目录
- 数据流模型和处理方式
- 窗口
- DataFlow模型
- Flink
参考
数据流和处理方式
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
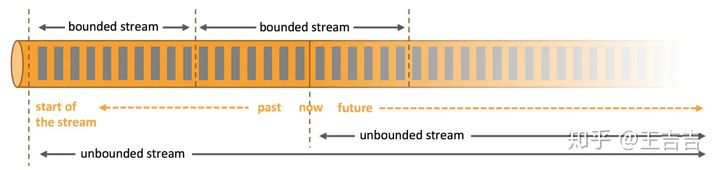
- 无界数据流
顾名思义,无界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断的产生新的数据,即数据没有时间边界。无界数据流需要持续不断地处理,处理这种有界数据流的方式也被称之为流处理。
- 有界数据流
相对而言,有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等。处理这种有界数据流的方式也被称之为批处理。很多批处理都是使用Hadoop框架。
窗口
窗口是无限流处理中的一个概念,它将流拆分成一个个的“桶”,我们再基于这些桶的数据做计算。
流处理中的聚合操作(counts,sums等等)不同于批处理,因为数据流是无限,无法在其上应用聚合,所以通过限定窗口(window)的范围,来进行流的聚合操作。例如:5分钟的数据计数,或者计算100个元素的总和等等。
窗口可以由时间驱动 (every 30 seconds) 或者数据驱动(every 100 elements)。如:滚动窗口tumbling windows(无叠加),滑动窗口sliding windows(有叠加),以及会话窗口session windows(被无事件活动的间隔隔开)

DataFlow模型
Flink的流模型参考了Dataflow模型,它是一套准确可靠的关于流处理的解决方案。在Dataflow模型提出以前,流处理常被认为是一种不可靠但低延迟的处理方式,需要配合类似于MapReduce的准确但高延迟的批处理框架才能得到一个可靠的结果(Lambda架构)。
Dataflow由三个部分组成:
- Source(数据源):负责获取输入数据。
- Transformation(数据处理):对数据进行处理加工,通常对应着多个算子。
- Sink(数据汇):负责输出数据。
Flink程序执行时,由流和转换操作映射到streaming dataflows,每个数据流有1个或多个 source,有一个或多个sink。
其中transformatiion的算子非常丰富,常见的如下:
| 算子 | 实现 |
|---|---|
| map: | 无状态算子。输入一个元素,然后返回一个元素 |
| flatmap | 无状态算子。 输入一个元素,可以返回零个,一个或者多个元素 |
| filter | 对流进行过滤,符合条件的数据会被留下 |
还有很多其他的算子,参考这篇文档:硬核!一文学完Flink流计算常用算子(Flink算子大全)
Flink
概述
全球有越来越多的公司在使用Flink, 国内主流互联网公司都在大规模使用Flink作为企业分布式大数据处理引擎。
Flink之所以如此受到青睐,除了其提供高吞吐、低延迟和Exactly-once一致性语义支持外,更重要的是它能以流数据的处理方式来处理批数据,可以真正意义上实现批流处理的统一。
架构
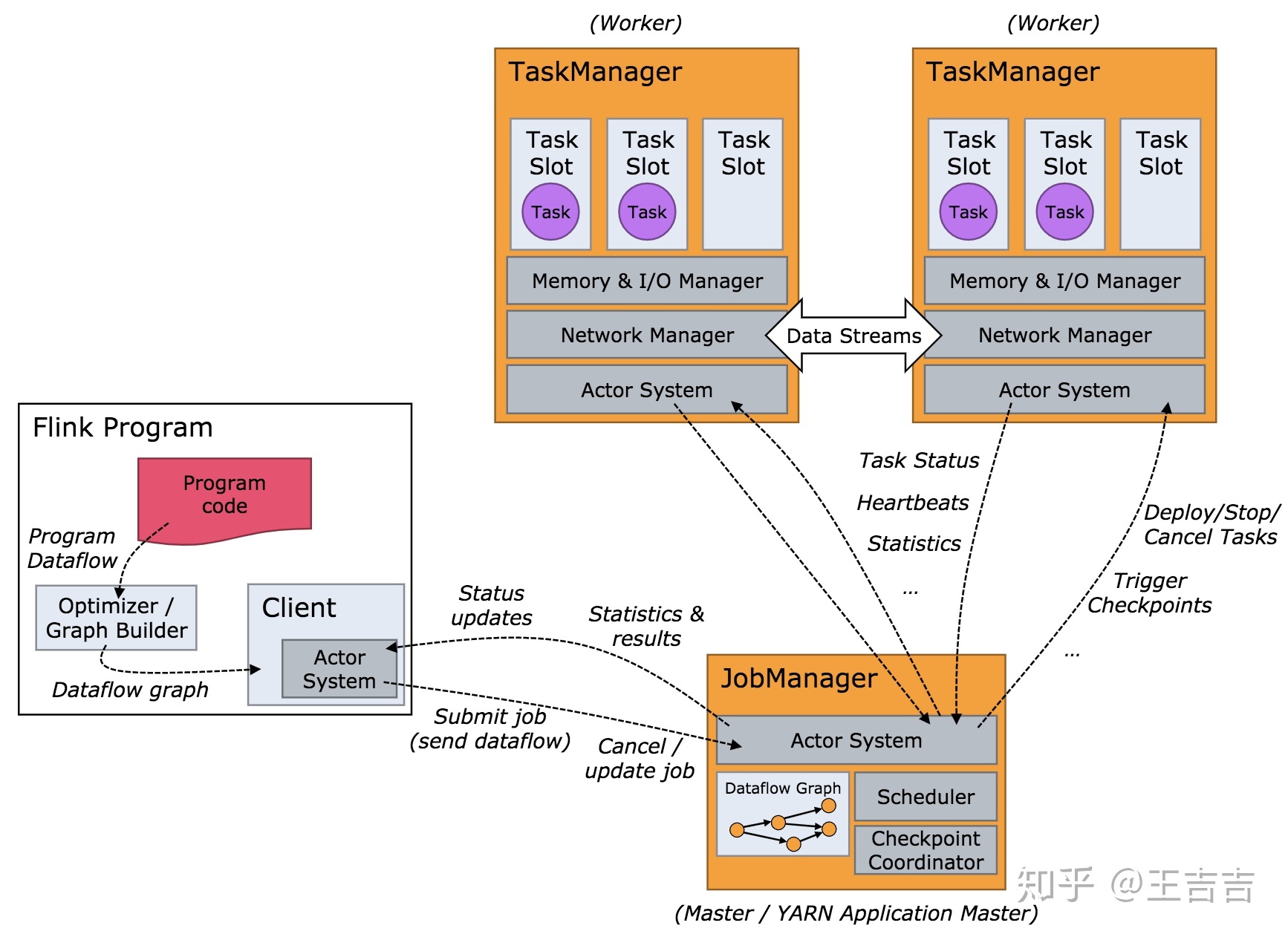
JobManager负责协调Flink程序的执行,包括:任务的调度、任务运行完成与失败的处理,协调检查点与恢复等,主要包括以下项职能:
- ResourceManager:负责资源分配,管理任务slot, 这个是flink集群资源管理的单位。
- Dispatcher:提供应用程序提交的REST接口,对每一个提交的作业启动JobMaster,并运行Flink WebUI提供作业执行的信息。
- JobMaster:负责单个作业图(JobGraph)的执行。一个集群可以同时运行多个作业,每个作业都有自己的JobMaster。
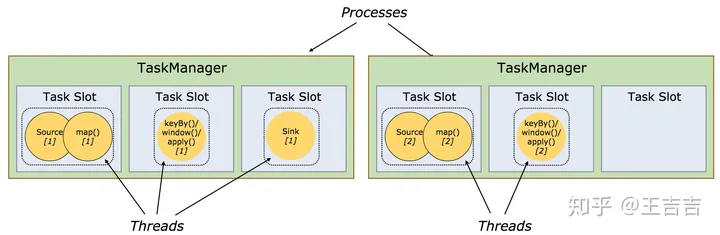
TaskManager负责执行dataflow中的任务,缓存和交换数据流。一个作业执行时,至少要有一个TaskManager,TaskManager中资源调度的最小单位是slot。一个TaskManager中的slot数表示的是该TaskManager中可以并行执行任务的数量
每个worker(TaskManager)都是一个JVM进程,可以执行一个或多个子任务(subtask)。任务槽(task slot)就是为了控制一个worker能同时运行多少个任务的(至少一个)。
每个任务槽(task slot)代表TaskManager一个设定的资源子集。比如, 一个TaskManager有3个槽,会将其管理的1/3的内存分给每个槽位。将资源分成不同的槽位意味着一个子任务(subtask)不会跟其他作业的子任务竞争资源,而是会拥有一定量的保留资源。需要注意的是,这里不涉及CPU隔离,目前任务槽仅仅分割task管理的内存。
为了适配任务槽(task slot)的数量,用户可以定义子任务(subtask)是如何隔离的。如果每个TaskManager有一个槽,就意味着task组运行在不同的JVM里。如果每个TaskManager有多个槽意味着多个任务(subtask)共享同一个JVM。任务在同一个JVM运行可以共享TCP链接和心跳信息。它们可以共享数据集和数据结构,因此可以减少每个任务的开销。
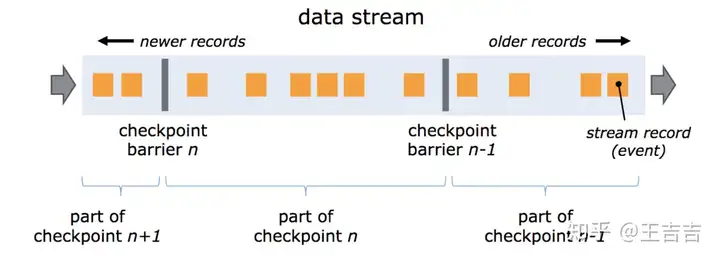
检查点
基于检查点的容错是Flink的关键特征之一,正式基于这样的设计,Flink才可以统一批流处理。
Flink 容错机制的核心就是持续创建分布式数据流及其状态的一致快照。这些快照在系统遇到故障时,充当可以回退的一致性检查点(checkpoint)
分布式快照引入了数据栅栏(barrier)的概念,barrier 被插入到数据流中,作为数据流的一部分和数据一起向下流动。Barrier 不会干扰正常数据,数据流严格有序。一个 barrier 把数据流分割成两部分:一部分进入到当前快照,另一部分进入下一个快照。每一个 barrier 都带有快照 ID,并且 barrier 之前的数据都进入了此快照。Barrier 不会干扰数据流处理,所以非常轻量。多个不同快照的多个 barrier 会在流中同时出现,即多个快照可能同时创建。
Flink代码Demo
- 依赖
<properties>
<flink.version>1.7.1</flink.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependencies>
<!-- Apache Flink dependencies -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<!-- This dependency is required to actually execute jobs. It is currently pulled in by
flink-streaming-java, but we explicitly depend on it to safeguard against future changes. -->
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>- WordCount Demo
public class WordCount {
public static void main(String[] args) throws Exception {
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setNumberOfExecutionRetries(3); //整个任务如果失败 重试3次
//我失败重试3次 每次之间 间隔5秒
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.seconds(5)));
// get input data
DataSet<String> text = env.fromElements(
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,"
);
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new LineSplitter())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0) //
.sum(1).setParallelism(5);
// execute and print result
counts.print();
}
/**
* Implements the string tokenizer that splits sentences into words as a user-defined
* FlatMapFunction. The function takes a line (String) and splits it into
* multiple pairs in the form of "(word,1)" (Tuple2<String, Integer>).
*/
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) { //"hello flink"
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}



