目录:
- Spring Data的模块
- 可独立使用Spring Data
- Repository 存储仓库
- 生成的方法
- 分页查询
参考/来源:
Spring Data的模块
Spring Data家族有多个模块:
- Spring Data JPA
- Spring Data Mongo
- ….
但所有的模块都基于**Spring Data Commoms**模块进行扩展。例如Spring Data JPA是针对JPA做扩展的一个子模块;Spring Data Mongo是针对MongoDB的子模块,但是共同的接口都是Spring Data。
可以说Spring Data Commons是其所有子模块的抽象,定义了一系列的操作标准及接口。
注意点:发现在Spring Data方式下引入的Dao层,比如mongodb、Spring data jpa等,Dao层不需要进行注入,且启动类不需要扫描Dao层,有点奇怪
可独立使用Spring Data
Spring Data提供了RepositoryFactory,可以独立于Spring容器之外使用:
RepositoryFactorySupport factory = … // Instantiate factory here
UserRepository repository = factory.getRepository(UserRepository.class);Repository 存储仓库
在Spring Data中,都是基于存储仓库Repository对实体类对象进行CRUD操作的。
其中,最核心的是dao层的Repository接口,在org.springframework.data.repository包中定义。
Repository接口需要指定操作的**实体类的类型、实体类ID的类型**。在该接口中,是没有任何方法的,只是用于标记让Spring Data知道。通常我们会使用CurdRepository这个接口,当然,这个接口也是不包含JPA特性的,我们需要使用JPA特性的话,一般用的是JpaRepository接口。JPA的接口关系图如下:
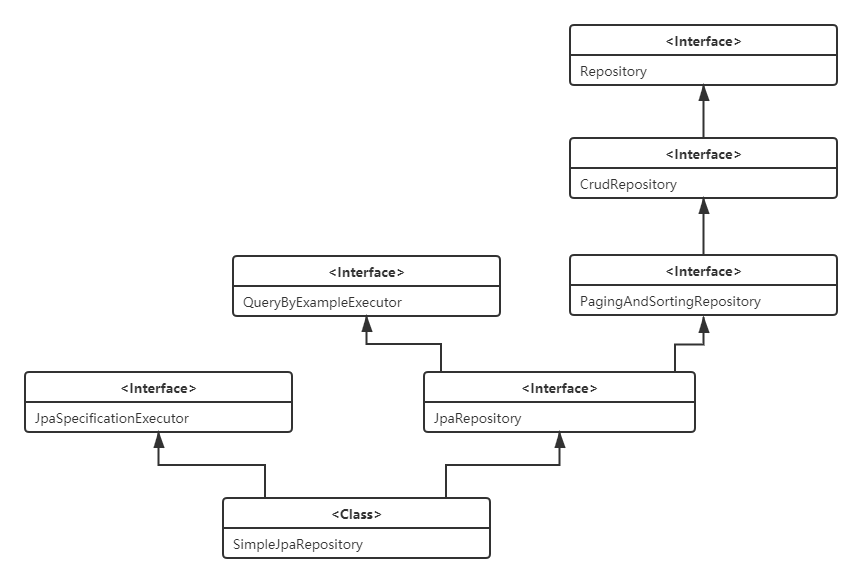
Repository
父接口标记型接口,不包含任何方法.
package org.springframework.data.repository;
import org.springframework.stereotype.Indexed;
@Indexed
public interface Repository<T, ID> {
}<T>是持久层管理的主要实体类型
<ID>是实体类的主ID(也就是对应表的主键)
CrudRepository
提供了简单的增删改查(crud)方法,继承后可以直接使用
package org.springframework.data.repository;
import java.util.Optional;
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}PagingAndSortingRepository
提供了简单的分页和排序功能,查询出所有数据后可以进行分页或者排序,需要传入Sort或者Pageable参数,设置分页或排序的规则。
package org.springframework.data.repository;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}生成方法
按规则生成
Spring Data以方法中的结构为findBy...、deleteBy...,其结构都是动词加上By,By是整个语句拆分的关键点。通常By后面跟着的是查询的参数列表,通过And、Or来连接。
在By后面的参数中,首先将整个内容作为一个属性,如果找不到,然后再参数中以大写字母为分割,直到找到对应的参数为止。
以Spring Data JPA为例:
方法生成规则:
find/delete...(操作) + By(关键字)+属性名称(属性名称的首字母大写)+查询条件(首字母大写)| 关键字 | 方法命名 | sql where 字句 |
|---|---|---|
| And | findByNameAndPwd | where name= ? and pwd =? |
| Or | findByNameOrSex | where name= ? or sex=? |
| Is,Equal | findById, | findByIdEquals |
| Between | findByIdBetween | where id between ? and ? |
| LessThan | findByIdLessThan | where id < ? |
| LessThanEqual | findByIdLessThanEquals | where id <= ? |
| GreaterThan | findByIdGreaterThan | where id > ? |
| GreaterThanEqual | findByIdGreaterThanEquals | where id > = ? |
| After | findByIdAfter | where id > ? |
| Before | findByIdBefore | where id < ? |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,Not Null | findByNameNotNull | where name is not |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ? |
| StartingWith | findByNameStartingWith | where name like ‘?%’ |
| EndingWith | findByNameEndingWith | where name like ‘%?’ |
| Containing | findByNameContaining | where name like ‘%?%’ |
| OrderBy | findByIdOrderByXDesc | where id=? order by x desc |
| Not | findByNameNot | where name <> ? |
| In | findByIdIn(Collection<?> c) | where id in (?) |
| NotIn | findByIdNotIn(Collection<?> c) | where id not in (?) |
| True | findByAaaTue | where aaa = true |
| False | findByAaaFalse | where aaa = false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
使用@Query注解
/**
* Repository接口讲解
* @author Administrator
*
*/
public interface UsersDao extends Repository<Users, Integer> {
//使用@Query注解查询SQL
//nativeQuery:默认的是false.表示不开启sql查询。是否对value中的语句做转义。
@Query(value="select * from t_users where username = ?",nativeQuery=true)
List<Users> queryUserByNameUseSQL(String name);
@Query(value="select * from t_users where username like ?",nativeQuery=true)
List<Users> queryUserByLikeNameUseSQL(String name);
@Query(value="select * from t_users where username = ? and userage >= ?",nativeQuery=true)
List<Users> queryUserByNameAndAgeUseSQL(String name,Integer age);
//也可以进行更新数据
@Query("update Users set userage = ? where userid = ?")
@Modifying //@Modifying当前语句是一个更新语句
void updateUserAgeById(Integer age,Integer id);
}
分页查询
Pageable是Spring Data提供出来进行分页查询参数输入的接口,里面主要定义多个与页面设定的方法:
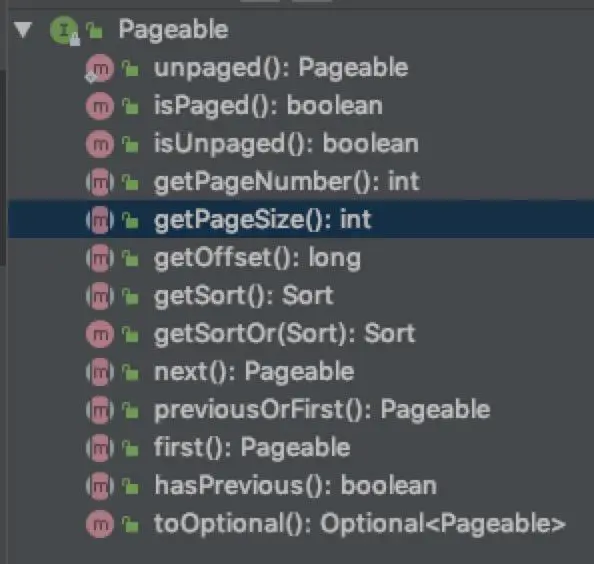
PageRequest
**Pageable实现有很多,最常用的是PageRequest**:
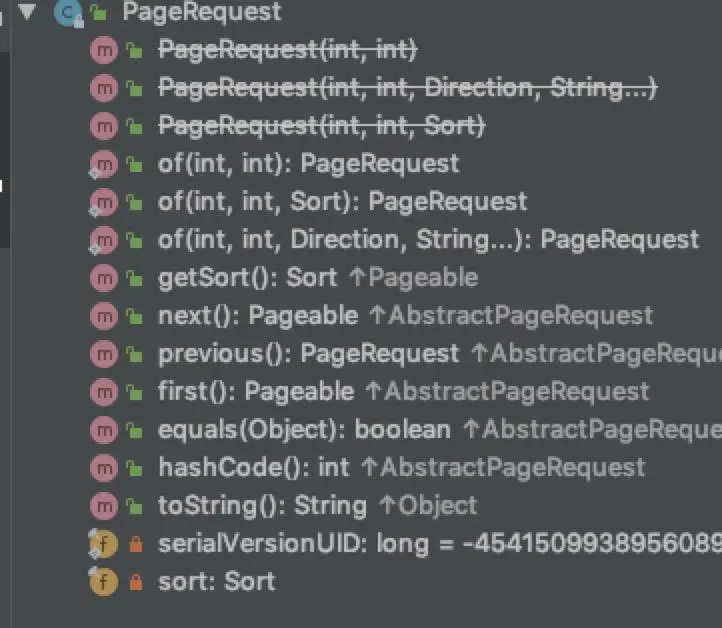
PageRequest废弃了原本的new方式来构建分页参数,建议使用类中提供的of(...)静态方法来创建相关的分页参数实体。
of(...)分页查询中允许带上排序字段以及排序方向两个参数,在源码中,这两个共同构建成了Sort实体。这是很多业务中需要使用上的,首先需要讲内容进行排序,然后再分页列出。
分页查询中,next()、previous()返回的分别是下一页、上一页的分页参数实体。
分页查询结果
除了支持常用的集合List、Set等查询结果集作为分页查询结果(返回值),Spring Data还有以下几种结果:
Page<T>Slice<T>List<T>Set<T>
limit查询
在Mysql中,我们需要获得前N个结果,使用limit关键字。
在Spring Data中可以使用:
topfirst
来进行限定最终的结果数,在top、first关键字后面可以加上数字表示最大结果大小,默认值为1:
User findFirstByUsername(String username)List<Article> findFirst10Bytitle(String title)
当然,这个是支持使用Pageable、Sort的。
流式查询结果
Spring Data支持使用Stram<T>流式API使用。
@Query("select u from User u")
Stream<User> findAllByCustomQueryAndStream();
Stream<User> readAllByFirstnameNotNull();
@Query("select u from User u")
Stream<User> streamAllPaged(Pageable pageable);一般在try-with-resources中使用:
try (Stream<User> stream = repository.findAllByCustomQueryAndStream()) {
stream.forEach(…);
}


