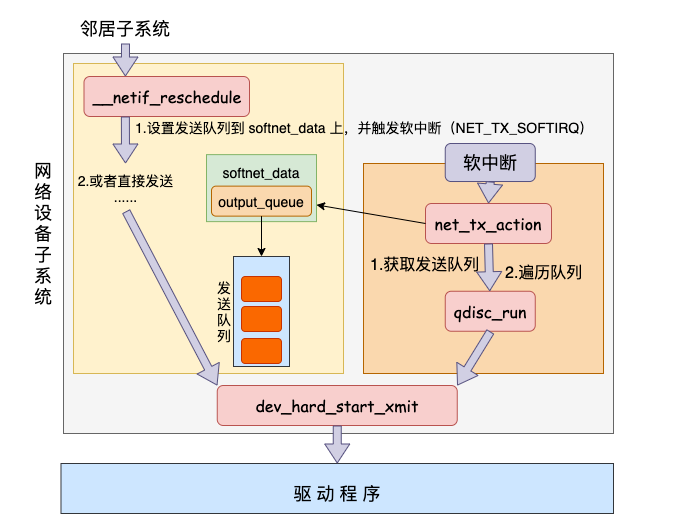
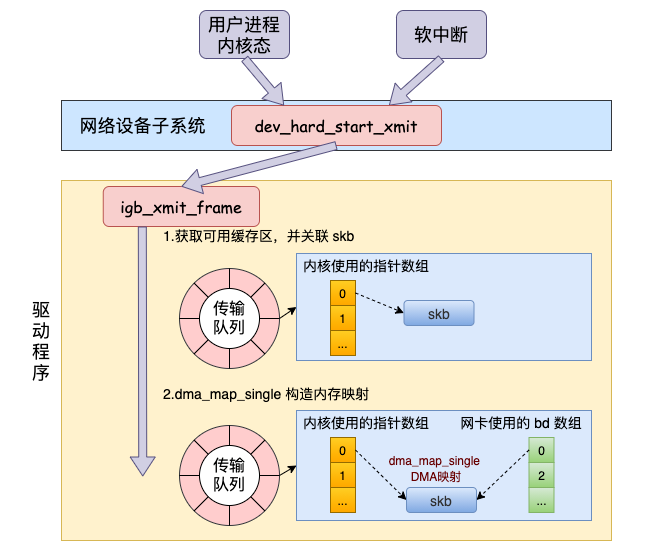
网卡驱动发送
调用到驱动里的发送函数 igb_xmit_frame,将 skb 会挂到 RingBuffer上,驱动调用完毕后,数据包将真正从网卡发送出去。
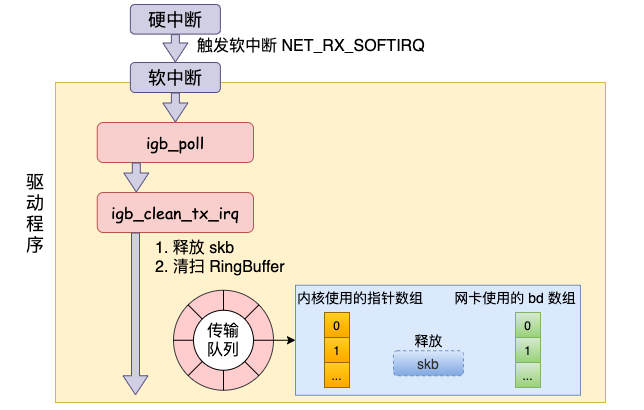
发送完成硬中断
当发送完成的时候,网卡设备会触发一个硬中断来释放内存,执行 RingBuffer 内存的清理工作。
本机网络通信过程
本机发送
在本机网络 IO 的过程中,和跨机流程会有一些差别,总共有两个,分别是路由和驱动程序。
网络层路由
对于本机网络 IO 来说,特殊之处在于在 local 路由表中就能找到路由项,对应的设备都将使用 loopback 网卡,也就是我们常见的 lo。
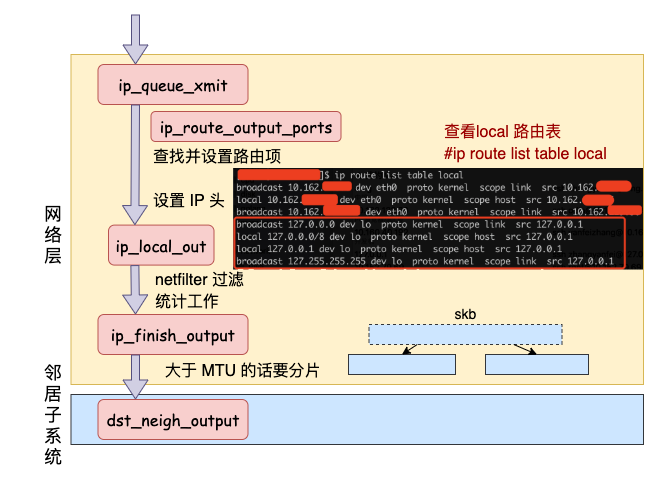
接下来的网络层仍然和跨机网络 IO 一样,最终会经过 ip_finish_output,最终进入到 邻居子系统的入口函数 dst_neigh_output 中。
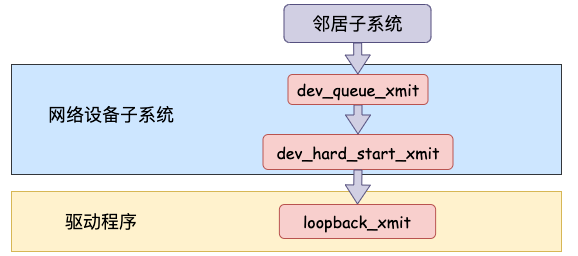
网络设备子系统
网络设备子系统的入口函数是 dev_queue_xmit。简单回忆下之前讲述跨机发送过程的时候,对于真的有队列的物理设备,在该函数中进行了一系列复杂的排队等处理以后,才调用 dev_hard_start_xmit,从这个函数 再进入驱动程序来发送。
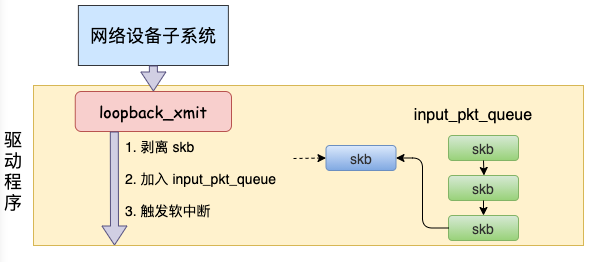
而本机通信没有队列的问题,直接进入 dev_hard_start_xmit。接着进入回环设备的“驱动”里的发送回调函数 loopback_xmit,将 skb “发送”出去。
驱动程序
对于真实的 igb 网卡来说,它的驱动代码都在 drivers/net/ethernet/intel/igb/igb_main.c 文件里。 loopback 设备的“驱动”代码位置:drivers/net/loopback.c。
dev_hard_start_xmit 调用实际上执行的是 loopback “驱动” 里的 loopback_xmit。为什么我把“驱动”加个引号呢,因为 loopback 是一个纯软件性质的虚拟接口,并没有真正意义上的驱动,它的工作流程大致如图。
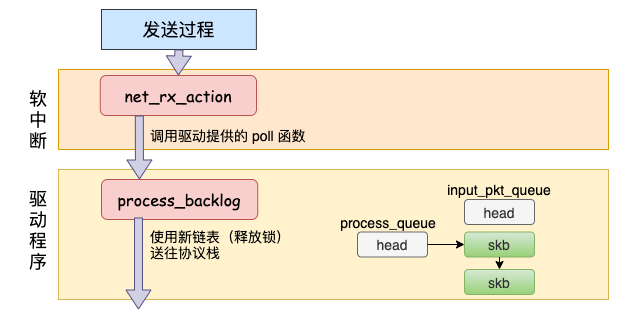
本机接收
在本机的网络 IO 过程中,由于并不真的过网卡,所以网卡实际传输,硬中断就都省去了。直接从软中断开始,经过 process_backlog 后送进协议栈,大体过程如图。
总结
总结一下本机网络 IO 的内核执行流程:
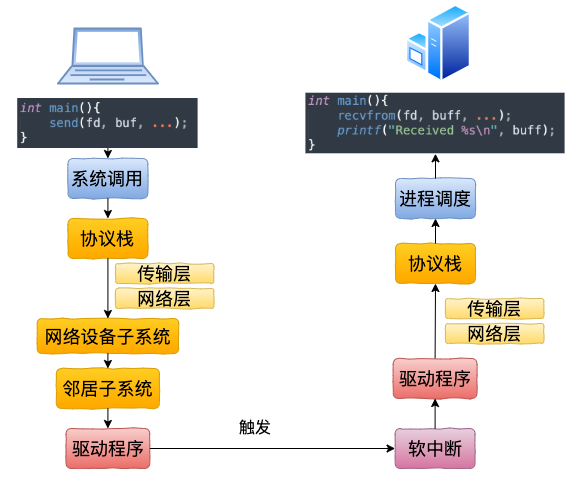
跨机网络 IO 的流程是:
本机网络 IO 和跨机 IO 比较起来,确实是节约了一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、网络设备子系统、邻居子系统整个走了一个遍。连“驱动”程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东东)。所以即使是本机网络 IO,也别误以为没啥开销。
TCP连接的深入分析
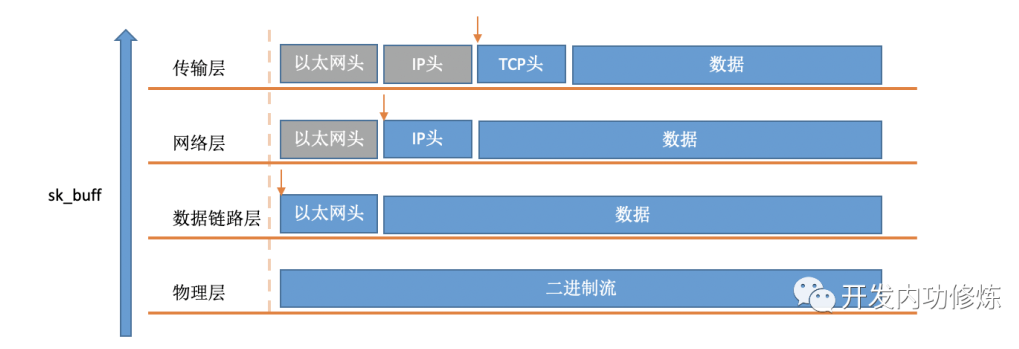
Socker buffer数据包
在软中断中,当一个包被内核从RingBuffer中摘下来的时候,在内核中是用struct sk_buff结构体来表示的(参见内核代码include/linux/skbuff.h)。其中的data成员是接收到的数据,在协议栈逐层被处理的时候,通过修改指针指向data的不同位置,来找到每一层协议关心的数据。
对于TCP协议包来说,它的Header中有一个重要的字段-flags。如下图:
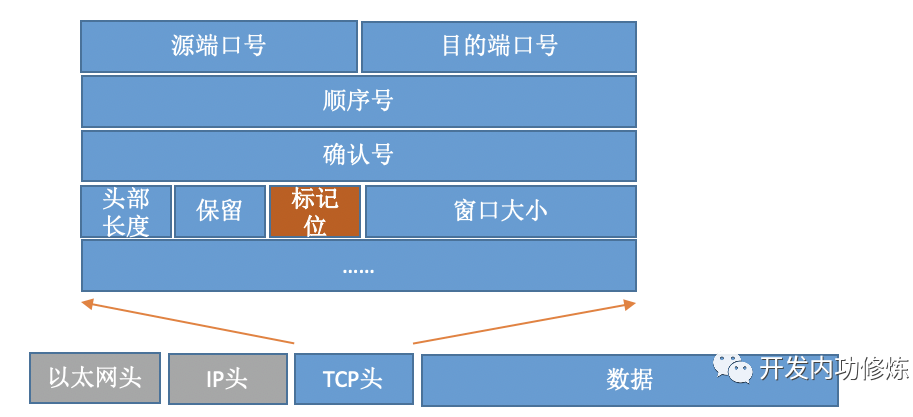
通过设置不同的标记为,将TCP包分成SYNC、FIN、ACK、RST等类型。客户端通过connect系统调用命令内核发出SYNC、ACK等包来实现和服务器TCP连接的建立。
TCP连接的耗时
TCP正常连接
在服务器端,可能会接收许许多多的连接请求,内核还需要借助一些辅助数据结构-半连接队列和全连接队列。我们来看一下整个连接过程:
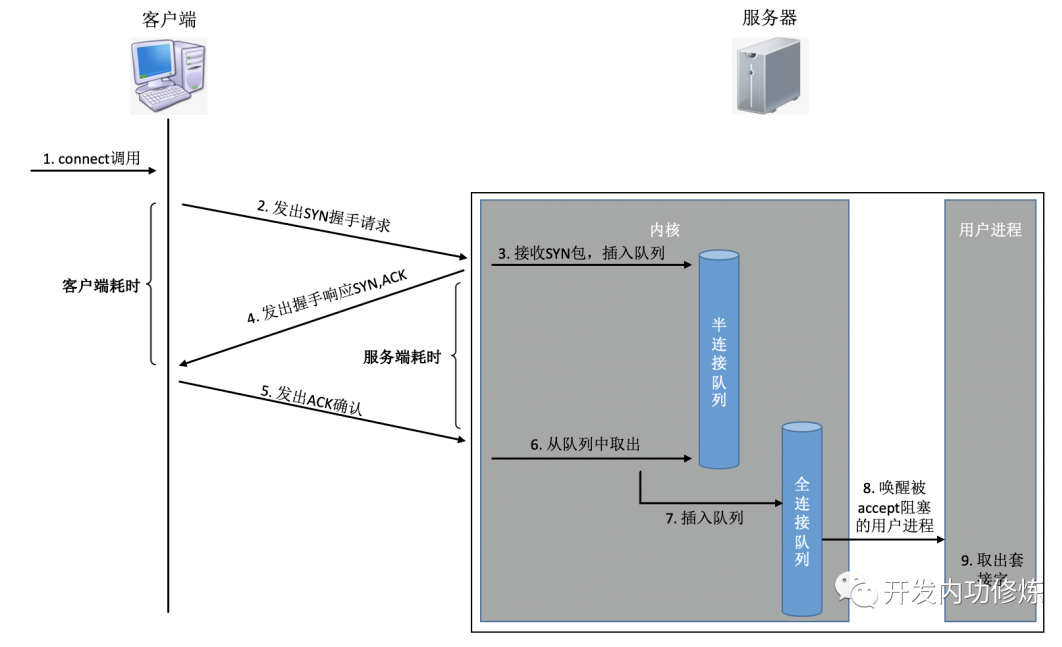
在这个连接过程中,我们来简单分析一下每一步的耗时
客户端发出SYNC包:客户端一般是通过connect系统调用来发出SYN的,这里牵涉到本机的系统调用和软中断的CPU耗时开销
SYN传到服务器:SYN从客户端网卡被发出,开始“跨过山和大海,也穿过人山人海……”,这是一次长途远距离的网络传输
服务器处理SYN包:内核通过软中断来收包,然后放到半连接队列中,然后再发出SYN/ACK响应。又是CPU耗时开销
SYC/ACK传到客户端:SYC/ACK从服务器端被发出后,同样跨过很多山、可能很多大海来到客户端。又一次长途网络跋涉
客户端处理SYN/ACK:客户端内核收包并处理SYN后,经过几us的CPU处理,接着发出ACK。同样是软中断处理开销
ACK传到服务器:和SYN包,一样,再经过几乎同样远的路,传输一遍。 又一次长途网络跋涉
服务端收到ACK:服务器端内核收到并处理ACK,然后把对应的连接从半连接队列中取出来,然后放到全连接队列中。一次软中断CPU开销
服务器端用户进程唤醒:正在被accpet系统调用阻塞的用户进程被唤醒,然后从全连接队列中取出来已经建立好的连接。一次上下文切换的CPU开销
以上几步操作,可以简单划分为两类:
- 第一类是内核消耗CPU进行接收、发送或者是处理,包括系统调用、软中断和上下文切换。它们的耗时基本都是几个us左右。
- 第二类是网络传输,当包被从一台机器上发出以后,中间要经过各式各样的网线、各种交换机路由器。所以网络传输的耗时相比本机的CPU处理,就要高的多了。根据网络远近一般在几ms~到几百ms不等。。
在正常的TCP连接的建立过程中,一般可以考虑网络延时即可。
一个RTT指的是包从一台服务器到另外一台服务器的一个来回的延迟时间。
所以从全局来看,TCP连接建立的网络耗时大约需要三次传输,再加上少许的双方CPU开销,总共大约比1.5倍RTT大一点点。
不过从客户端视角来看,只要ACK包发出了,内核就认为连接是建立成功了。所以如果在客户端打点统计TCP连接建立耗时的话,只需要两次传输耗时-既1个RTT多一点的时间。(对于服务器端视角来看同理,从SYN包收到开始算,到收到ACK,中间也是一次RTT耗时)
另外,TCP握手超时重传的时间是秒级别的!
TCP连接异常
在某些情况下,可能会导致连接时的网络传输耗时上涨、CPU处理开销增加、甚至是连接失败。
客户端connect系统调用耗时失控
客户端可用端口不是特别充足的时候,connect系统调用的CPU开销直接上涨了100多倍,每次耗时达到了2500us(微秒),达到了毫秒级别。
解决起来也非常简单,办法很多:修改内核参数net.ipv4.ip_local_port_range多预留一些端口号、改用长连接都可以。
半/全连接队列满
如果连接建立的过程中,任意一个队列满了,那么客户端发送过来的syn或者ack就会被丢弃。客户端等待很长一段时间无果后,然后会发出TCP Retransmission重传。
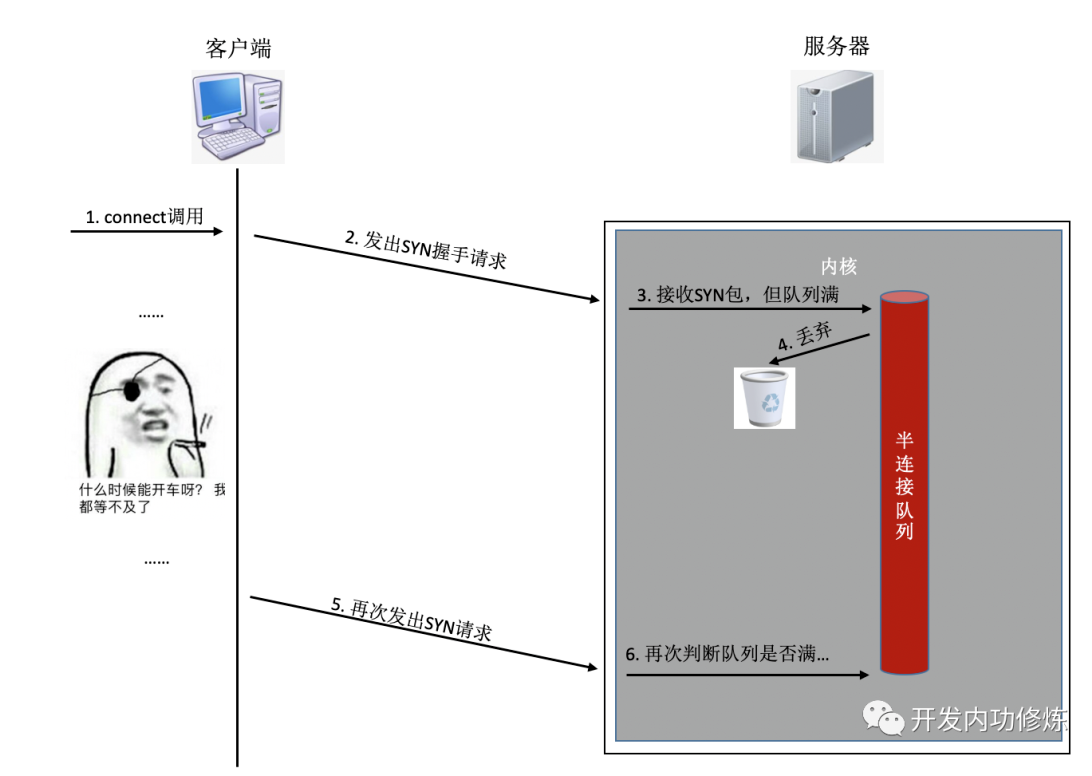
也就是说一旦server端的连接队列导致连接建立不成功,那么光建立连接就至少需要秒级以上。而正常的在同机房的情况下只是不到1毫秒的事情,整整高了1000倍左右。尤其是对于给用户提供实时服务的程序来说,用户体验将会受到较大影响。如果连重传也没有握手成功的话,很可能等不及二次重试,这个用户访问直接就超时了。
解决办法:
netstat -s可查看到当前系统半连接队列满导致的丢包统计,适当加大你的半/全连接队列的长度。- 半连接队列长度Linux内核中,主要受tcp_max_syn_backlog影响 加大它到一个合适的值就可以。
# cat /proc/sys/net/ipv4/tcp_max_syn_backlog 1024 # echo "2048" > /proc/sys/net/ipv4/tcp_max_syn_backlog- 全连接队列长度是应用程序调用listen时传入的backlog以及内核参数net.core.somaxconn二者之中较小的那个。你可能需要同时调整你的应用程序和该内核参数。
# cat /proc/sys/net/core/somaxconn 128 # echo "256" > /proc/sys/net/core/somaxconn改完之后我们可以通过ss命令输出的
Send-Q确认最终全连接生效长度:$ ss -nlt Recv-Q Send-Q Local Address:Port Address:Port 0 128 *:80 *:*
耗时测试
正常情况
首先我的客户端位于河北怀来的IDC机房内,服务器选择的是公司广东机房的某台机器。执行ping命令得到的延迟大约是37ms,使用上述脚本建立50000次连接后,得到的连接平均耗时也是37ms。
接下来我换了一台目标服务器,该服务器所在机房位于北京。离怀来有一些距离,但是和广东比起来可要近多了。这一次ping出来的RTT是1.6~1.7ms左右,在客户端统计建立50000次连接后算出每条连接耗时是1.64ms。
再做一次实验,这次选中实验的服务器和客户端直接位于同一个机房内,ping延迟在0.2ms~0.3ms左右。跑了以上脚本以后,实验结果是50000 TCP连接总共消耗了11605ms,平均每次需要0.23ms。
连接队列溢出
有少部分握手耗时**3s+**,原因是半连接队列满了导致客户端等待超时后进行了SYN的重传。
TCP三次握手深入
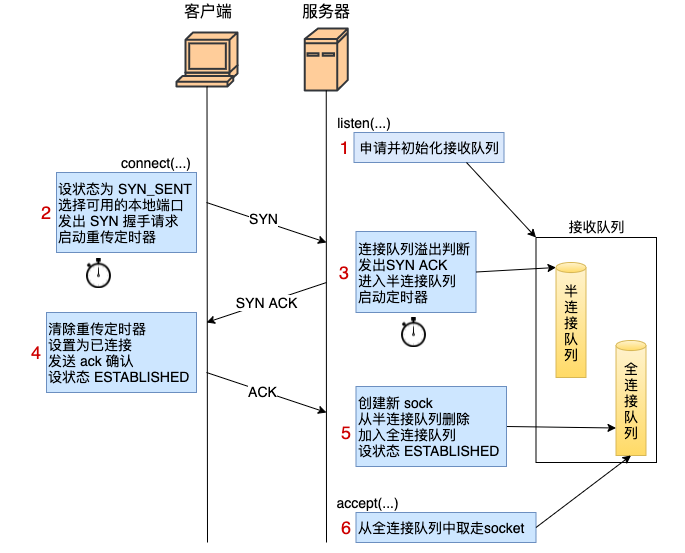
- 服务器 listen 时,计算了全/半连接队列的长度,还申请了相关内存并初始化。
- 客户端 connect 时,把本地 socket 状态设置成了 TCP_SYN_SENT,选则一个可用的端口,发出 SYN 握手请求并启动重传定时器。
- 服务器响应 ack 时,会判断下接收队列是否满了,满的话可能会丢弃该请求。否则发出 synack,申请 request_sock 添加到半连接队列中,同时启动定时器。
- 客户端响应 synack 时,清除了 connect 时设置的重传定时器,把当前 socket 状态设置为 ESTABLISHED,开启保活计时器后发出第三次握手的 ack 确认。
- 服务器响应 ack 时,把对应半连接对象删除,创建了新的 sock 后加入到全连接队列中,最后将新连接状态设置为 ESTABLISHED。
- accept 从已经建立好的全连接队列中取出一个返回给用户进程。
TCP最大连接数
TCP连接四元组是源IP地址、源端口、目的IP地址和目的端口。 任意一个元素发生了改变,那么就代表的是一条完全不同的连接了。
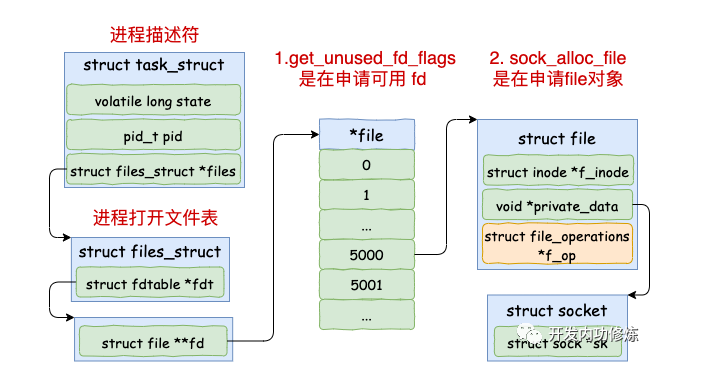
一条TCP连接,Linux都需要建立一个文件对象
Linux进程每打开一个文件(linux下一切皆文件,包括socket),都会消耗一定的内存资源。如果有不怀好心的人启动一个进程来无限的创建和打开新的文件,会让服务器崩溃。所以linux系统出于安全角度的考虑,在多个位置都限制了可打开的文件描述符的数量,包括系统级、用户级、进程级。
- 系统级:当前系统可打开的最大数量,通过fs.file-max参数可修改
- 用户级:指定用户可打开的最大数量,修改/etc/security/limits.conf
- 进程级:单个进程可打开的最大数量,通过fs.nr_open参数可修改
进程在打开文件时的内核数据结构:
缓冲区
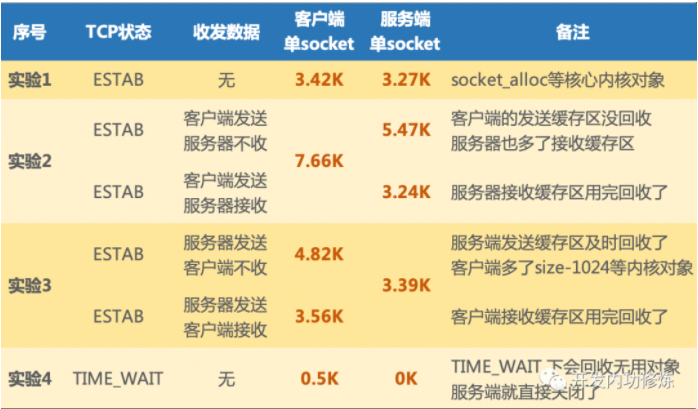
一条空TCP连接大约占内存3.3KB左右。如果有数据流动就相应配置接收缓存区和发送缓冲区。
接收缓存区大小是可以配置的,通过sysctl命令就可以查看
$ sysctl -a | grep rmem net.ipv4.tcp_rmem = 4096 87380 8388608 net.core.rmem_default = 212992 net.core.rmem_max = 8388608“其中在tcp_rmem”中的第一个值是为你们的TCP连接所需分配的最少字节数。该值默认是4K,最大的话8MB之多。也就是说你们有数据发送的时候我需要至少为对应的socket再分配4K内存,甚至可能更大。”
TCP分配发送缓存区的大小受参数net.ipv4.tcp_wmem配置影响。
$ sysctl -a | grep wmem net.ipv4.tcp_wmem = 4096 65536 8388608 net.core.wmem_default = 212992 net.core.wmem_max = 8388608“在net.ipv4.tcp_wmem”中的第一个值是发送缓存区的最小值,默认也是4K。当然了如果数据很大的话,该缓存区实际分配的也会比默认值大。”
TCP连接时的内存占用
空TCP连接的ESTABLISTH状态
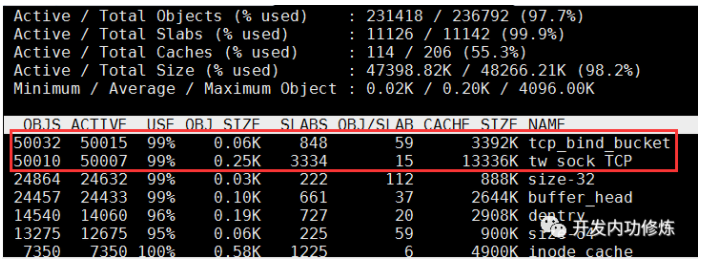
实验中,客户端的5w条连接,服务器的meminfo显示共消耗了163.8M,则一条空TCP连接消耗163.8M/50000=3.27KB左右
利用
slabtop命令,可以看到当前内核对象的情况,每个TCP连接消耗TCP、denty等5个内核对象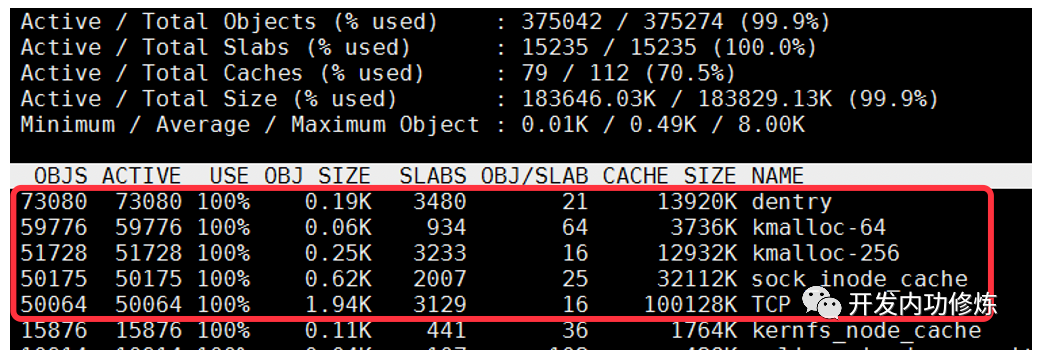
服务器接收数据的ESTABLISTH状态
客户端发送“I am client!”,测试得到每个TCP连接平均消耗5.47KB
服务器发送数据的ESTABLISTH状态
服务器发送“I am server!”,测试得到每个TCP连接平均消耗3.39KB。
和空连接没啥区别,可能是发送缓冲区占用的内存被及时回收了。
TIME_WAIT状态
此时客户端的内核对象只剩下2个,每个TCP连接平均消耗0.5KB。
总结
内核在 socket 内存开销优化上采取了不少方法:
- 内核会尽量及时回收发送缓存区、接收缓存区,但高版本做的更好
- 发送接收缓存区最小并一定不是 rmem 内核参数里的最小值,实际可能会更小
- 其它状态下,例如对于TIME_WAIT还会回收非必要的 socket_alloc 等对象
TCP客户端的端口号的确定
socket没有bind端口时
客户端机上调用 connect 函数
tcp_v4_connect 中调用选择端口的函数,那就是 inet_hash_connect。
int inet_hash_connect(struct inet_timewait_death_row *death_row, struct sock *sk) { return __inet_hash_connect(death_row, sk, inet_sk_port_offset(sk), __inet_check_established, __inet_hash_nolisten); }两个重要参数。
- inet_sk_port_offset(sk):这个函数是根据要连接的目的 IP 和端口等信息生成一个随机数。
- __inet_check_established:检查是否和现有 ESTABLISH 的连接是否冲突的时候用的函数
选择可用端口
接着调用 inet_get_local_port_range,这个函数读取的是 net.ipv4.ip_local_port_range 这个内核参数。来读取管理员配置的可用的端口范围。
该参数的默认值是 32768 61000,意味着端口总可用的数量是 61000 - 32768 = 28232 个。如果你觉得这个数字不够用,那就修改你的 net.ipv4.ip_local_port_range 内核参数。
接下来进入到了 for 循环中。其中offset 是我们前面说的,通过 inet_sk_port_offset(sk) 计算出的随机数。那这段循环的作用就是从某个随机数开始,把整个可用端口范围来遍历一遍。直到找到可用的端口后停止。
int __inet_hash_connect(...) { for (i = 1; i <= remaining; i++) { port = low + (i + offset) % remaining; //查看是否是保留端口,是则跳过 if (inet_is_reserved_local_port(port)) continue; // 查找和遍历已经使用的端口的哈希链表 head = &hinfo->bhash[inet_bhashfn(net, port, hinfo->bhash_size)]; inet_bind_bucket_for_each(tb, &head->chain) { //如果端口已经被使用 if (net_eq(ib_net(tb), net) && tb->port == port) { //通过 check_established 继续检查是否可用 if (!check_established(death_row, sk, port, &tw)) goto ok; } } //未使用的话,直接 ok goto ok; } return -EADDRNOTAVAIL; ok: ... }如果你因为某种原因不希望某些端口被内核使用,那么就把它们写到 ip_local_reserved_ports 这个内核参数中就行了。
整个系统中会维护一个所有使用过的端口的哈希表,它就是 hinfo->bhash。接下来的代码就会在这里进行查找。如果在哈希表中没有找到,那么说明这个端口是可用的。至此端口就算是找到了。
发起syn请求
socket有bind端口时
不只是服务器端,哪怕是对于客户端,也可以对 socket 使用 bind 来绑定 IP 或者端口。如果使用了 bind,那么在 bind 的时候就会确定好端口,并设置到connect调用过程中的 inet_num 变量中。
一般非常不推荐在客户端角色下使用 bind。因为这会打乱 connect 里的端口选择过程。
首先尝试使用该端口号,如果传入了 0 ,也会自动选择一个。但默认情况下一个端口只会被使用一次。(非bind情况下,一个端口是可以被用于多条 TCP 连接的)
TCP服务端的端口监听
前面所述TCP的连接基本都是站在客户端角度,服务端在进行TCP连接监听时一般如下:
int fd = socket(AF_INET, SOCK_STREAM, 0);
bind(fd, ...);
listen(fd, 128);
accept(fd, ...);其中Listen就是一直监听端口的状态,有没有连接建立,有没有数据传输。
在TCP连接中,listen 最主要的工作就是申请和初始化接收队列,包括全连接队列和半连接队列。其中全连接队列是一个链表,而半连接队列由于需要快速的查找,所以使用的是一个哈希表(其实半连接队列更准确的的叫法应该叫半连接哈希表)。
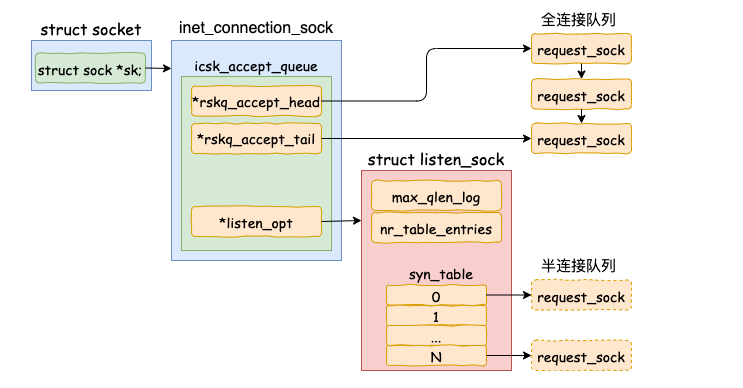
内核是如何确定全/半连接队列的长度的:
1. 全连接队列的长度
对于全连接队列来说,其最大长度是 listen 时传入的 backlog 和 net.core.somaxconn 之间较小的那个值。如果需要加大全连接队列长度,那么就是调整 backlog 和 somaxconn。
2. 半连接队列的长度
在 listen 的过程中,内核我们也看到了对于半连接队列来说,其最大长度是 min(backlog, somaxconn, tcp_max_syn_backlog) + 1 再上取整到 2 的幂次,但最小不能小于16。如果需要加大半连接队列长度,那么需要一并考虑 backlog,somaxconn 和 tcp_max_syn_backlog 这三个参数。网上任何告诉你修改某一个参数就能提高半连接队列长度的文章都是错的。
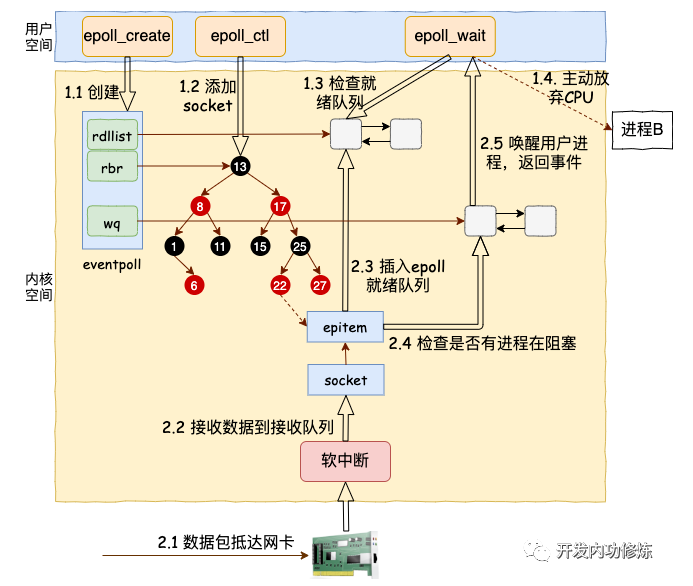
IO多路复用
在 Linux 上多路复用方案有 select、poll、epoll。它们三个中 epoll 的性能表现是最优秀的,能支持的并发量也最大。所以我们今天把 epoll 作为要拆解的对象,深入揭秘内核是如何实现多路的 IO 管理的。
demo代码
int main(){
listen(lfd, ...);
cfd1 = accept(...);
cfd2 = accept(...);
efd = epoll_create(...);
epoll_ctl(efd, EPOLL_CTL_ADD, cfd1, ...);
epoll_ctl(efd, EPOLL_CTL_ADD, cfd2, ...);
epoll_wait(efd, ...)
}其中和 epoll 相关的函数是如下三个:
- epoll_create:创建一个 epoll 对象
- epoll_ctl:向 epoll 对象中添加要管理的连接
- epoll_wait:等待其管理的连接上的 IO 事件
accept创建socket
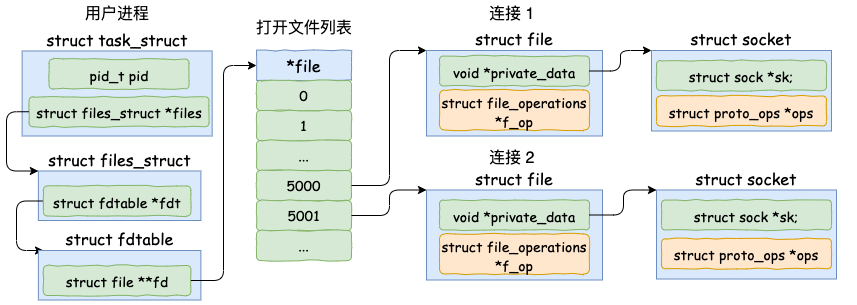
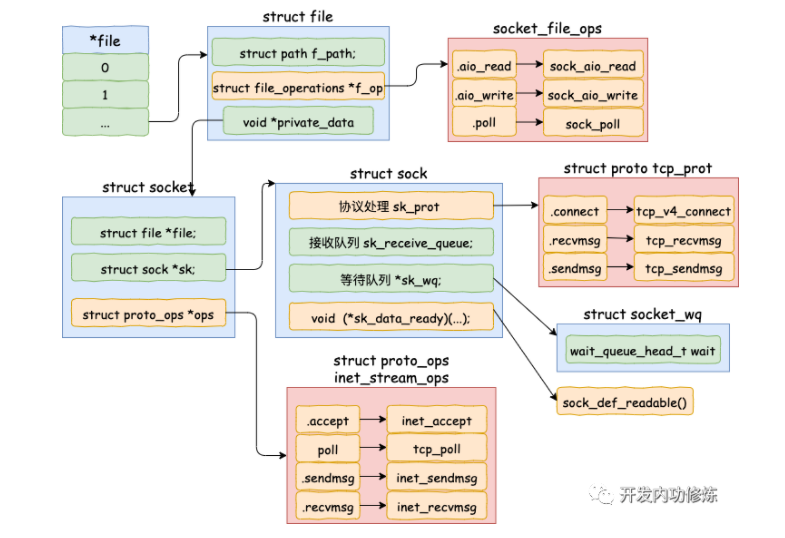
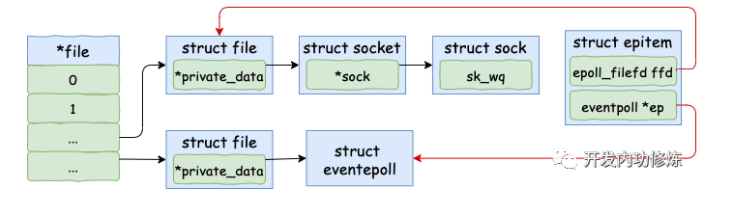
当 accept 之后,进程会创建一个新的 socket 出来,专门用于和对应的客户端通信,然后把它放到当前进程的打开文件列表中。其中一条连接的 socket 内核对象更为具体一点的结构图如下:
accept的内核源码如下:
//file: net/socket.c
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
//根据 fd 查找到监听的 socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
//1.1 申请并初始化新的 socket
newsock = sock_alloc();
newsock->type = sock->type;
newsock->ops = sock->ops;
//1.2 申请新的 file 对象,并设置到新 socket 上
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
......
//1.3 接收连接
err = sock->ops->accept(sock, newsock, sock->file->f_flags);
//1.4 添加新文件到当前进程的打开文件列表
fd_install(newfd, newfile);初始化struct socket对象
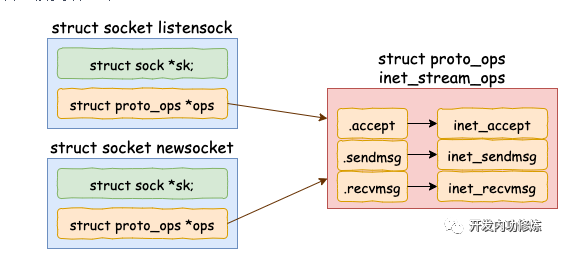
调用 sock_alloc 申请一个 struct socket 对象出来。然后接着把 listen 状态的 socket 对象上的协议操作函数集合 ops 赋值给新的 socket。
为新 socket 对象申请 file
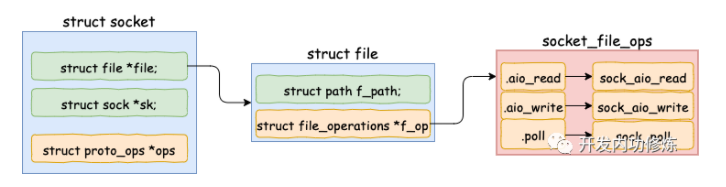
struct socket 对象中有一个重要的成员 – file 内核对象指针。这个指针初始化的时候是空的。在 accept 方法里会调用 sock_alloc_file 来申请内存并初始化。然后将新 file 对象设置到 sock->file 上。
接收连接sock
在 socket 内核对象中除了 file 对象指针以外,有一个核心成员 sock。accept方法中的sock->ops->accept 对应的方法是 inet_accept。它执行的时候会从握手队列里直接获取创建好的 sock。
//file: include/linux/net.h
struct socket {
struct file *file;
struct sock *sk;
}这个 struct sock 数据结构非常大,是 socket 的核心内核对象。发送队列、接收队列、等待队列等核心数据结构都位于此。
添加新文件到当前进程的打开文件列表中
//file: fs/file.c
void fd_install(unsigned int fd, struct file *file)
{
__fd_install(current->files, fd, file);
}
void __fd_install(struct files_struct *files, unsigned int fd,
struct file *file)
{
...
fdt = files_fdtable(files);
BUG_ON(fdt->fd[fd] != NULL);
rcu_assign_pointer(fdt->fd[fd], file);
}创建一个 epoll 对象
在用户进程调用 epoll_create 时,内核会创建一个 struct eventpoll 的内核对象。并同样把它关联到当前进程的已打开文件列表中。
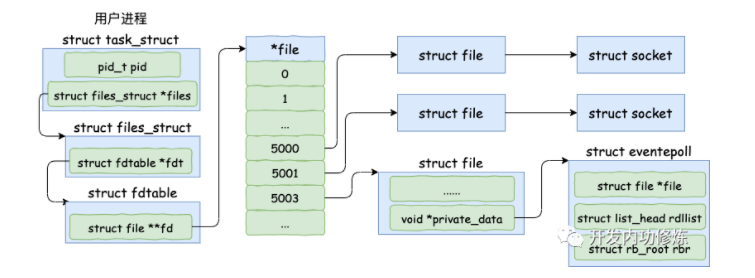
struct eventpoll 对象,更详细的结构如下:
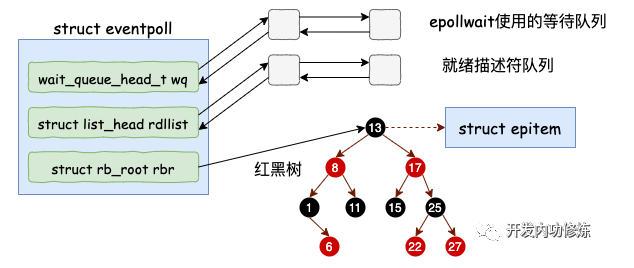
struct eventpoll的内核源码:
// file:fs/eventpoll.c
struct eventpoll {
//sys_epoll_wait用到的等待队列
wait_queue_head_t wq;
//接收就绪的描述符都会放到这里
struct list_head rdllist;
//每个epoll对象中都有一颗红黑树
struct rb_root rbr;
......
}- wq: 等待队列链表。软中断数据就绪的时候会通过 wq 来找到阻塞在 epoll 对象上的用户进程。
- rbr: 一棵红黑树。为了支持对海量连接的高效查找、插入和删除,eventpoll 内部使用了一棵红黑树。通过这棵树来管理用户进程下添加进来的所有 socket 连接。
- rdllist: 就绪的描述符的链表。当有的连接就绪的时候,内核会把就绪的连接放到 rdllist 链表里。这样应用进程只需要判断链表就能找出就绪进程,而不用去遍历整棵树。
添加 socket到epoll对象
在使用 epoll_ctl 注册每一个 socket 的时候,内核会做如下三件事情
- 1.分配一个红黑树节点对象 epitem,
- 2.添加等待事件到 socket 的等待队列中,其回调函数是 ep_poll_callback
- 3.将 epitem 插入到 epoll 对象的红黑树里
通过 epoll_ctl 添加两个 socket 以后,这些内核数据结构最终在进程中的关系图大致如下:
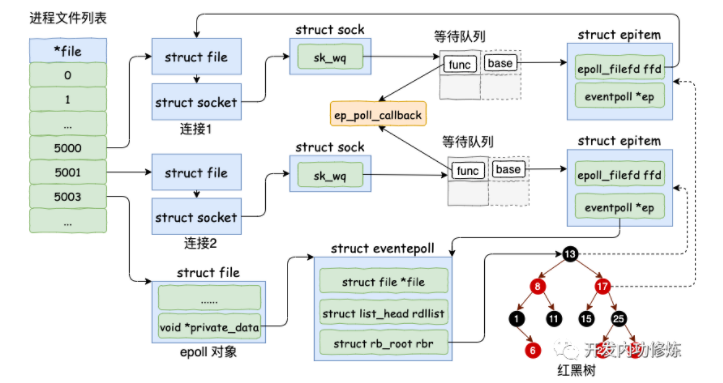
在 epoll_ctl 中首先根据传入 fd 找到 eventpoll、socket相关的内核对象 ,然后执行到 ep_insert 函数。所有的注册都是在这个函数中完成的。
//file: fs/eventpoll.c
static int ep_insert(struct eventpoll *ep,
struct epoll_event *event,
struct file *tfile, int fd)
{
//3.1 分配并初始化 epitem
//分配一个epi对象
struct epitem *epi;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
//对分配的epi进行初始化
//epi->ffd中存了句柄号和struct file对象地址
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
//3.2 设置 socket 等待队列
//定义并初始化 ep_pqueue 对象
struct ep_pqueue epq;
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
//调用 ep_ptable_queue_proc 注册回调函数
//实际注入的函数为 ep_poll_callback
revents = ep_item_poll(epi, &epq.pt);
......
//3.3 将epi插入到 eventpoll 对象中的红黑树中
ep_rbtree_insert(ep, epi);
......
}分配并初始化 epitem
对于每一个 socket,调用 epoll_ctl 的时候,都会为之分配一个 epitem
struct epitem {
//红黑树节点
struct rb_node rbn;
//socket文件描述符信息
struct epoll_filefd ffd;
//所归属的 eventpoll 对象
struct eventpoll *ep;
//等待队列
struct list_head pwqlist;
}将ep 指针指向 eventpoll 对象。另外用要添加的 socket 的 file、fd 来填充 epitem->ffd。
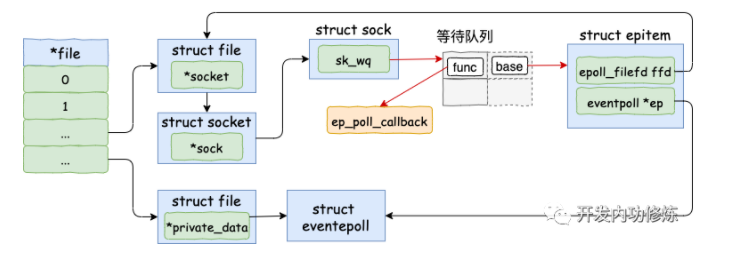
设置 socket 等待队列
在创建 epitem 并初始化之后,ep_insert 中第二件事情就是设置 socket 对象上(在sock对象中)的等待任务队列。并把函数 fs/eventpoll.c 文件下的 ep_poll_callback 设置为数据就绪时候的回调函数(软中断将数据收到 socket 的接收队列后,会通过注册的这个 ep_poll_callback 函数来回调,进而通知到 epoll 对象)。
插入红黑树
分配完 epitem 对象后,紧接着并把它插入到红黑树中。
epoll等待接收数据
当epoll_wait函数被调用时它观察 eventpoll->rdllist 链表里有没有数据即可。有数据就返回,没有数据就创建一个等待队列项(关联了当前进程current),将其添加到 eventpoll 的等待队列上,然后把自己阻塞掉就完事。
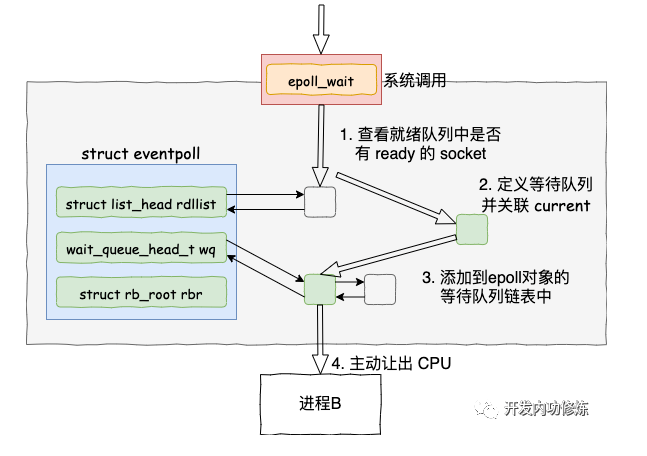
注意:epoll_ctl 添加 socket 时也创建了等待队列项。不同的是这里的等待队列项是挂在 epoll 对象上的,而前者是挂在 socket 对象上的。
接收数据
软中断在数据处理完之后依次进入各个回调函数,最后通知到用户进程。
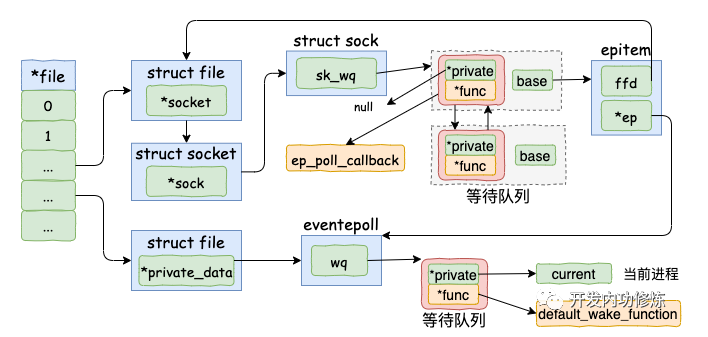
接收数据到任务队列
tcp 协议栈处理网络帧时,首先根据收到的网络包的 header 里的 source 和 dest 信息来在本机上查询对应的 socket。
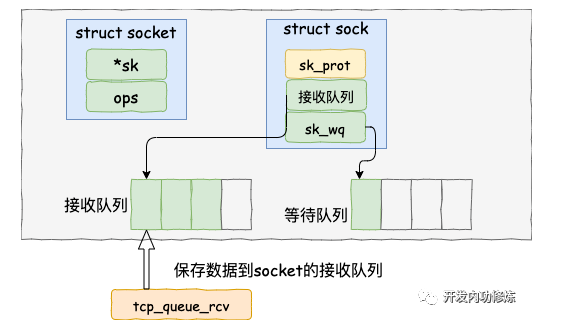
进过一系列的处理,最后通过tcp_queue_rcv 函数中完成了将接收数据放到 socket (在其sock对象中)的接收队列,同时当前用户进程current放入socket的等待队列。
查找就绪回调函数
调用 tcp_queue_rcv 接收完成之后,接着再调用 sk_data_ready 来唤醒在 socket上等待的用户进程。当 socket 上数据就绪时候,内核将以 sk_data_ready (被设置为了sock_def_readable) 这个函数为入口,找到 epoll_ctl 添加 socket 时在其上设置的回调函数 ep_poll_callback。
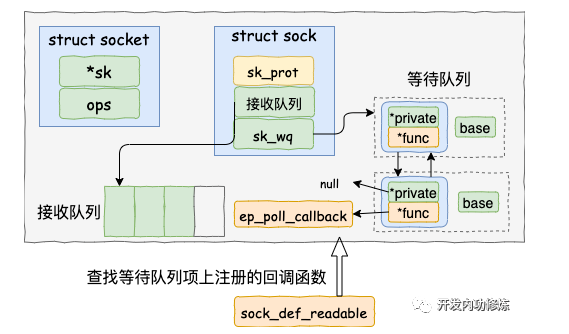
执行 socket 就绪回调函数
等待任务队列项上的额外的 base 指针可以找到 epitem, 进而也可以找到 eventpoll对象。
首先它做的第一件事就是把自己的 epitem 添加到 epoll 的就绪队列中。
接着它又会查看 eventpoll 对象上的等待队列里是否有等待项(epoll_wait 执行的时候会设置)。
如果没有,执行软中断的事情就做完了。如果有等待项,那就查找到等待项里设置的回调函数。
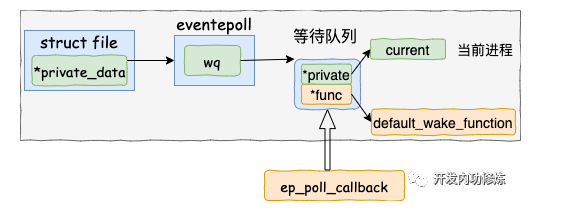
执行 epoll 就绪通知
在default_wake_function 中找到等待队列项里的进程描述符,然后唤醒之。
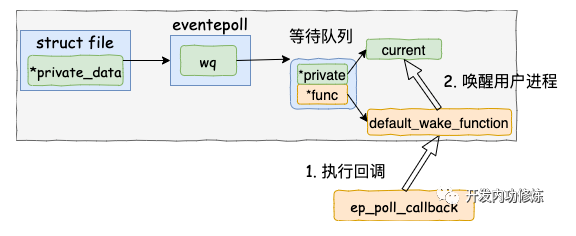
将epoll_wait进程推入可运行队列,等待内核重新调度进程。然后epoll_wait对应的这个进程重新运行后,就从 schedule 恢复
当进程醒来后,继续从 epoll_wait 时暂停的代码继续执行。把 rdlist 中就绪的事件返回给用户进程
//file: fs/eventpoll.c
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
......
__remove_wait_queue(&ep->wq, &wait);
set_current_state(TASK_RUNNING);
}
check_events:
//返回就绪事件给用户进程
ep_send_events(ep, events, maxevents))总结epoll模型
tcpdump内核抓包的实现
tcpdump是如何工作的
用户态 tcpdump 命令是通过 socket 系统调用,在内核源码中用到的 ptype_all 中挂载了函数钩子上去。无论是在网络包接收过程中,还是在发送过程中,都会在网络设备层遍历 ptype_all 中的协议,并执行其中的回调。tcpdump 命令就是基于这个底层原理来工作的。
netfilter 过滤的包 tcpdump是否可以抓的到
关于这个问题,得分接收和发送过程分别来看。在网络包接收的过程中,由于 tcpdump 近水楼台先得月,所以完全可以捕获到命中 netfilter 过滤规则的包。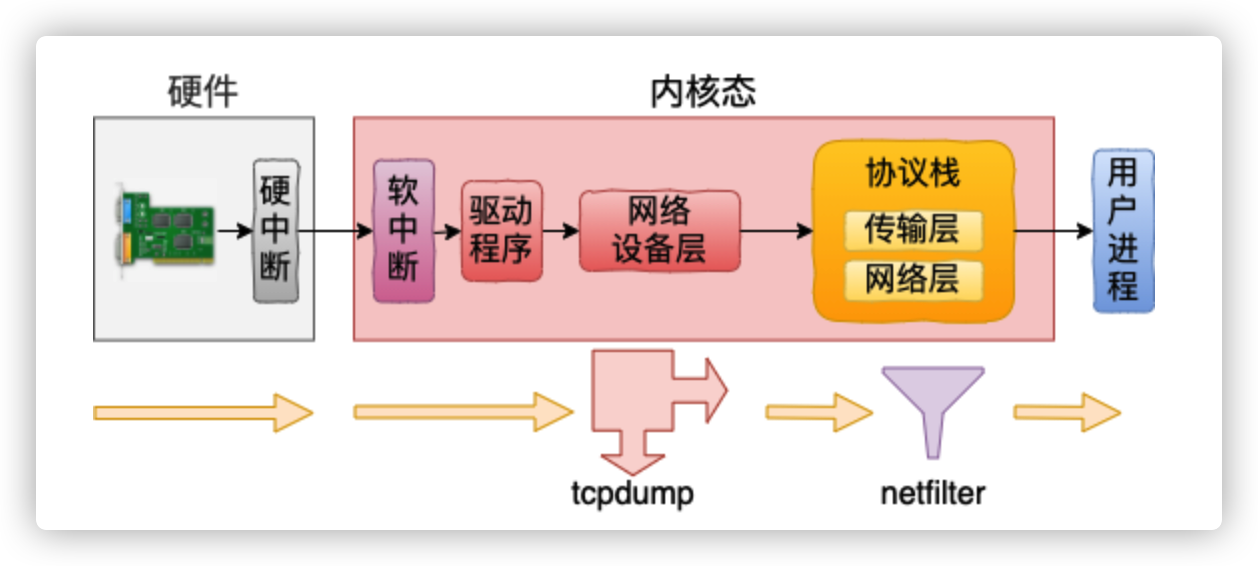
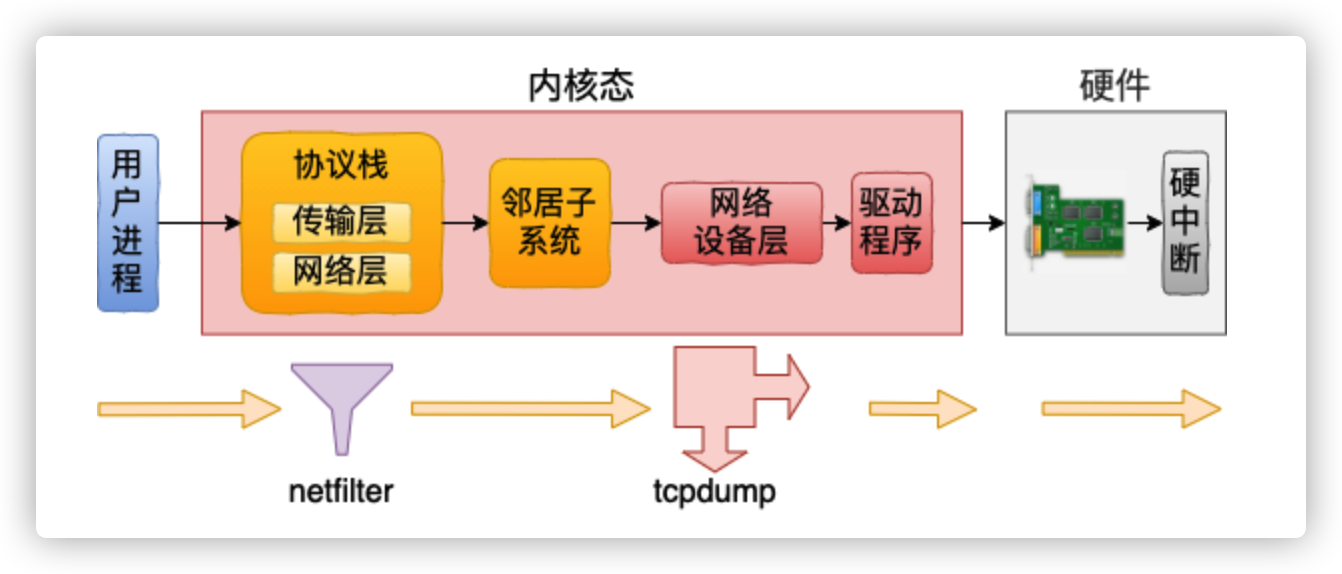
但是在发送的过程中,恰恰相反。网络包先经过协议层,这时候被 netfilter 过滤掉的话,底层工作的 tcpdump 还没等看见就啥也没了。
Linux网络虚拟化
veth
网络虚拟化实现的第一步,就是用软件来模拟这个简单的网络连接实现过程。
veth,它模拟了在物理世界里的两块网卡,以及一条网线。通过它可以将两个虚拟的设备连接起来,让他们之间相互通信。平时工作中在 Docker 镜像里我们看到的 eth0 设备,其实就是 veth。
我们本机网络 IO 里的 lo 回环设备也是这样一个用软件虚拟出来设备。Veth 和 lo 的一点区别就是 veth 总是成双成对地出现。
创建
- 在 Linux 下,我们可以通过使用 ip 命令创建一对儿 veth。其中 link 表示 link layer的意思,即链路层。这个命令可以用于管理和查看网络接口,包括物理网络接口,也包括虚拟接口。
# ip link add veth0 type veth peer name veth1- 使用 ip link show 来进行查看。
# ip link add veth0 type veth peer name veth1
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT qlen 1000
link/ether 6c:0b:84:d5:88:d1 brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 6c:0b:84:d5:88:d2 brd ff:ff:ff:ff:ff:ff
4: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 4e:ac:33:e5:eb:16 brd ff:ff:ff:ff:ff:ff
5: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 2a:6d:65:74:30:fb brd ff:ff:ff:ff:ff:ff- 和 eth0、lo 等网络设备一样,veth 也需要为其配置上 ip 后才能够正常工作。我们为这对儿 veth 分别来配置上 IP。
# ip addr add 192.168.1.1/24 dev veth0
# ip addr add 192.168.1.2/24 dev veth1- 接下来,我们把这两个设备启动起来。
# ip link set veth0 up
# ip link set veth1 up- 当设备启动起来以后,我们通过我们熟悉的 ifconfig 就可以查看到它们了。
# ifconfig
eth0: ......
lo: ......
veth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.1 netmask 255.255.255.0 broadcast 0.0.0.0
......
veth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.2 netmask 255.255.255.0 broadcast 0.0.0.0
......网络传输配置
首先要关闭反向过滤 rp_filter,该模块会检查 IP 包是否符合要求,否则可能会过滤掉。
然后再打开 accept_local,接收本机 IP 数据包。详细准备过程如下:
# echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
# echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter
# echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter
# echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local
# echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local测试通信
好了,我们在 veth0 上来 ping 一下 veth1。这两个 veth 之间可以通信了,欧耶!
# ping 192.168.1.2 -I veth0
PING 192.168.1.2 (192.168.1.2) from 192.168.1.1 veth0: 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.019 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.010 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.010 ms
...我在另外一个控制台上,还启动了 tcpdump 抓包,抓到的结果如下。
# tcpdump -i veth0
09:59:39.449247 ARP, Request who-has *** tell ***, length 28
09:59:39.449259 ARP, Reply *** is-at 4e:ac:33:e5:eb:16 (oui Unknown), length 28
09:59:39.449262 IP *** > ***: ICMP echo request, id 15841, seq 1, length 64
09:59:40.448689 IP *** > ***: ICMP echo request, id 15841, seq 2, length 64
09:59:41.448684 IP *** > ***: ICMP echo request, id 15841, seq 3, length 64
09:59:42.448687 IP *** > ***: ICMP echo request, id 15841, seq 4, length 64
09:59:43.448686 IP *** > ***: ICMP echo request, id 15841, seq 5, length 64由于两个设备之间是首次通信的,所以 veth0 首先先发出了一个 arp request,veth1 收到后回复了一个 arp reply。然后接下来就是正常的 ping 命令下的 IP 包了。
veth的数据包处理
基于 veth 的网络 IO 过程和 lo 设备几乎一样,所不同的就是使用的驱动程序不一样。
对于回环设备 lo 来说 netdev_ops 是 loopback_ops。那么 ops->ndo_start_xmit 对应的就是 loopback_xmit。
对于 veth 设备来说,它在启动的时候将 netdev_ops 设置成了 veth_netdev_ops。那 ops->ndo_start_xmit 对应的具体发送函数就是 veth_xmit。这就是在整个发送的过程中,唯一和 lo 设备不同的地方所在。
交换机Bridge的实现
在物理机的网络环境中,多台不同的物理机之间是如何连接一起互相通信的呢?没错,那就是以太网交换机。同一网络内的多台物理机通过交换机连在一起,然后它们就可以相互通信了。
在我们的网络虚拟化环境里,和物理网络中的交换机一样,也需要这样的一个软件实现的设备。它需要有很多个虚拟端口,能把更多的虚拟网卡连接在一起,通过自己的转发功能让这些虚拟网卡之间可以通信。在 Linux 下这个软件实现交换机的技术就叫做 bridge(再强调下,这是纯软件实现的)。
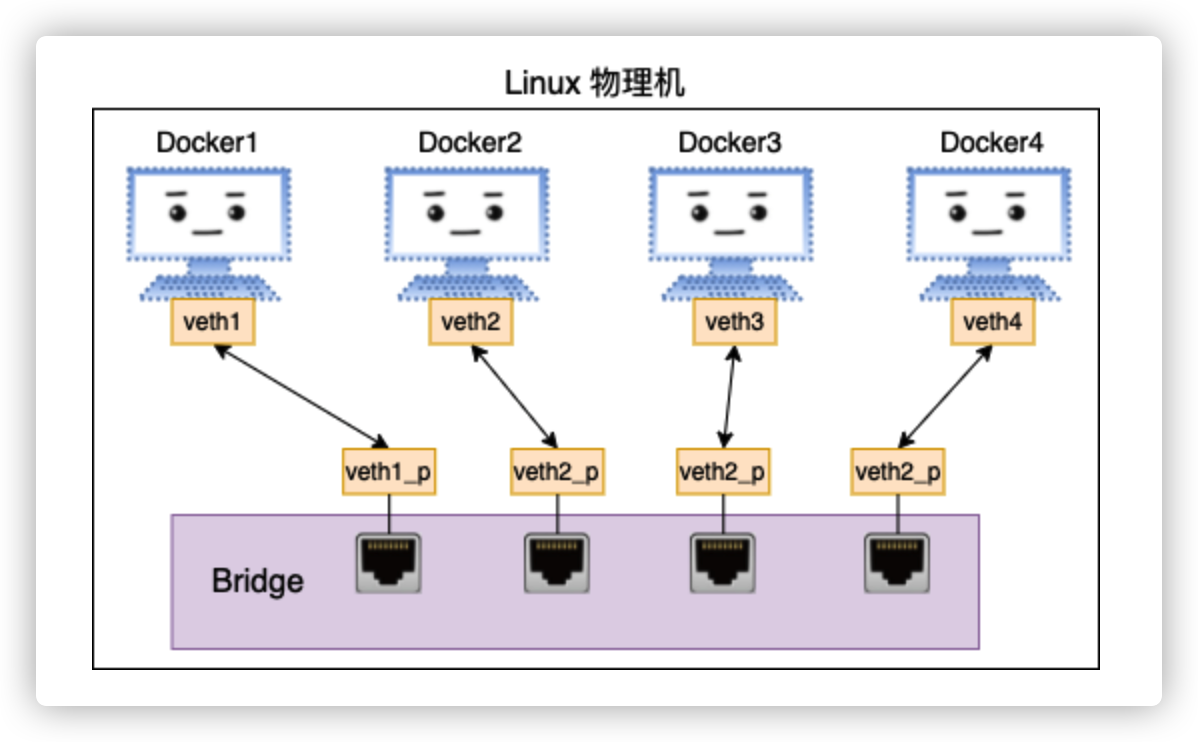
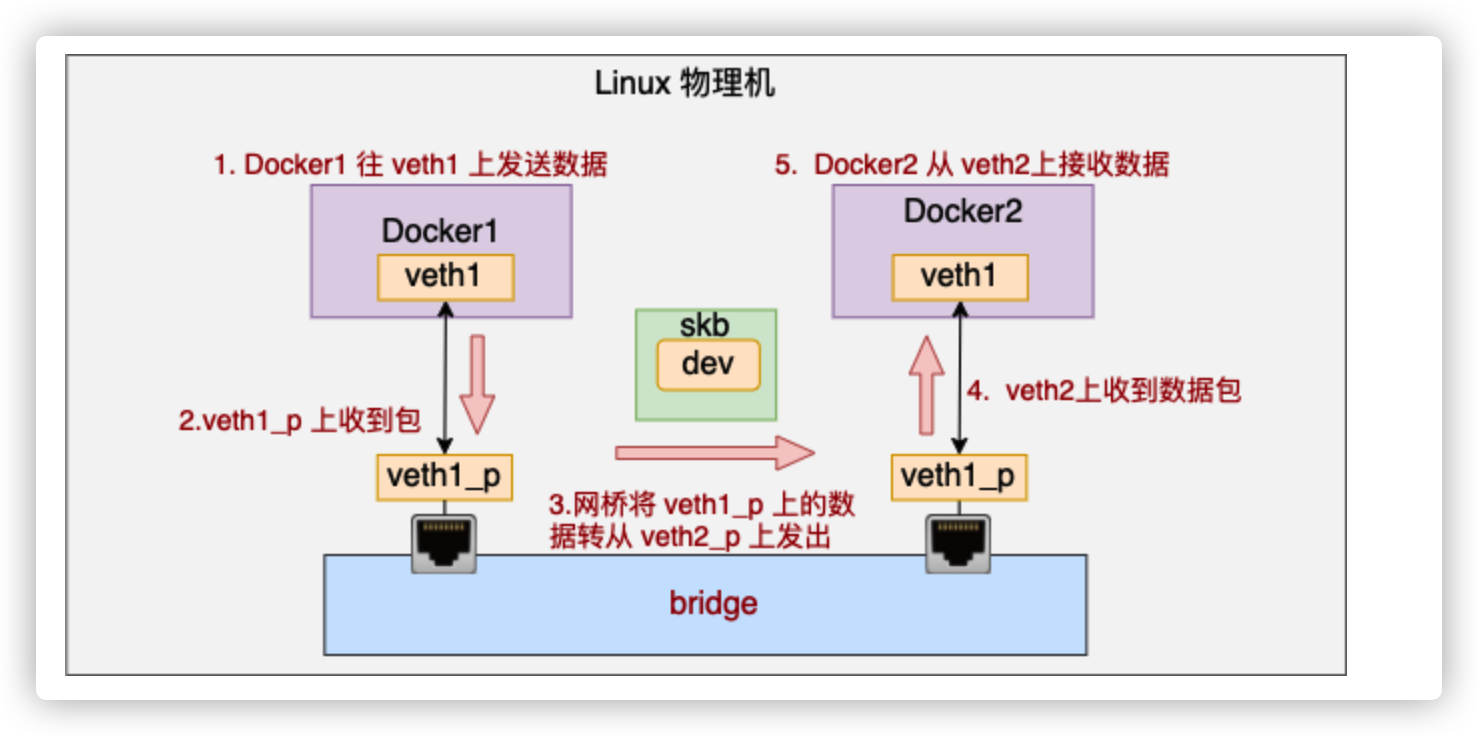
各个 Docker 容器都通过 veth 连接到 bridge 上,bridge 负责在不同的“端口”之间转发数据包。这样各个 Docker 之间就可以互相通信了!
实现
创建两个不同的网络空间
Bridge 是用来连接两个不同的虚拟网络的,所以在准备实验 bridge 之前我们得先需要用 net namespace 构建出两个不同的网络空间来。
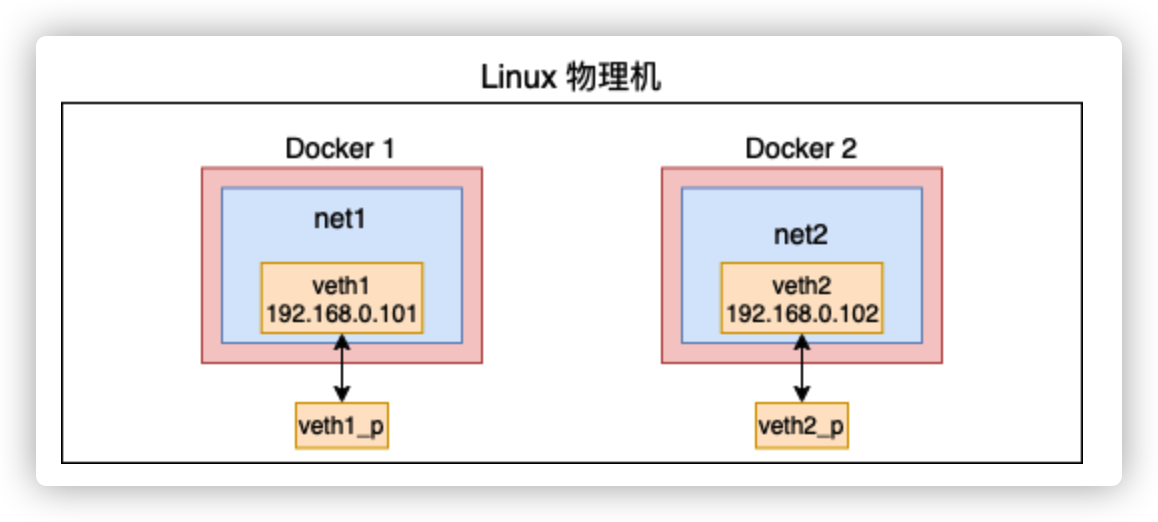
- ip netns 命令创建 net namespace
# ip netns add net1创建一对儿 veth 出来,设备名分别是 veth1 和 veth1_p。并把其中的一头 veth1 放到这个新的 netns 中
# ip link add veth1 type veth peer name veth1_p # ip link set veth1 netns net1需要用这个 veth1 来通信,所以需要为其配置上 ip,并把它启动起来
# ip netns exec net1 ip addr add 192.168.0.101/24 dev veth1 # ip netns exec net1 ip link set veth1 up验证配置是否成功
# ip netns exec net1 ip link list # ip netns exec net1 ifconfig
相同步骤,创建第二个网络空间net2
把两个网络空间连接到一起
这个时候这两个环境之间还不能互相通信。我们需要创建一个虚拟交换机 - bridge, 来把这两个网络环境连起来。
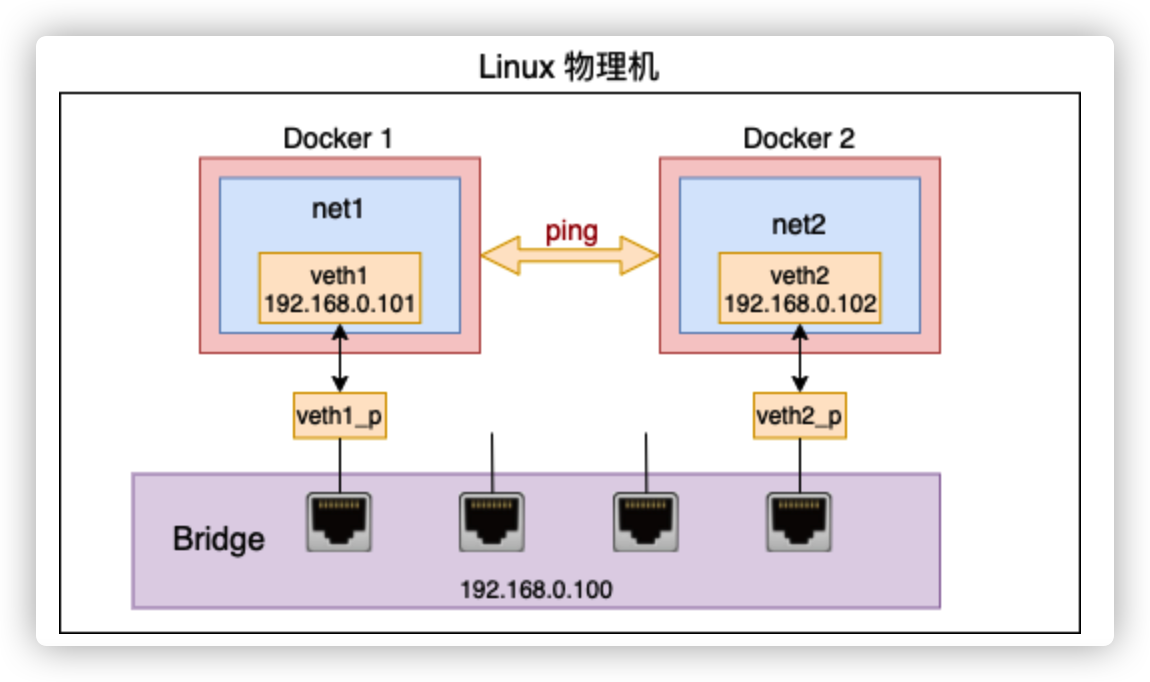
创建一个 bridge 设备, 把刚刚创建的两对儿 veth 中剩下的两头“插”到 bridge 上来
# brctl addbr br0 # ip link set dev veth1_p master br0 # ip link set dev veth2_p master br0 # ip addr add 192.168.0.100/24 dev br0为 bridge 配置上 IP,并把 bridge 以及插在其上的 veth 启动起来
# ip link set veth1_p up # ip link set veth2_p up # ip link set br0 up查看一下当前 bridge 的状态,验证是否创建成功
# brctl show bridge name bridge id STP enabled interfaces br0 8000.4e931ecf02b1 no veth1_p veth2_p
网络连接测试
在 net1 里(通过指定 ip netns exec net1 以及 -I veth1),ping 一下 net2 里的 IP(192.168.0.102)试试。
# ip netns exec net1 ping 192.168.0.102 -I veth1 PING 192.168.0.102 (192.168.0.102) from 192.168.0.101 veth1: 56(84) bytes of data. 64 bytes from 192.168.0.102: icmp_seq=1 ttl=64 time=0.037 ms 64 bytes from 192.168.0.102: icmp_seq=2 ttl=64 time=0.008 ms 64 bytes from 192.168.0.102: icmp_seq=3 ttl=64 time=0.005 ms这就是 Docker 中网络系统工作的基本原理。
内核结构
在内核中,bridge 是由两个相邻存储的内核对象来表示的。
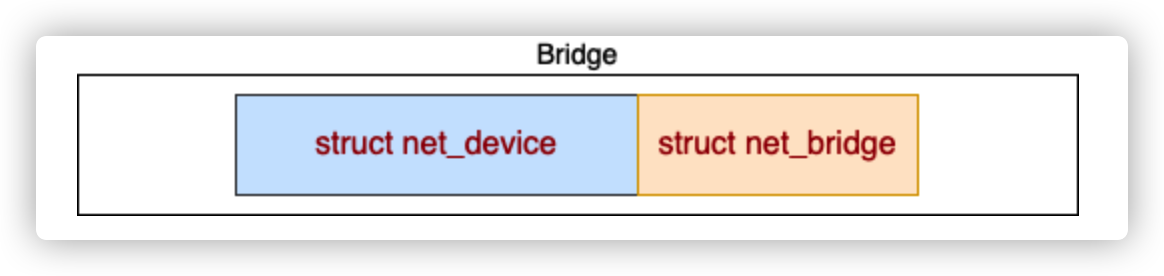
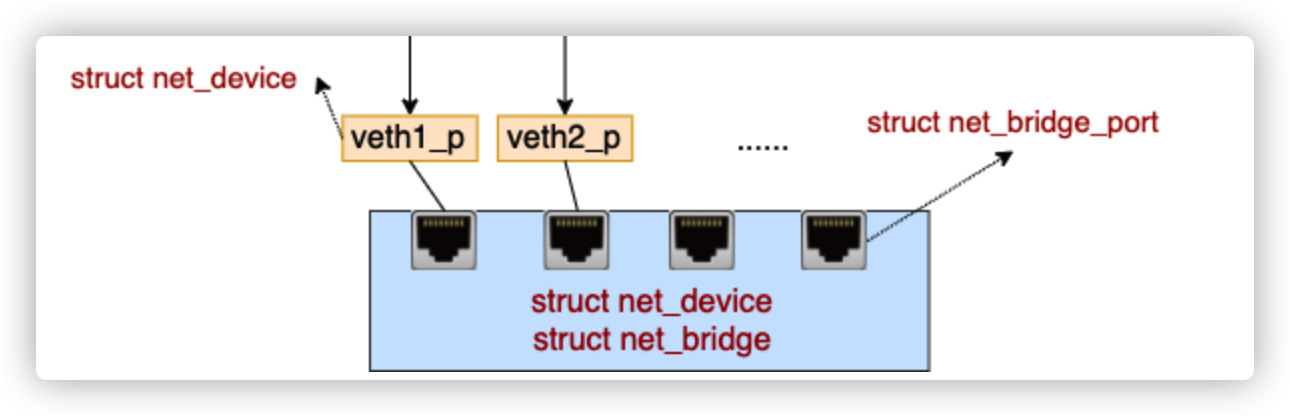
数据包处理过程
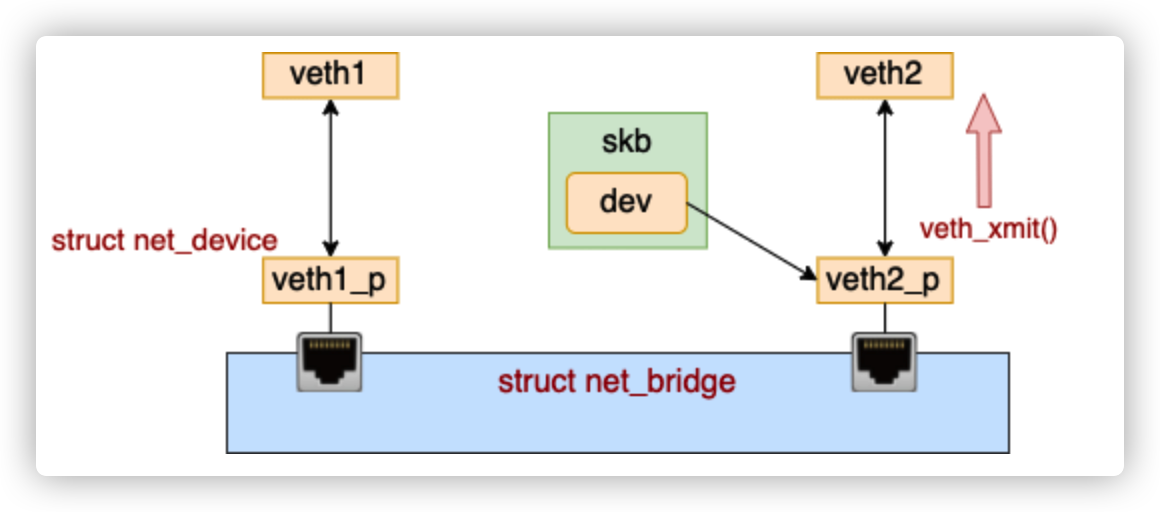
连接到了网桥上的话,在设备层的 __netif_receive_skb_core 函数中和物理机过程有所不同。
连在 bridge 上的 veth 在收到数据包的时候,不会进入协议栈,而是会进入网桥处理。网桥找到合适的转发口(另一个 veth),通过这个 veth 把数据转发出去。工作流程如下图。
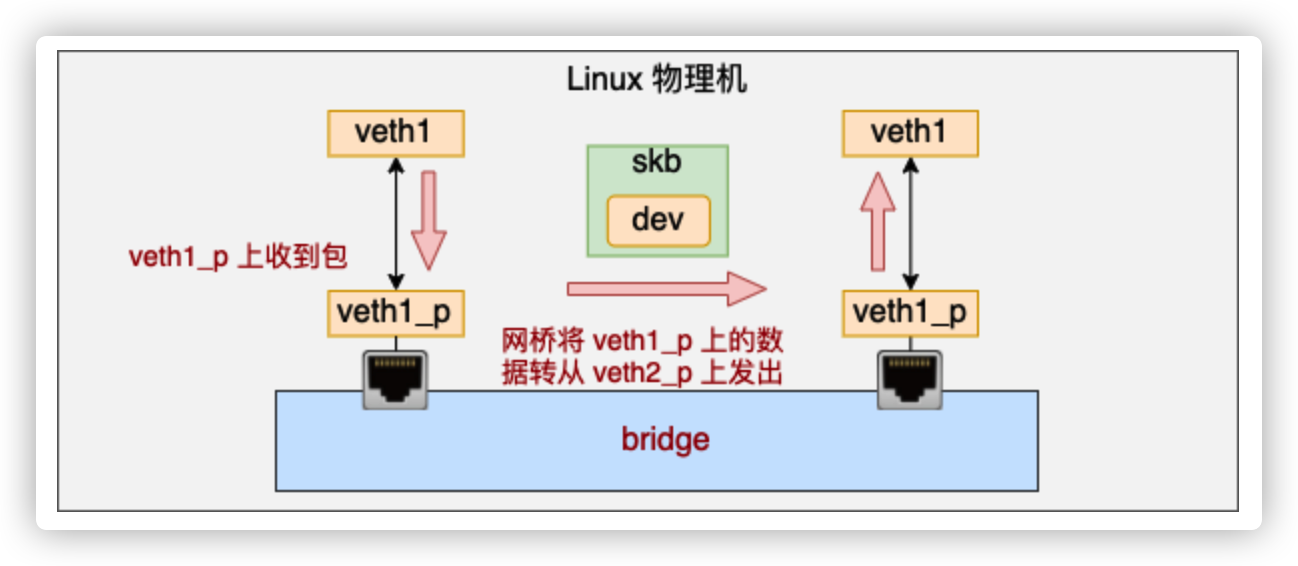
//file: net/core/dev.c
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
...
// tcpdump 抓包点
list_for_each_entry_rcu(...);
// 执行设备的 rx_handler(也就是 br_handle_frame)
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto unlock; //在这里,网桥处理完后,一般就直接出来了
}
}
...将 skb 上的设备 dev 改为了新的目的 dev
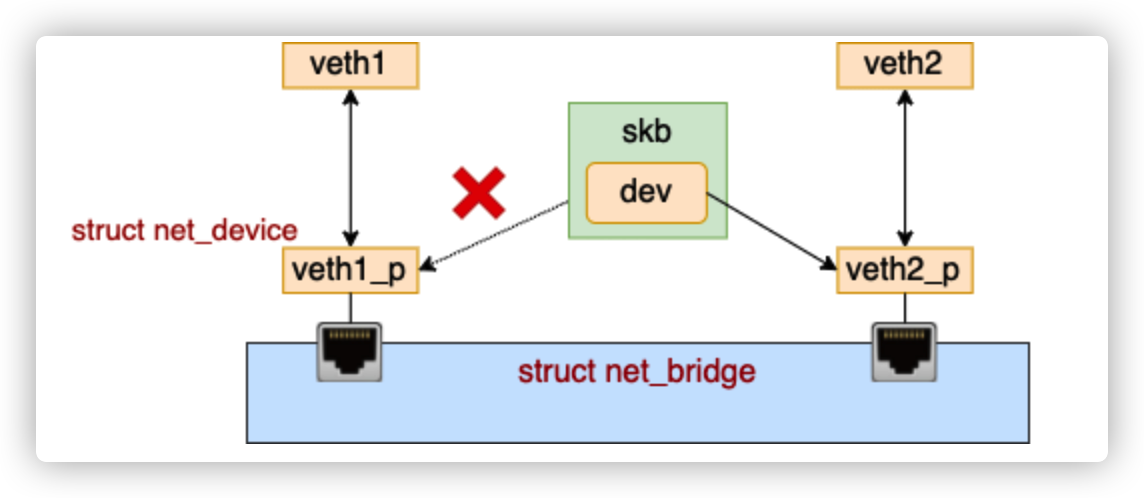
后续的发送过程就是 dev_queue_xmit => dev_hard_start_xmit => veth_xmit。在 veth_xmit 中会获取到当前 veth 的对端,然后把数据给它发送过去
总结如下:
网络命名空间
虚拟化中还有很重要的一步,那就是隔离。借用 Docker 的概念来说,那就是不能让 A 容器用到 B 容器的设备,甚至连看一眼都不可以。只有这样才能保证不同的容器之间复用硬件资源的同时,还不会影响其它容器的正常运行。
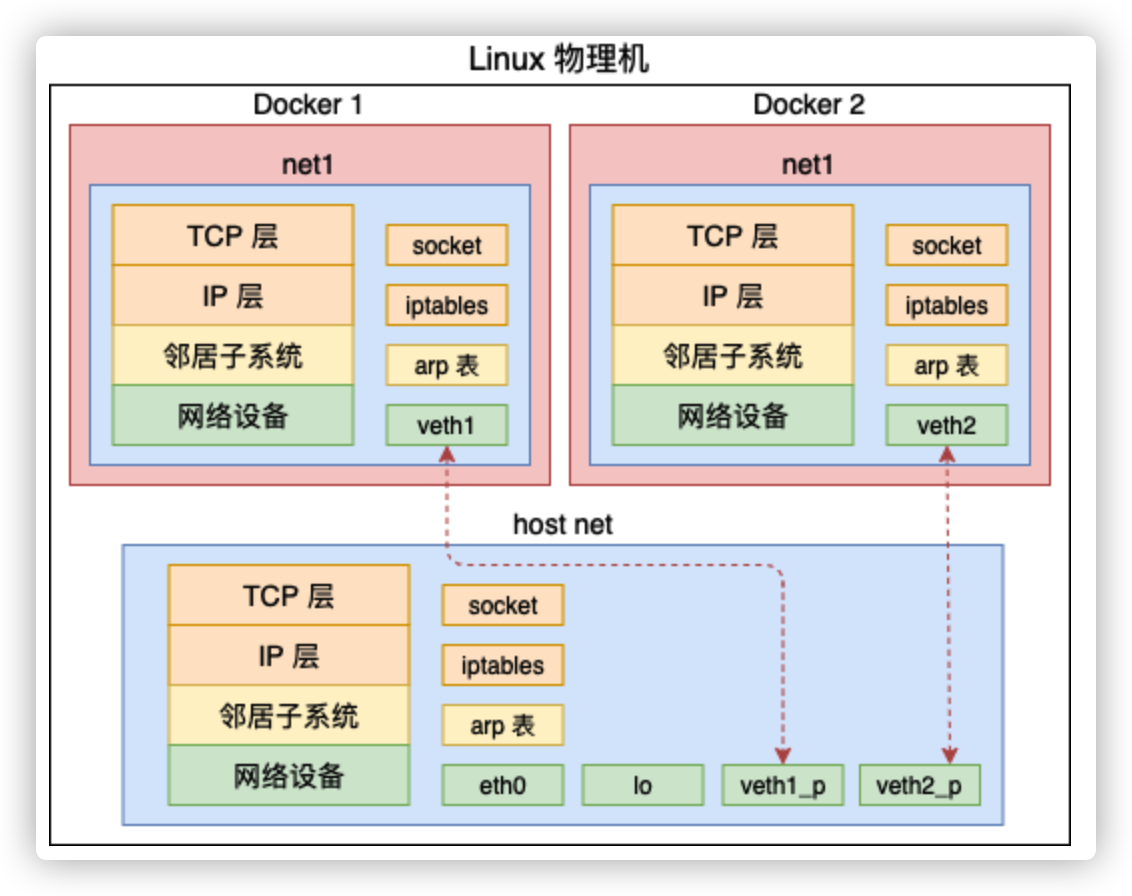
在 Linux 上实现隔离的技术手段就是 namespace。通过 namespace 可以隔离容器的进程 PID、文件系统挂载点、主机名等多种资源。不过我们今天重点要介绍的是网络 namespace,简称 netns。它可以为不同的命名空间从逻辑上提供独立的网络协议栈,具体包括网络设备、路由表、arp表、iptables、以及套接字(socket)等。使得不同的网络空间就都好像运行在独立的网络中一样。
实现
创建一个新的网络命名空间
# ip netns add net1查看一下它的 iptable、路由表、以及网络设备
# ip netns exec net1 route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface # ip netns exec net1 iptables -L ip netns exec net1 iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination ...... # ip netns exec net1 ip link list lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00新创建的 netns,所以上述的输出中路由表、iptable规则都是空的.不过这个命名空间中初始的情况下就存在一个 lo 本地环回设备,只不过默认是 DOWN(未启动)状态。
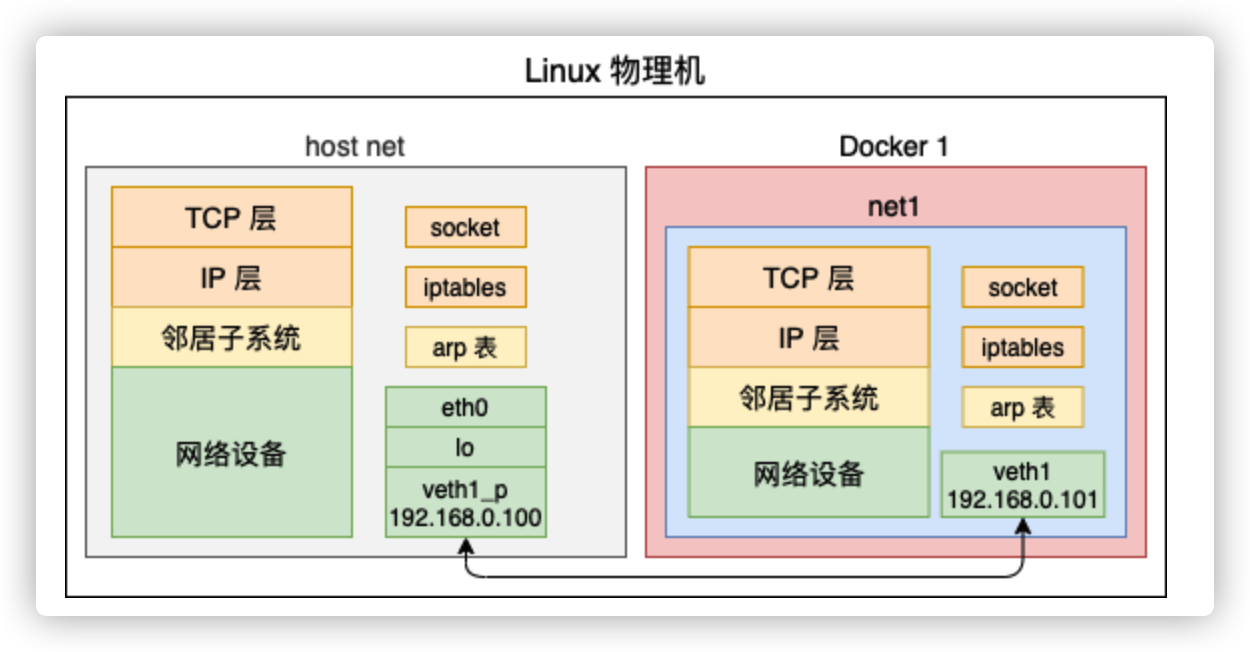
创建一对儿 veth,并把 veth 的一头添加给它
# ip link add veth1 type veth peer name veth1_p # ip link set veth1 netns net1在母机上查看一下当前的设备,发现已经看不到 veth1 这个网卡设备了,只能看到 veth1_p
# ip link list 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 ... 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 ... 3: eth1: <BROADCAST,MULTICAST> mtu 1500 ... 45: veth1_p@if46: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000 link/ether 0e:13:18:0a:98:9c brd ff:ff:ff:ff:ff:ff link-netnsid 0查看net1网络空间的网络设备
# ip netns exec net1 ip link list 1: lo: <LOOPBACK> mtu 65536 ... 46: veth1@if45: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000 link/ether 7e:cd:ec:1c:5d:7a brd ff:ff:ff:ff:ff:ff link-netnsid 0把这对儿 veth 分别配置上 ip,并把它们启动起来
# ip addr add 192.168.0.100/24 dev veth1_p # ip netns exec net1 ip addr add 192.168.0.101/24 dev veth1 # ip netns exec net1 ip link set dev veth1_p up # ip netns exec net1 ip link set dev veth1 up在母机和 net1 中分别执行 ifconfig 查看当前启动的网络设备
让它和母机通信一下试试
# ip netns exec net1 ping 192.168.0.100 -I veth1 PING 192.168.0.100 (192.168.0.100) from 192.168.0.101 veth1: 56(84) bytes of data. 64 bytes from 192.168.0.100: icmp_seq=1 ttl=64 time=0.027 ms 64 bytes from 192.168.0.100: icmp_seq=2 ttl=64 time=0.010 ms
内核结构
网络 namespace 的主要数据结构是struct net
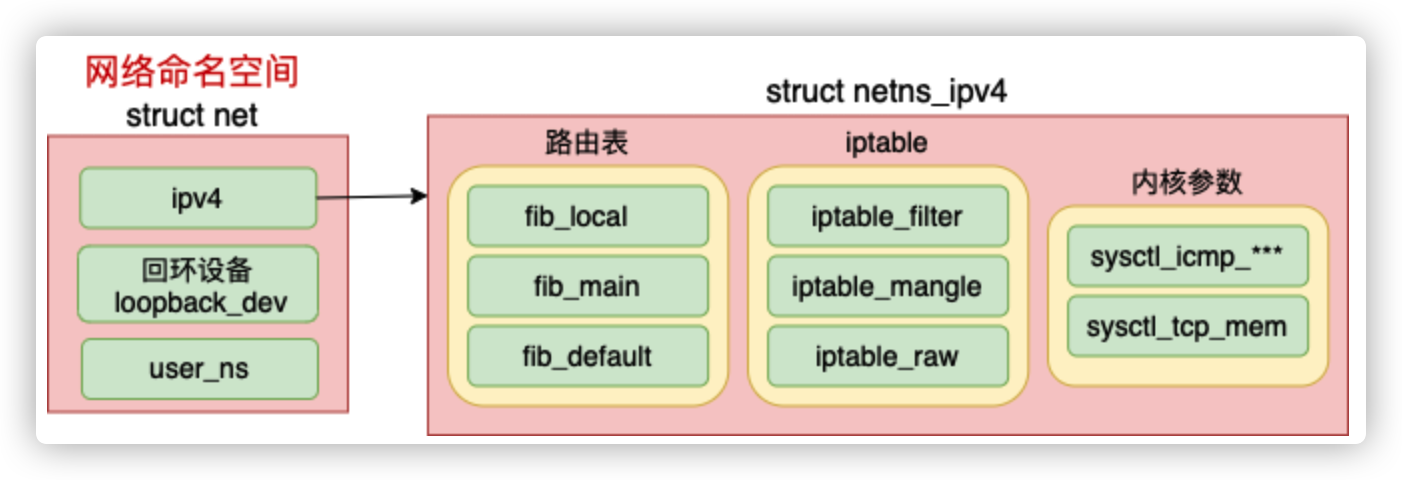
可见每个 net 下都包含了自己的路由表、iptable 以及内核参数配置等等。
//file:include/net/net_namespace.h
struct net {
//每个 net 中都有一个回环设备
struct net_device *loopback_dev; /* The loopback */
//路由表、netfilter都在这里
struct netns_ipv4 ipv4;
......
unsigned int proc_inum;
}网络 netspace 中最核心的数据结构是 struct netns_ipv4 ipv4。在这个数据结构里,定义了每一个网络空间专属的路由表、ipfilter 以及各种内核参数。
//file: include/net/netns/ipv4.h
struct netns_ipv4 {
//路由表
struct fib_table *fib_local;
struct fib_table *fib_main;
struct fib_table *fib_default;
//ip表
struct xt_table *iptable_filter;
struct xt_table *iptable_raw;
struct xt_table *arptable_filter;
//内核参数
long sysctl_tcp_mem[3];
...
}netns创建过程分析
创建新的命名空间,进入内核的copy_net_ns函数
//file: net/core/net_namespace.c struct net *copy_net_ns(unsigned long flags, struct user_namespace *user_ns, struct net *old_net) { struct net *net; // 重要!!! // 不指定 CLONE_NEWNET 就不会创建新的网络命名空间 if (!(flags & CLONE_NEWNET)) return get_net(old_net); //申请新网络命名空间并初始化 net = net_alloc(); rv = setup_net(net, user_ns); ... }setup_net 是初始化网络命名空间的.
网络子系统初始化
命名空间内的各个组件都是在 setup_net 时初始化的,包括路由表、tcp 的 proc 伪文件系统、iptable 规则读取等等。
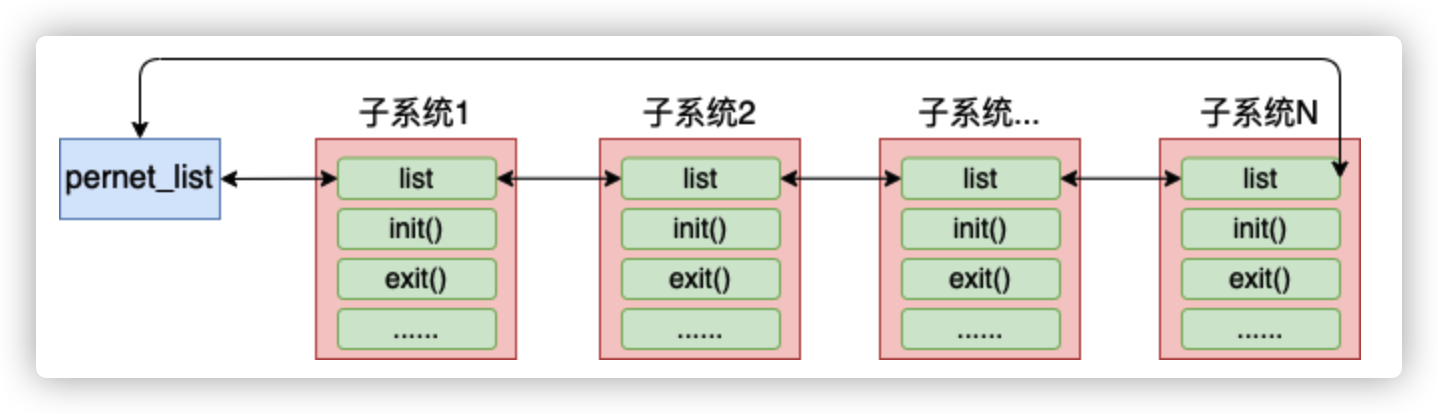
由于内核网络模块的复杂性,在内核中将网络模块划分成了各个子系统。每个子系统都定义了一个
//file: include/net/net_namespace.h struct pernet_operations { // 链表指针 struct list_head list; // 子系统的初始化函数 int (*init)(struct net *net); // 网络命名空间每个子系统的退出函数 void (*exit)(struct net *net); void (*exit_batch)(struct list_head *net_exit_list); int *id; size_t size; };各个子系统通过调用 register_pernet_subsys 或 register_pernet_device 将其初始化函数注册到网络命名空间系统的全局链表 pernet_list 中。你在源码目录下用这两个函数搜索的话,会看到各个子系统的注册过程。
添加设备
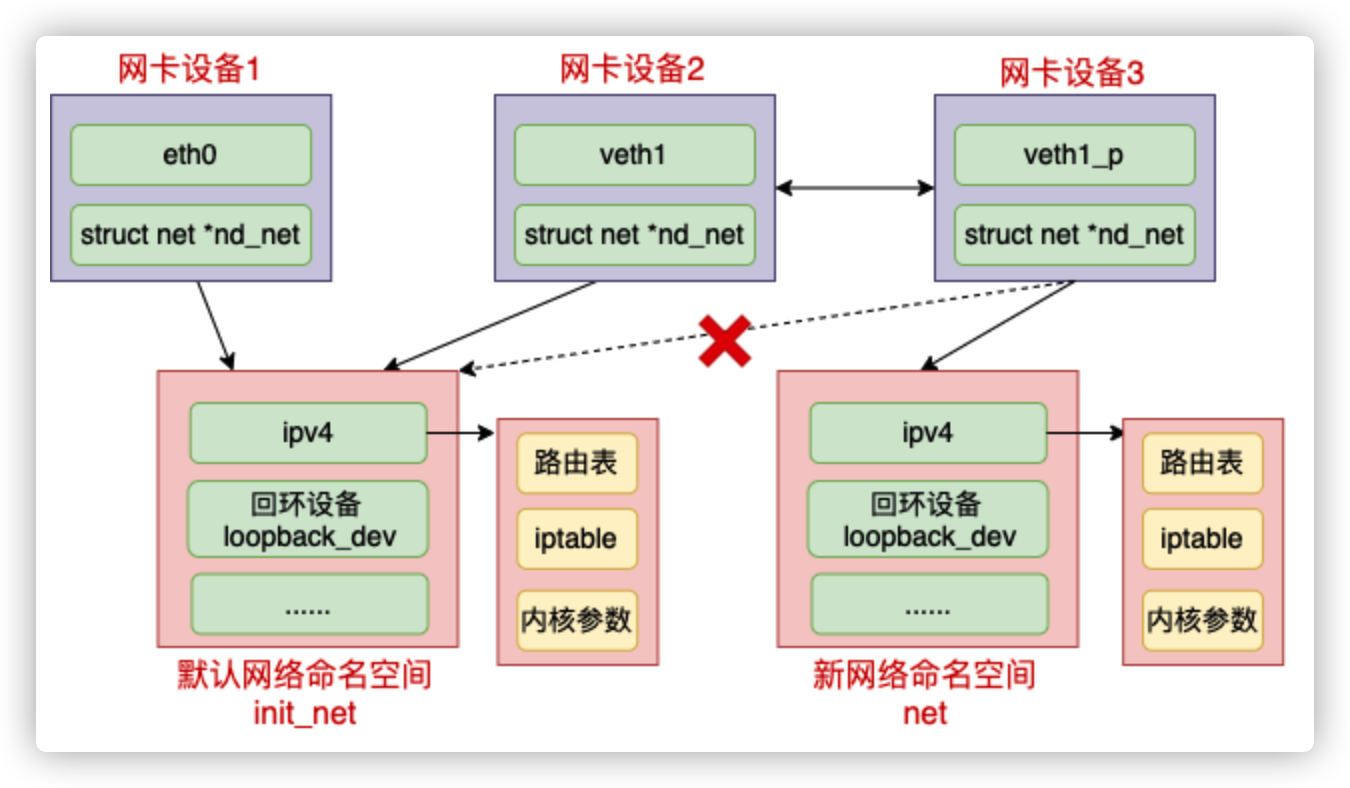
在一个设备刚刚创建出来的时候,它是属于默认网络命名空间 init_net 的,包括 veth 设备。不过可以在创建完后修改设备到新的网络命名空间。
模拟Docker通信
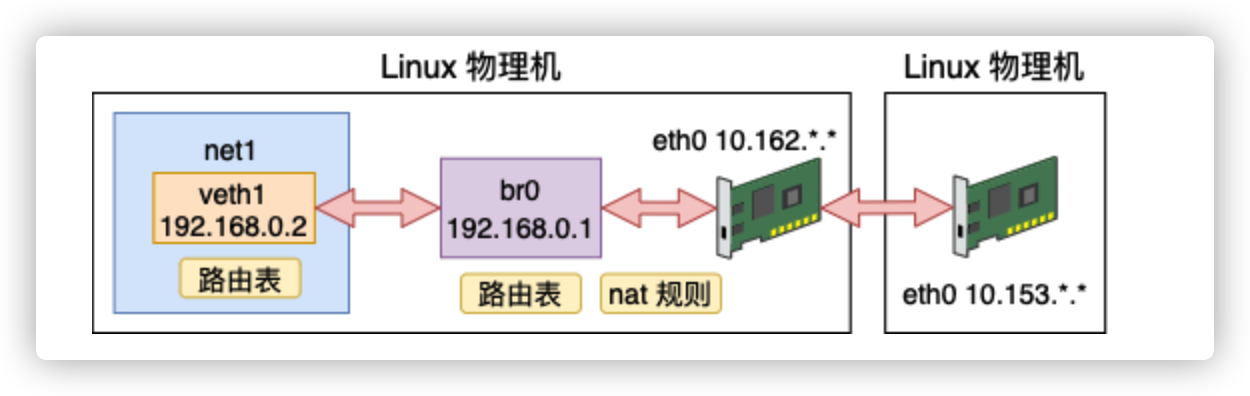
让网络空间net1和外部进行通信,详细实验过程请看这里
虚拟网络到外网通信
创建一个网络命名空间、veth、bridge
请求宿主机外部网络
查看当前net1的路由表
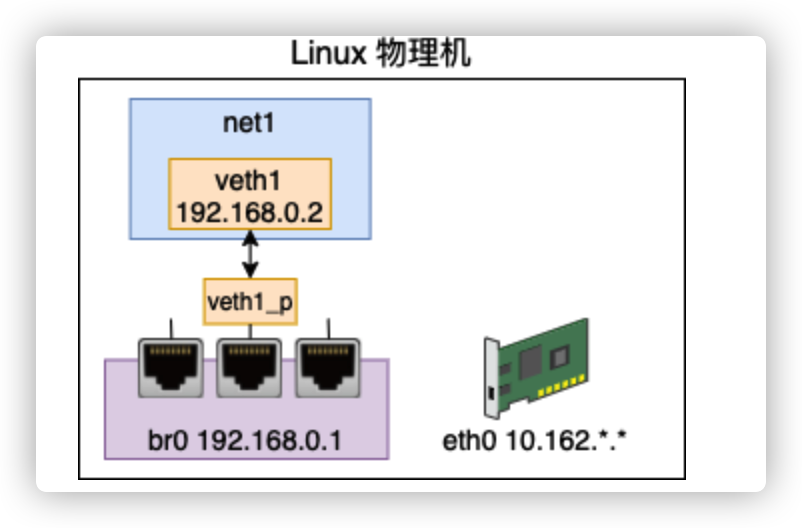
# ip netns exec net1 route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1net1 这个 namespace 下默认只有 192.168.0.* 这个网段的路由规则。
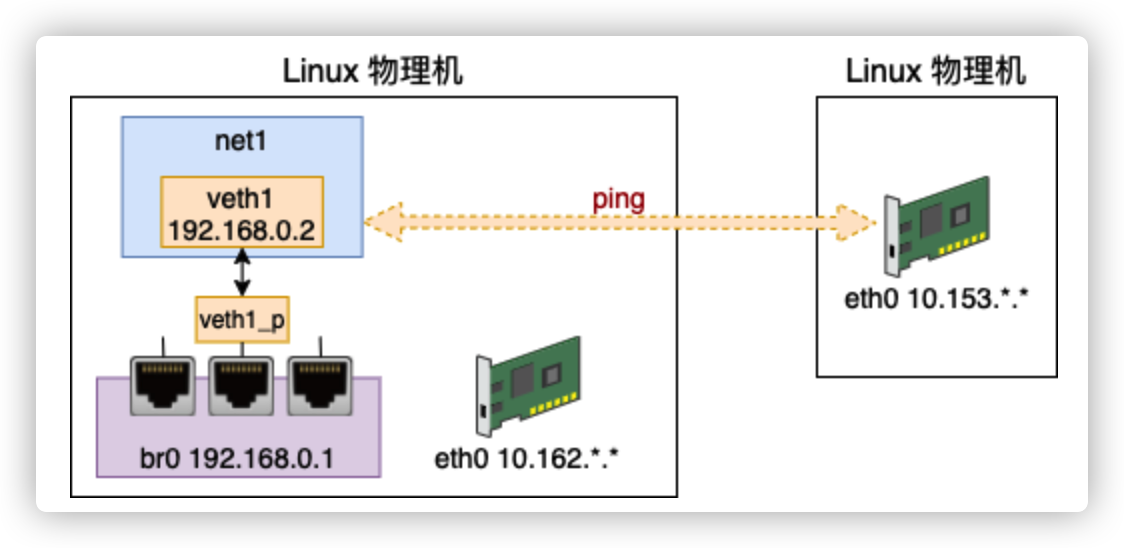
直接ping IP 10.153.. ,根据这个路由表里找不到出口,自然就发送失败
添加默认路由规则
只要匹配不到其它规则就默认送到 veth1 上,同时指定下一条是它所连接的 bridge(192.168.0.1)。
# ip netns exec net1 route add default gw 192.168.0.1 veth1这个时候ping IP 10.153.. 依然会失败,上面路由帮我们把数据包从 veth 正确送到了 bridge 这个网桥上。接下来网桥还需要 bridge 转发到 eth0 网卡上。
Bridge转发设置
# sysctl net.ipv4.conf.all.forwarding=1 # iptables -P FORWARD ACCEPT还存在一个问题。那就是外部的机器并不认识 192.168.0.* 这个网段的 ip。它们之间都是通过 10.153.. 来进行通信的,需要设置nat
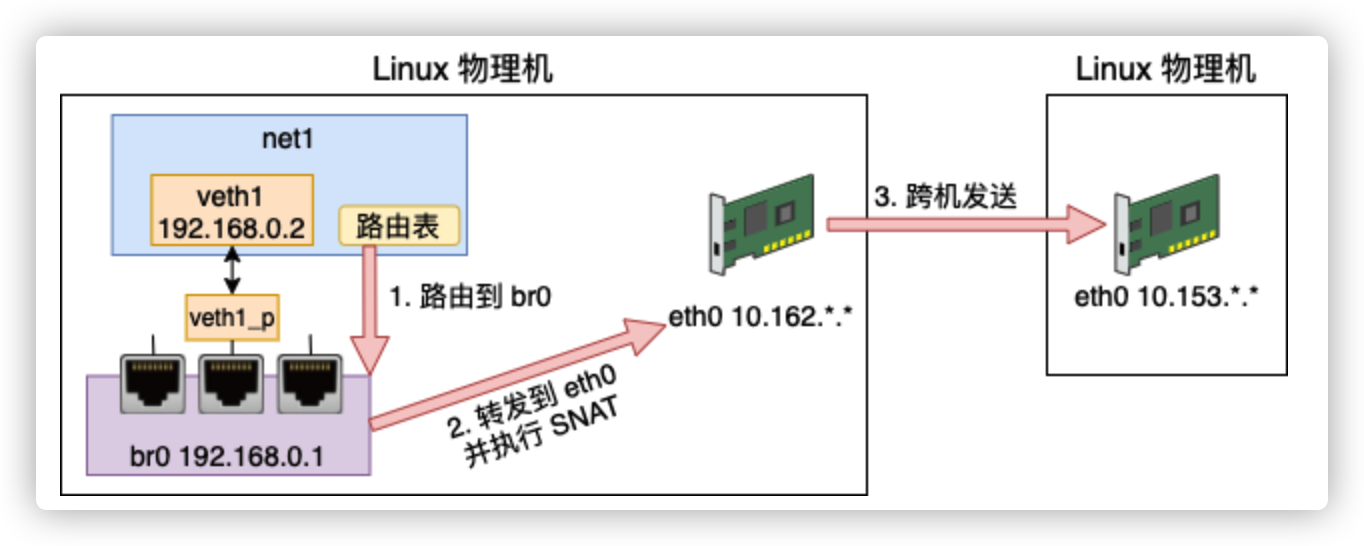
SNAT实现内部虚拟网络访问外网
将 namespace 请求中的 IP(192.168.0.2)换成外部网络认识的 10.153.*.*,进而达到正常访问外部网络的效果。
# iptables -t nat -A POSTROUTING -s 192.168.0.0/24 ! -o br0 -j MASQUERADE这个时候就可以ping通外网了
外网到虚拟设备通信
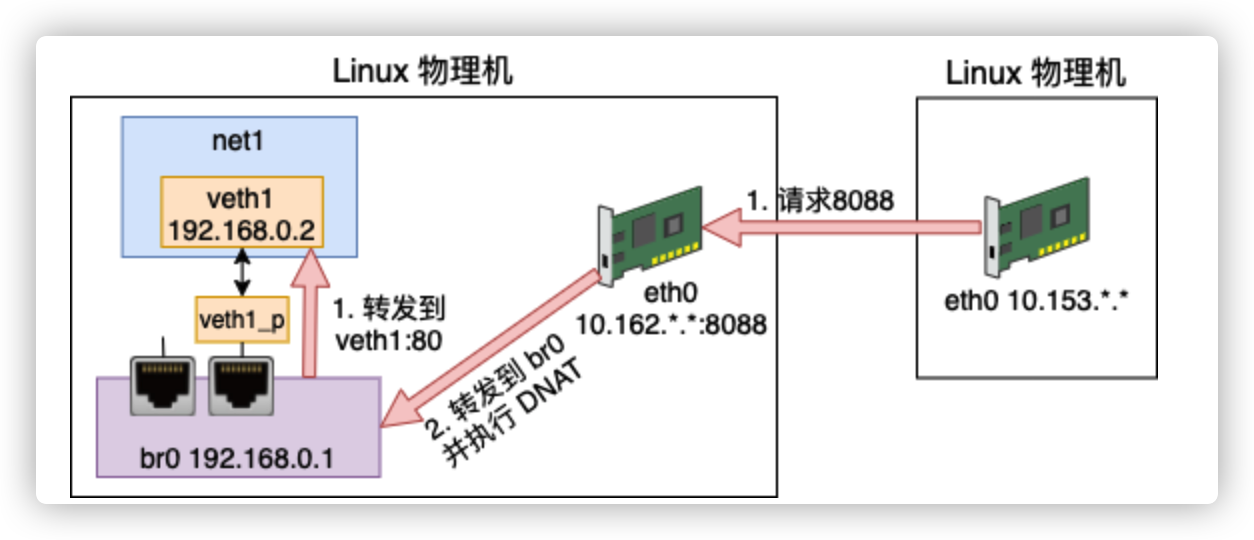
虚拟网络环境中 192.168.0.2 这个 IP 外界是不认识它的。只有这个宿主机知道它是谁。所以我们同样还需要 NAT 功能。
这次我们是要实现外部网络访问内部地址,所以需要的是 DNAT 配置。DNAT 和 SNAT 配置中有一个不一样的地方就是需要明确指定容器中的端口在宿主机上是对应哪个。比如在 docker 的使用中,是通过 -p 来指定端口的对应关系。
docker指定端口和宿主机端口的对应关系
# docker run -p 8000:80 ...配置 DNAT
# iptables -t nat -A PREROUTING ! -i br0 -p tcp -m tcp --dport 8088 -j DNAT --to-destination 192.168.0.2:80判断一下如果流量不是来自 br0,并且是访问 tcp 的 8088 的话,那就转发到 192.168.0.2:80 。
在 net1 环境中启动一个 Server
# ip netns exec net1 nc -lp 80telnet 连一下 10.162.. 8088
# telnet 10.162.*.* 8088 Trying 10.162.*.*... Connected to 10.162.*.*. Escape character is '^]'.成功
内核的namespace
概念
在 Linux 中,很多我们平常熟悉的概念都是归属到某一个特定的网络 namespace 中的,比如进程、网卡设备、socket 等等。
Linux 中每个进程(线程)都是用 task_struct 来表示的。每个 task_struct 都要关联到一个 namespace 对象 nsproxy,而 nsproxy 又包含了 netns。对于网卡设备和 socket 来说,通过自己的成员来直接表明自己的归属。
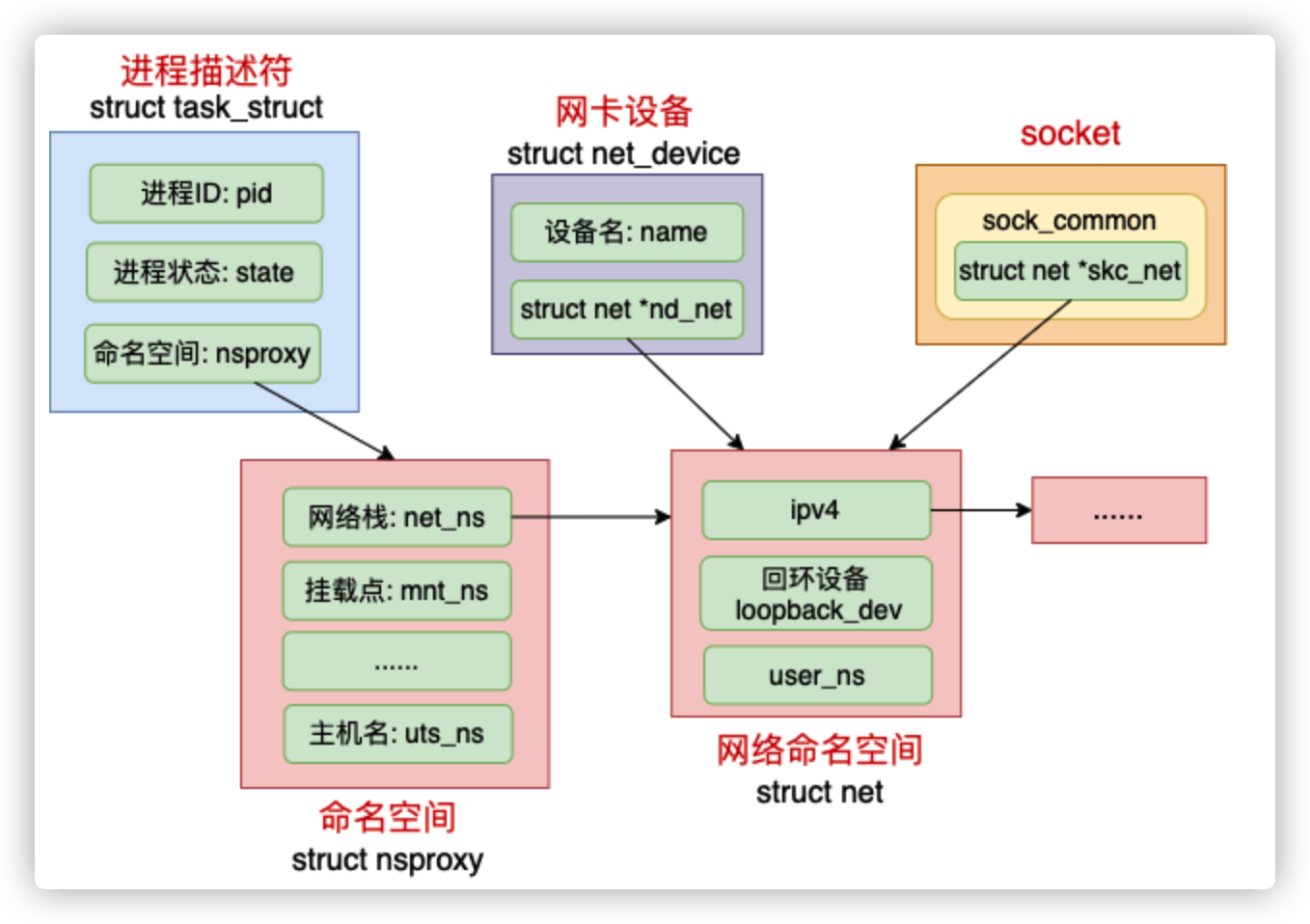
拿网络设备来举例,只有归属到当前 netns 下的时候才能够通过 ifconfig 看到,否则是不可见的。
数据结构
进程
//file:include/linux/sched.h struct task_struct { /* namespaces */ struct nsproxy *nsproxy; ...... }命名空间
//file: include/linux/nsproxy.h struct nsproxy { struct uts_namespace *uts_ns; // 主机名 struct ipc_namespace *ipc_ns; // IPC struct mnt_namespace *mnt_ns; // 文件系统挂载点 struct pid_namespace *pid_ns; // 进程标号 struct net *net_ns; // 网络协议栈 };网络设备
//file: include/linux/netdevice.h struct net_device{ //设备名 char name[IFNAMSIZ]; //网络命名空间 struct net *nd_net; ... }所有的网络设备刚创建出来都是在宿主机默认网络空间下的。可以通过
ip link set 设备名 netns 网络空间名将设备移动到另外一个空间里去。前面的实验里,当 veth 1 移动到 net1 下的时候,该设备在宿主机下“消失”了,在 net1 下就能看到了。socket
//file: struct sock_common { struct net *skc_net; }
操作ns
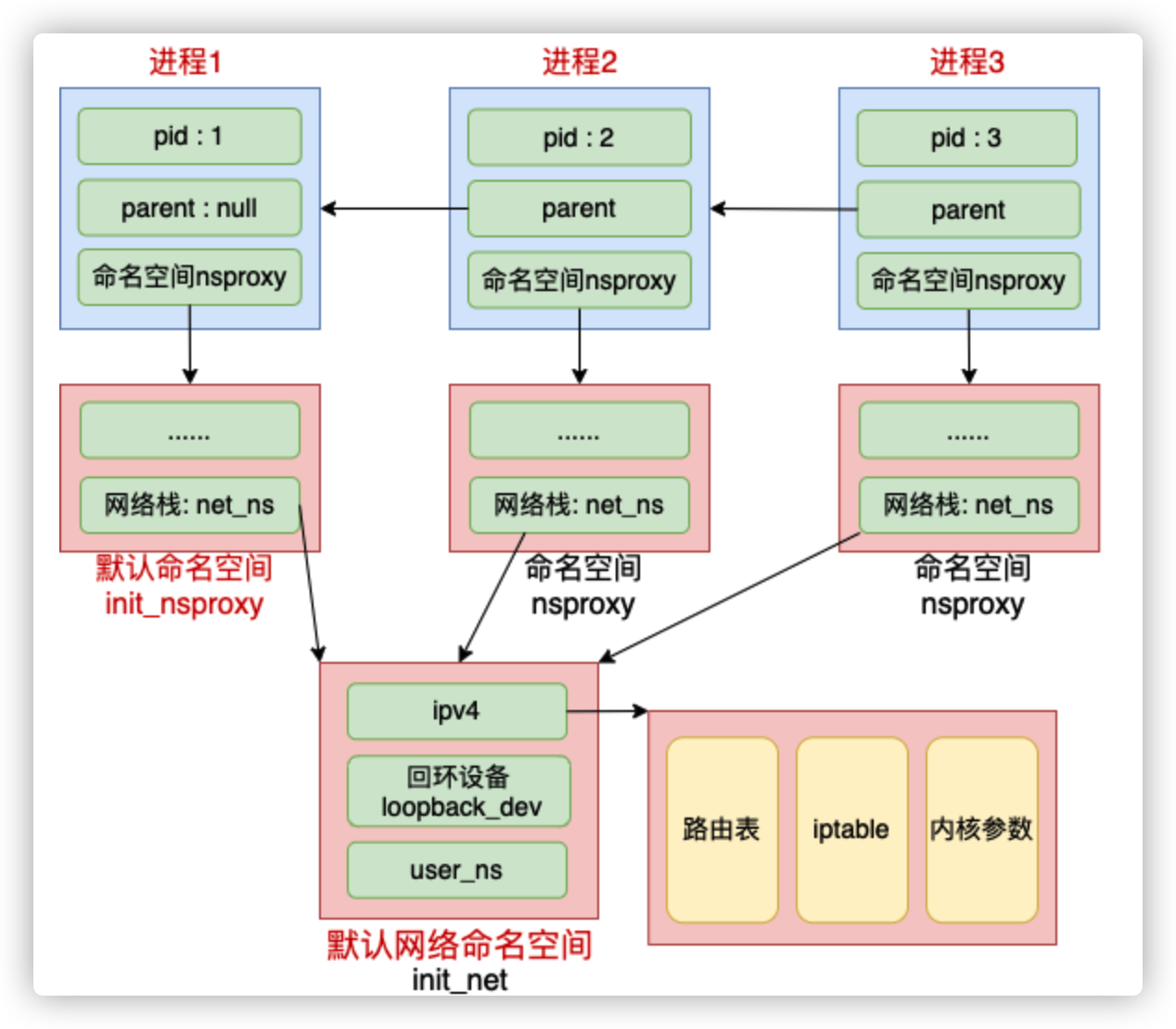
Linux 上存在一个默认的网络命名空间,Linux 中的 1 号进程初始使用该默认空间。Linux 上其它所有进程都是由 1 号进程派生出来的,在派生 clone 的时候如果没有额外特别指定,所有的进程都将共享这个默认网络空间。
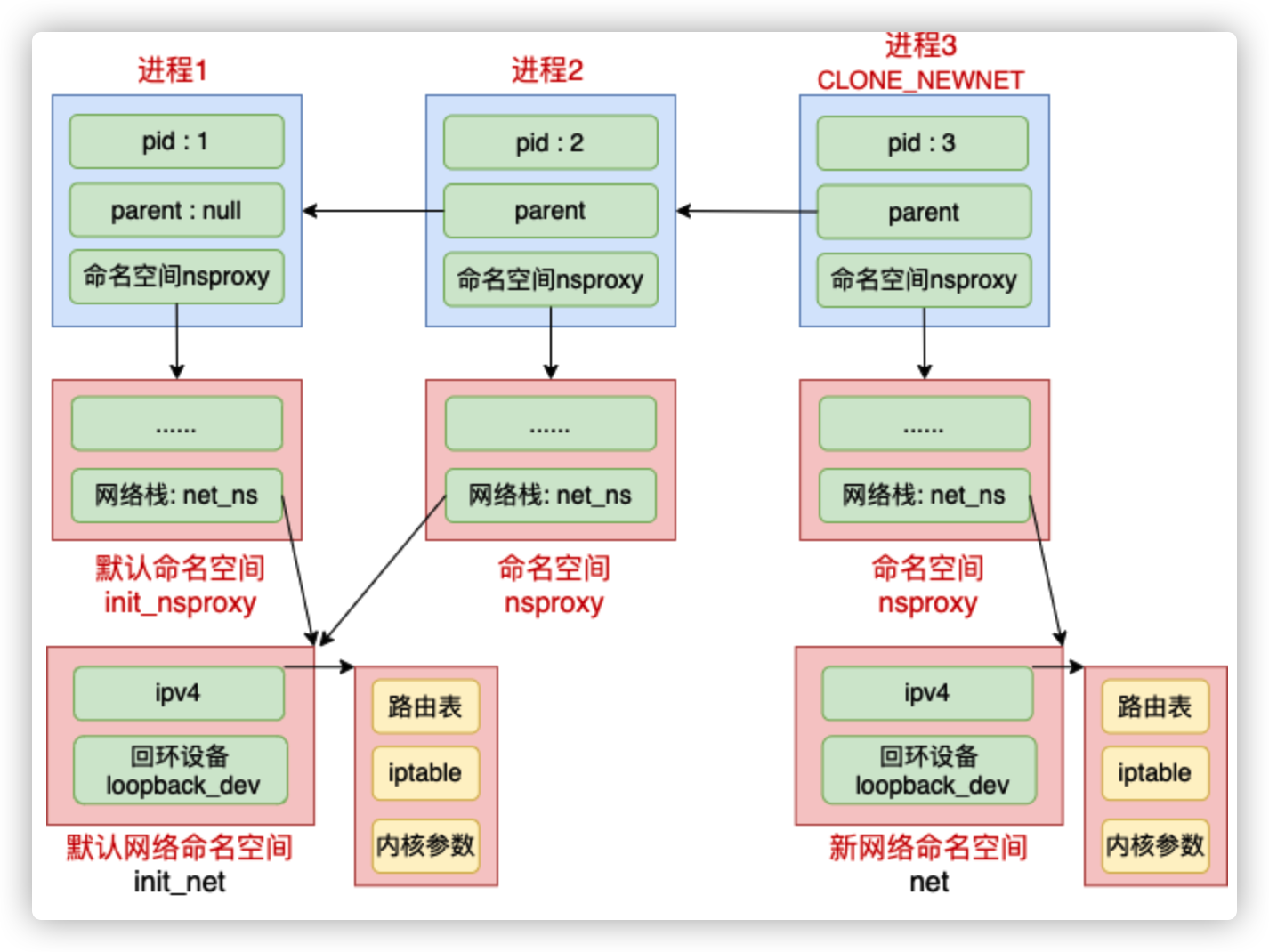
内核提供了三种操作命名空间的方式,分别是 clone、setns 和 unshare。这里先介绍clone,ip netns add 使用的是 unshare,原理和 clone 是类似的。
Linux 中所有的进程都是由这个 1 号进程创建的。如果创建子进程过程中没有指定 CLONE_NEWNET 这个 flag 的话,就直接还使用这个默认的网络空间。
如果创建进程过程中指定了 CLONE_NEWNET,那么就会重新申请一个网络命名空间出来。见如下的关键函数 copy_net_ns(它的调用链是 do_fork => copy_process => copy_namespaces => create_new_namespaces => copy_net_ns)。
//file: net/core/net_namespace.c
struct net *copy_net_ns(unsigned long flags,
struct user_namespace *user_ns, struct net *old_net)
{
struct net *net;
// 重要!!!
// 不指定 CLONE_NEWNET 就不会创建新的网络命名空间
if (!(flags & CLONE_NEWNET))
return get_net(old_net);
//申请新网络命名空间并初始化
net = net_alloc();
rv = setup_net(net, user_ns);
...
}
其中,setup_net 是初始化网络命名空间的!
iptables
Linux 在内核网络组件中很多关键位置布置了 netfilter 过滤器。Iptables 就是基于 netfilter 来实现的。所以本文中 iptables 和 netfilter 这两个名词有时候就混着用了。
Netfilter 的实现可以简单地归纳为四表五链
五链
Linux 下的 netfilter 在内核协议栈的各个重要关卡埋下了五个钩子。每一个钩子都对应是一系列规则,以链表的形式存在,所以俗称五链。当网络包在协议栈中流转到这些关卡的时候,就会依次执行在这些钩子上注册的各种规则,进而实现对网络包的各种处理。
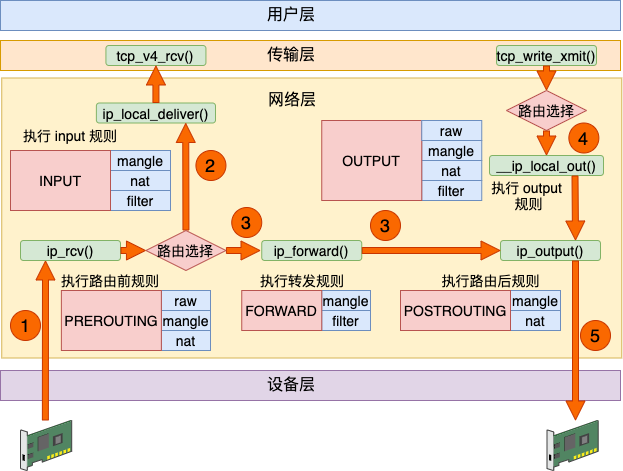
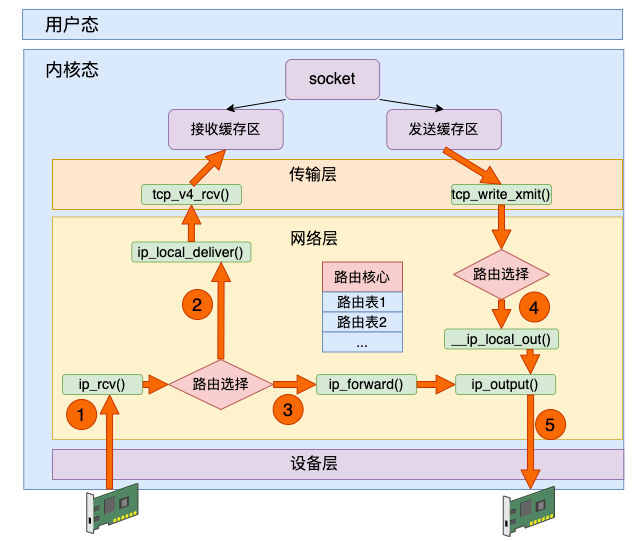
数据接收过程走的是 1 和 2,发送过程走的是 4 、5,转发过程是 1、3、5。有了这张图,我们能更清楚地理解 iptables 和内核的关系。
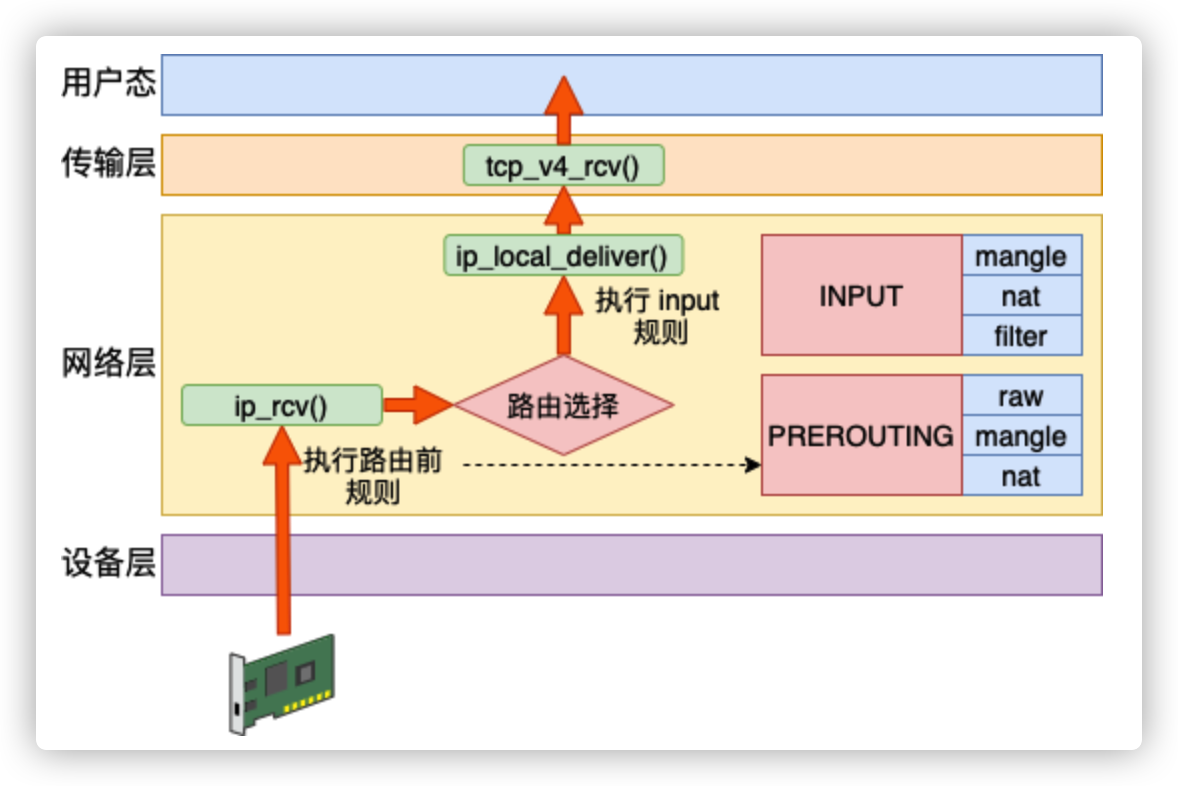
接收
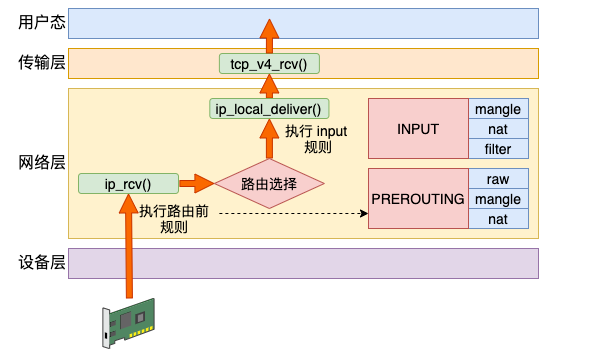
Linux 在网络包接收在 IP 层的入口函数是 ip_rcv。网络在这里包碰到的第一个 HOOK 就是 PREROUTING。当该钩子上的规则都处理完后,会进行路由选择。如果发现是本设备的网络包,进入 ip_local_deliver 中,在这里又会遇到 INPUT 钩子。
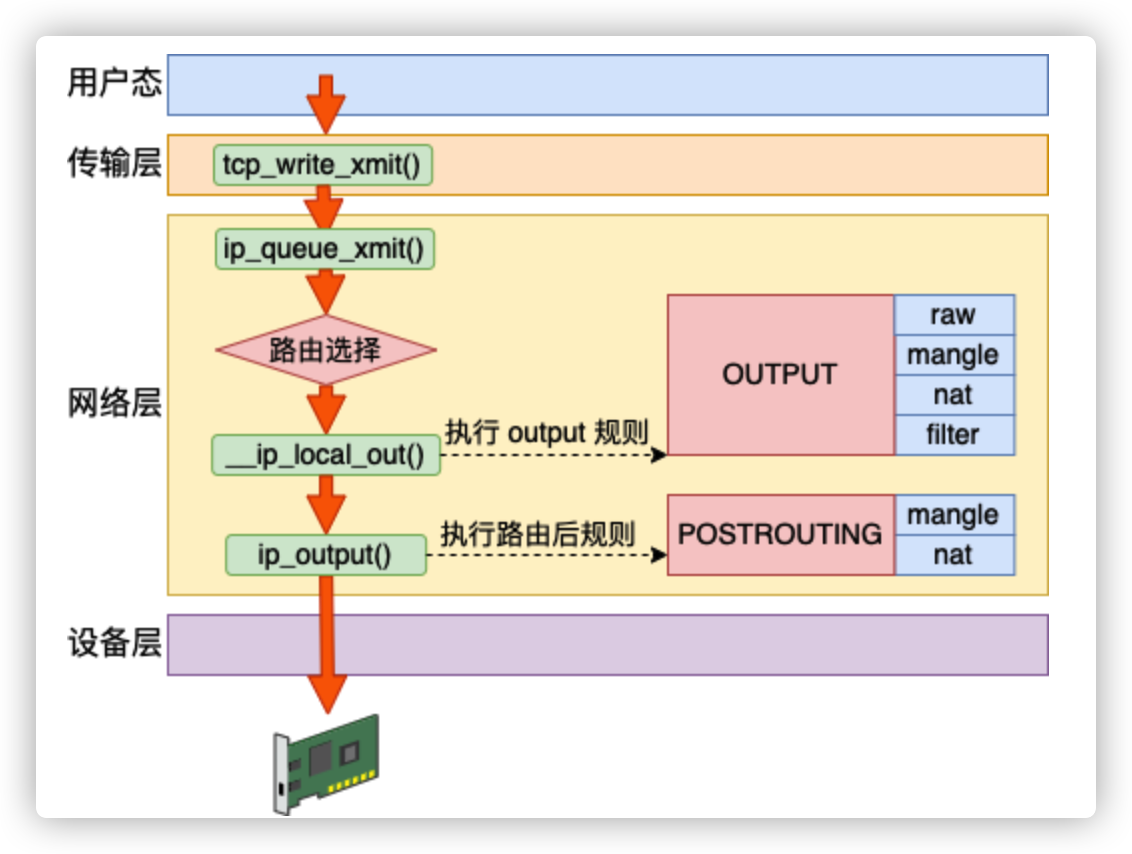
发送
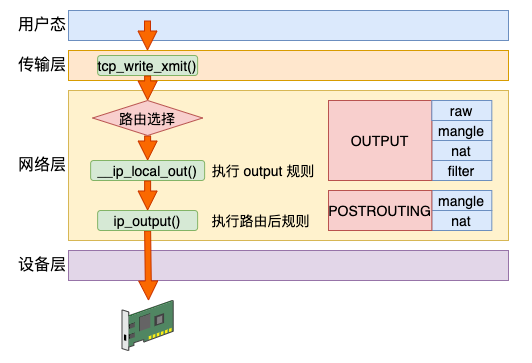
Linux 在网络包发送的过程中,首先是发送的路由选择,然后碰到的第一个 HOOK 就是 OUTPUT,然后接着进入 POSTROUTING 链。
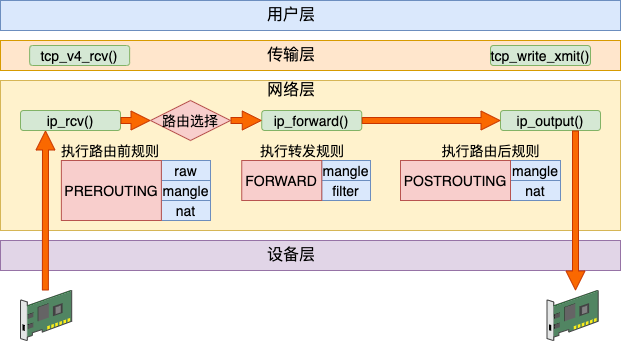
转发
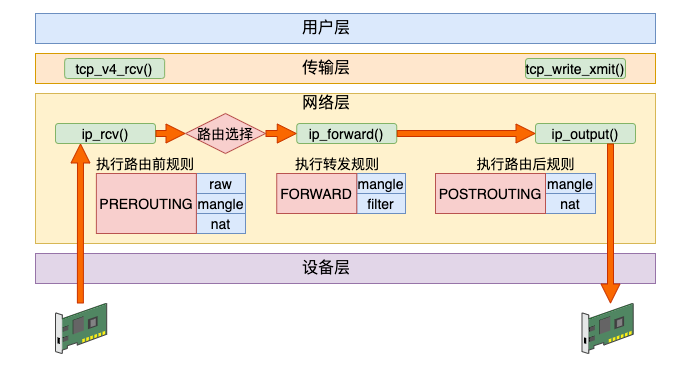
其实除了接收和发送过程以外,Linux 内核还可以像路由器一样来工作。它将接收到网络包(不属于自己的),然后根据路由表选到合适的网卡设备将其转发出去。
这个过程中,先是经历接收数据的前半段。在 ip_rcv 中经过 PREROUTING 链,然后路由后发现不是本设备的包,那就进入 ip_forward 函数进行转发,在这里又会遇到 FORWARD 链。最后还会进入 ip_output 进行真正的发送,遇到 POSTROUTING 链。
四表
在每一个链上都可能是由许多个规则组成的。在 NF_HOOK 执行到这个链的时候,就会把规则按照优先级挨个过一遍。如果有符合条件的规则,则执行规则对应的动作。

而这些规则根据用途的不同,又可以raw、mangle、nat 和 filter。
- row 表的作用是将命中规则的包,跳过其它表的处理,它的优先级最高。
- mangle 表的作用是根据规则修改数据包的一些标志位,比如 TTL
- nat 表的作用是实现网络地址转换
- filter 表的作用是过滤某些包,这是防火墙工作的基础
例如在 PREROUTING 链中的规则中,分别可以执行 row、mangle 和 nat 三种功能。
我们再来聊聊,为什么不是全部四个表呢。这是由于功能的不同,不是所有功能都会完全使用到五个链。
Raw 表目的是跳过其它表,所以只需要在接收和发送两大过程的最开头处把关,所以只需要用到 PREROUTING 和 OUTPUT 两个钩子。
Mangle 表有可能会在任意位置都有可能会修改网络包,所以它是用到了全部的钩子位置。
NAT 分为 SNAT(Source NAT)和 DNAT(Destination NAT)两种,可能会工作在 PREROUTING、INPUT、OUTPUT、POSTROUTING 四个位置。
Filter 只在 INPUT、OUTPUT 和 FORWARD 这三步中工作就够了。
从整体上看,四链五表的关系如下图。
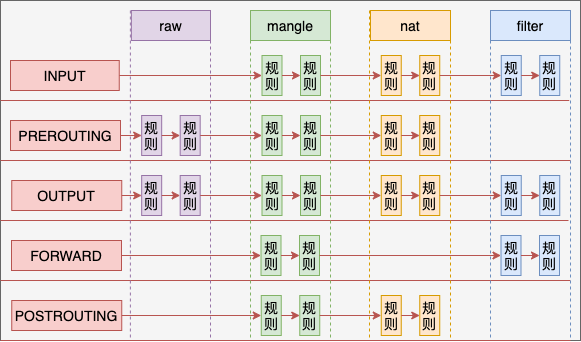
这里再多说一点,每个命名空间都是有自己独立的 iptables 规则的。我们拿 NAT 来举例,内核在遍历 NAT 规则的时候,是从 net(命名空间变量)的 ipv4.nat_table 上取下来的。NF_HOOK 最终会执行到 nf_nat_rule_find 函数。
Linux路由
发送数据时选路
Linux 之所以在发送数据包的时候需要进行路由选择,这是因为服务器上是可能会有多张网卡设备存在的。数据包在发送的时候,一路通过用户态、TCP 层到了 IP 层的时候,就要进行路由选择,以决定使用哪张网卡设备把数据包送出去。
Linux 中可以有多张路由表,最重要和常用的是 local 和 main。
local 路由表中统一记录本地,确切的说是本网络命名空间中的网卡设备 IP 的路由规则。
#ip route list table local
local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1其它的路由规则,一般都是在 main 路由表中记录着的。可以用 ip route list table local 查看,也可以用更简短的 route -n
接收数据时选路
接收数据包的时候也需要进行路由选择。这是因为 Linux 可能会像路由器一样工作,将收到的数据包通过合适的网卡将其转发出去。
Linux 在 IP 层的接收入口 ip_rcv 执行后调用到 ip_rcv_finish。在这里展开路由选择。如果发现确实就是本设备的网络包,那么就通过 ip_local_deliver 送到更上层的 TCP 层进行处理。
如果路由后发现非本设备的网络包,那就进入到 ip_forward 进行转发,最后通过 ip_output 发送出去。
小结
Linux端口重用
概念
在 Linux 3.9 以前的版本中,一个端口只能被一个 socket 绑定。在多进程的场景下,无论是使用一个进程来在这个 socket 上 accept,还是说用多个 worker 来 accept 同一个 socket,在高并发的场景下性能都显得有那么一些低下。
在 2013 年发布的 3.9 中添加了 reuseport 的特性。该特定允许多个进程分别用不同的 socket 绑定到同一个端口。当有流量到达的时候,在内核态以随机的方式进行负载均衡。避免了锁的开销。
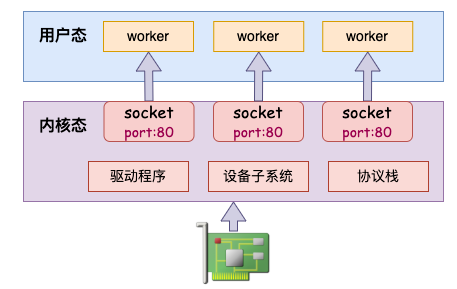
该特性允许同一机器上的多个进程同时创建不同的 socket 来 bind 和 listen 在相同的端口上。然后在内核层面实现多个用户进程的负载均衡。
配置REUSEPORT
想给自己的服务开启 REUSEPORT 很简单,就是给自己 server 里 listen 用的 socket 上加这么一句。(这里以 c 为 demo,其它语言可能会有差异,但基本上差不多)
setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, ...);测试
相同 port 多服务启动
编译后,分别在多个控制台下运行一下试试,看是否能够启动起来。
$./test-server 0.0.0.0 6000
Start server on 0.0.0.0:6000 successed, pid is 23179
$./test-server 0.0.0.0 6000
Start server on 0.0.0.0:6000 successed, pid is 23177
$./test-server 0.0.0.0 6000
Start server on 0.0.0.0:6000 successed, pid is 23185
......没错,全部起来了!这个 6000 的端口被多个 server 进程重复使用了。
- 内核负载均衡验证
由于上述几个监听了相同端口的进程都使用的是 0.0.0.0,那么在计算 score 的时候,他们的得分就都是 2 分。那么就由内核以随机的方式进行负载均衡了。
我们再启动一个客户端,随意发起几个连接请求,统计一下各个server进程收到的连接数。如下可见,该服务器上收到的连接的确是平均散列在各个进程里了。
Server 0.0.0.0 6000 (23179) accept success:15
Server 0.0.0.0 6000 (23177) accept success:25
Server 0.0.0.0 6000 (23185) accept success:20
Server 0.0.0.0 6000 (23181) accept success:19
Server 0.0.0.0 6000 (23183) accept success:21


