目录
- Hadoop概述
- HDFS
- MapReduce
- Hadoop安装
- Hadoop代码Demo
参考资料
Hadoop概述
Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会开发和维护。
Hadoop 为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集,并且支持在单台计算机到几千台计算机之间进行扩展。
hadoop的分布式架构包括两部分
- 一个是分布式文件系统
HDFS,负责分布储存数据 - 另一个是分布式计算框,就是
MapReduce,负责对数据进行映射、规约处理,并汇总处理结果
Hadoop 的作用非常简单,就是在多计算机集群环境中营造一个统一而稳定的存储和计算环境,并能为其他分布式应用服务提供平台支持。也就是说, Hadoop 在某种程度上将多台计算机组织成了一台计算机(做同一件事),那么 HDFS 就相当于这台计算机的硬盘,而 MapReduce 就是这台计算机的 CPU 控制器。
HDFS
HDFS 的存储单位是块 (Block) ,一个文件可能会被分为多个块储存在物理存储器中。因此 HDFS 往往会按照设定者的要求把数据块复制 n 份并存储在不同的数据节点 (储存数据的服务器) 上,如果一个数据节点发生故障数据也不会丢失。
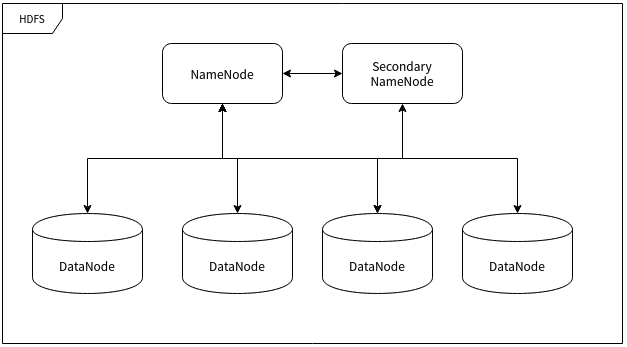
- 命名节点 (NameNode)
命名节点 (NameNode) 是用于指挥其它节点存储的节点。任何一个”文件系统”(File System, FS) 都需要具备根据文件路径映射到文件的功能,命名节点就是用于储存这些映射信息并提供映射服务的计算机,在整个 HDFS 系统中扮演”管理员”的角色,因此一个 HDFS 集群中只有一个命名节点。
- 数据节点 (DataNode)
数据节点 (DataNode) 使用来储存数据块的节点。当一个文件被命名节点承认并分块之后将会被储存到被分配的数据节点中去。数据节点具有储存数据、读写数据的功能,其中存储的数据块比较类似于硬盘中的”扇区”概念,是 HDFS 存储的基本单位。
- 副命名节点 (Secondary NameNode)
副命名节点 (Secondary NameNode) 别名”次命名节点”,是命名节点的”秘书”。这个形容很贴切,因为它并不能代替命名节点的工作,无论命名节点是否有能力继续工作。它主要负责分摊命名节点的压力、备份命名节点的状态并执行一些管理工作,如果命名节点要求它这样做的话。如果命名节点坏掉了,它也可以提供备份数据以恢复命名节点。副命名节点可以有多个。
数据访问时:
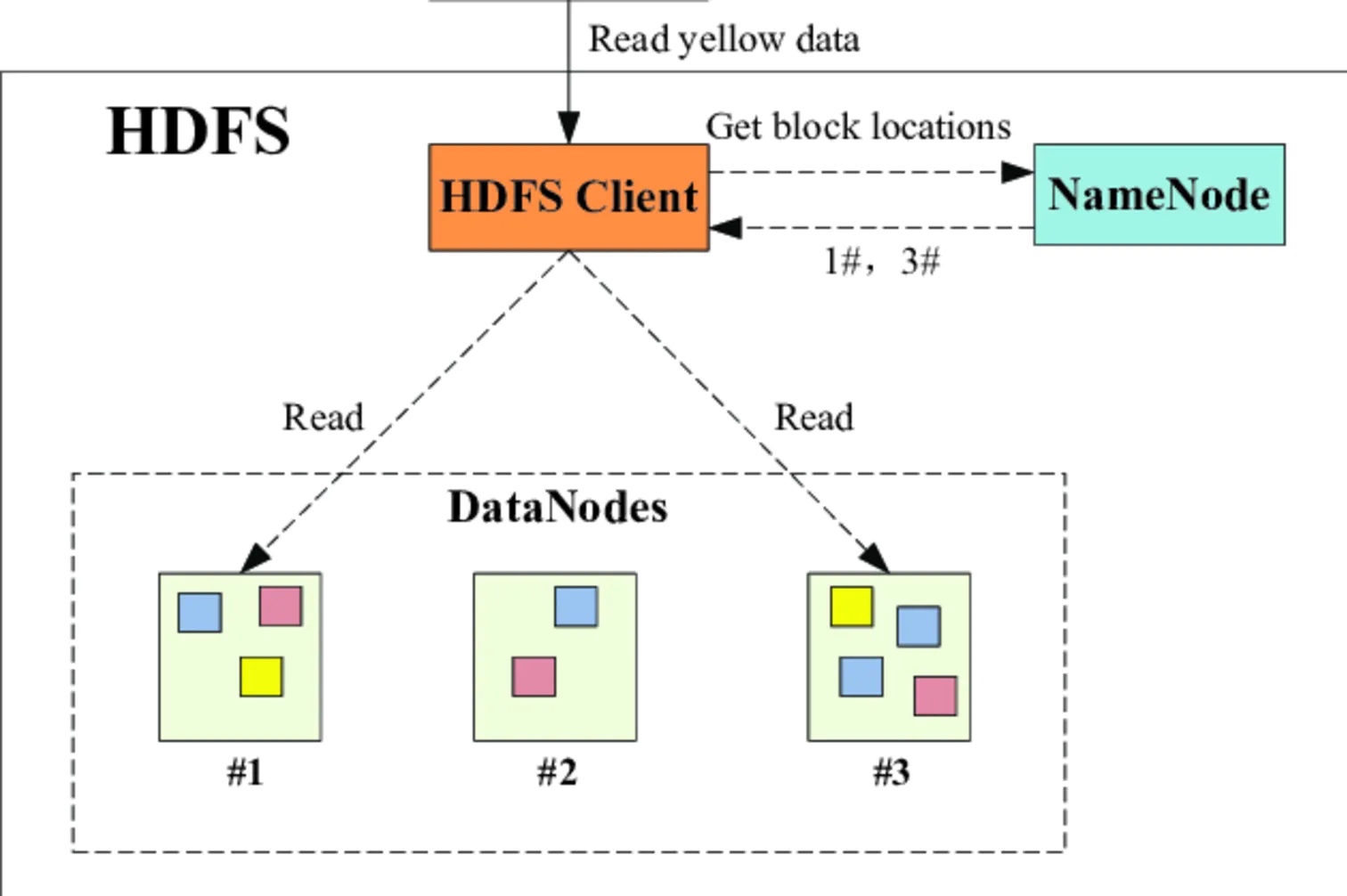
HDFS使用的一些命令:
# 显示根目录 / 下的文件和子目录,绝对路径
hadoop fs -ls /
# 新建文件夹,绝对路径
hadoop fs -mkdir /hello
# 上传文件
hadoop fs -put hello.txt /hello/
# 下载文件
hadoop fs -get /hello/hello.txt
# 输出文件内容
hadoop fs -cat /hello/hello.txtMapReduce
概述
MapReduce 的含义就像它的名字一样浅显:Map 和 Reduce (映射和规约) 。
简单来说就是分而治之。将一个大的数据计算任务,分摊到不同的计算集群去计算,最后灾汇总合并得到结果。对比单节点/单集群的计算速度,会快很多。
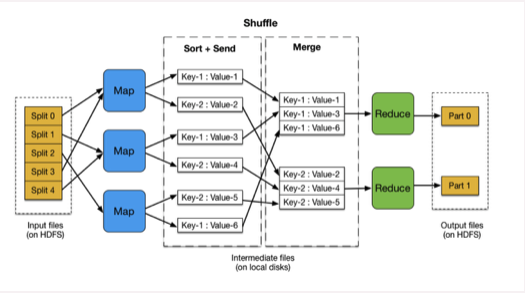
Input:输入文件的存储位置。可以是hdfs文件位置,也可以是本地文件位置
Map阶段:自己编写映射逻辑,将输入数据映射到一组中间格式的键值对集合。
Shuffle阶段:是我们不需要编写的模块,但却是十分关键的模块。Shuffle 阶段需要从所有 map主机上把相同的 key 的 key value对组合在一起,传给 reduce主机, 作为输入进入 reduce函数里。
Reduce阶段:自己编写合并逻辑,将与一个key关联的一组中间数值集归约(reduce)为一个更小的数值集。
Final result: 最终结果存储在hdfs
接口说明
Map/Reduce框架运转在<key, value> 键值对上,也就是说, 框架把作业的输入看为是一组<key, value> 键值对,同样也产出一组 <key, value> 键值对做为作业的输出,这两组键值对的类型可能不同。
框架需要对key和value的类(classes)进行序列化操作, 因此,这些类需要实现 Writable接口。 另外,为了方便框架执行排序操作,key类必须实现 WritableComparable接口。
一个Map/Reduce 作业的输入和输出类型如下所示:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
- Mapper接口
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Mapper() {
}
protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
/**需要用户重写的方法*/
protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
context.write(key, value);
}
protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
try {
while(context.nextKeyValue()) {
this.map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
this.cleanup(context);
}
}
public abstract class Context implements MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Context() {
}
}
}- Reduce
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Reducer() {
}
protected void setup(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
/**需要用户重写的方法*/
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
Iterator var4 = values.iterator();
while(var4.hasNext()) {
VALUEIN value = var4.next();
context.write(key, value);
}
}
protected void cleanup(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
public void run(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
try {
while(context.nextKey()) {
this.reduce(context.getCurrentKey(), context.getValues(), context);
Iterator<VALUEIN> iter = context.getValues().iterator();
if (iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator)iter).resetBackupStore();
}
}
} finally {
this.cleanup(context);
}
}
public abstract class Context implements ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Context() {
}
}
}
Hadoop安装
这里是一个是用Docker快速启动部署Hadoop的方式
$ git clone https://github.com/big-data-europe/docker-hadoop.git
$ cd docker-hadoop
$ docker-compose up
$ docker-compose stop$ docker exec -it namenode bash
$ mkdir input
$ echo "Hello World" >input/f1.txt
$ echo "Hello Docker" >input/f2.txt
$ hadoop fs -mkdir -p input
$ hdfs dfs -put ./input/* input
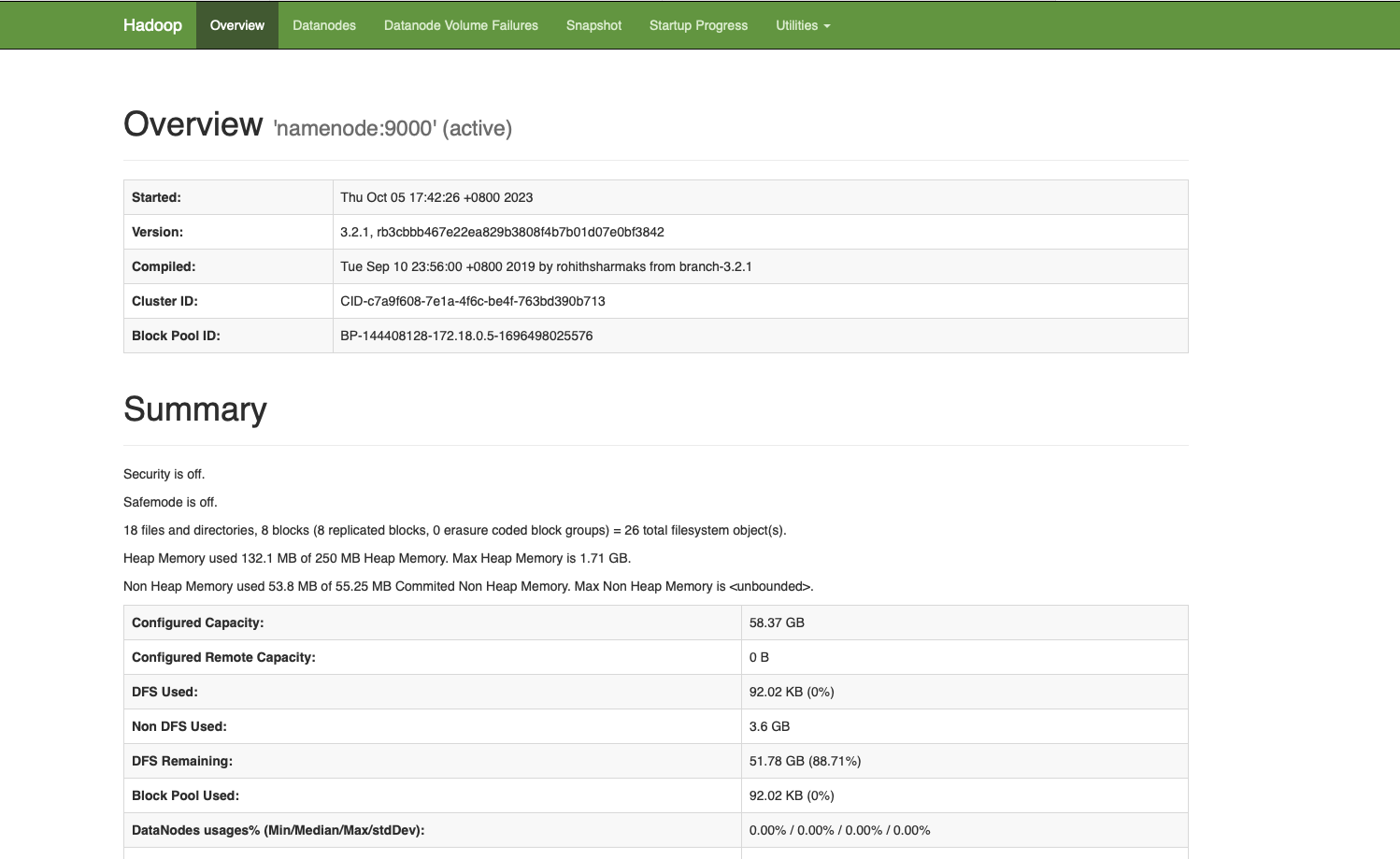
$ hadoop fs -df -h /
Filesystem Size Used Available Use%
hdfs://namenode:9000 58.4 G 100 K 32.4 G 0%访问localhost:9870也可以看到web页面
Hadoop代码Demo
这里以官网的WordCount进行说明
- 依赖
<dependencies>
<!-- 导入hadoop依赖环境 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>- Mapper
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
}- Reducer
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}- Job
import com.jason.mapper.WordCountMapper;
import com.jason.reduce.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}


